Вычислительная устойчивость
Из Википедии — свободной энциклопедии
В вычислительной математике вычислительная устойчивость является обычно желательным свойством численных алгоритмов.
Точное определение устойчивости зависит от контекста. Один из них — численная линейная алгебра, другой — алгоритмы решения обыкновенных уравнений и дифференциальных уравнений в частных производных с помощью дискретного приближения.
В численной линейной алгебре основной проблемой являются нестабильности, вызванные близостью к различным особенностям(singularity), таким как очень малые или почти совпадающие собственные значения.
С другой стороны, в численных алгоритмах для дифференциальных уравнений проблема заключается в увеличении ошибок округления и/или изначально небольших флуктуаций в исходных данных, которые могут привести к значительному отклонению окончательного ответа от точного решения.
Некоторые численные алгоритмы могут ослаблять небольшие отклонения (ошибки) во входных данных; другие могут увеличить такие ошибки. Расчеты, которые, как можно доказать, не увеличивают ошибки аппроксимации, называются вычислительно устойчивыми. Одна из распространенных задач численного анализа — попытаться выбрать надежные алгоритмы, то есть не дать сильно отличающийся результат при очень небольшом изменении входных данных.
Противоположным явлением является неустойчивость. Как правило, алгоритм включает в себя приближенный метод, и в некоторых случаях можно доказать, что алгоритм будет приближаться к правильному решению в некотором пределе (при использовании на самом деле действительных чисел, а не чисел с плавающей запятой).
Даже в этом случае нет гарантии, что он будет сходиться к правильному решению, потому что ошибки округления или усечения с плавающей точкой могут расти, а не уменьшаться, что приведет к экспоненциальному росту отклонения от точного решения. [1]
Быстрая, экономная, устойчивая…
На вопрос, можно ли добиться выполнения одновременно всех трёх условий, большинство скажет «вряд ли». Википедия о таких алгоритмах не знает. Среди программистов ходят слухи, что вроде бы, что-то такое существует. Некоторые говорят, что есть «устойчивая быстрая сортировка» — но у той реализации, которую я видел, сложность была всё те же O(N*(log(N) 2 ) (по таймеру). И только в одном обсуждении на StackOverflow дали ссылку на статью B-C. Huang и M. A. Langston, Fast Stable Merging and Sorting in Constant Extra Space (1989-1992), в которой описан алгоритм со всеми тремя свойствами.
Авторы говорят, что их алгоритм не первый, и ссылаются на работу L. Trabb Pardo, Stable sorting and merging with optimal space and time bounds 1974 года. Это около 80 страниц отсканированного текста, и разобраться в нём я не пытался.
Сразу скажу для тех, кто попробует разобраться в статье Huang и Langston, что реализовать алгоритм в том виде, в каком он там описан, мне не удалось. Приём, который они используют в пункте 4.3, не работает, потому что утверждение «That is, it directly follows that the head of the rightmost block of a second-sublist series will temporarily have a key strictly greater than that of the record to its immediate right» верно не всегда. К счастью, в некоторых более поздних работах удалось найти способ, позволяющий обойти эту неприятность, и теперь я могу сказать, что алгоритм, удовлетворяющий всем трём условиям, действительно существует.
Основные операции
Ищем буфер для обмена.
Сначала немного терминологии.
Про элементы, для которых функция сравнения выдала результат, что они равны, будем говорить, что «у них совпадают ключи», хотя физически никаких ключей может не существовать. Соответственно, можно определить число различных ключей в массиве и элементы с различными ключами.
Два состояния массива будем называть эквивалентными, если элементы с одинаковыми ключами в них находятся в одинаковом порядке. Главная проблема устойчивых in-place сортировок — не потерять эту эквивалентность, или всегда уметь её восстановить.
Пусть длина массива равна N. Если N 2 обменов. Поскольку NKeys у нас порядка 2*sqrt(N), то пока мы за границу не вышли.
Теперь у нас есть два варианта. Либо мы нашли заказанные K+S ключей, либо не нашли. Эти случаи обрабатываются слегка по-разному. Кроме того, есть случай, когда число различных ключей меньше 4 — для него тоже есть своя обработка.
Случай A. Различных ключей много.
У нас есть K+S различных ключей, собранных в начале массива. Первые K из них мы объявим «ключами для маркировки фрагментов» и пока трогать не будем. Остальные S будут буфером для слияния. Все оставшиеся элементы исходного массива — «данными», сейчас они лежат в конце массива.
A.1. Этап классической сортировки слиянием.
Напишем ещё две функции. Одна будет называться MergeLeft, другая MergeRight. Им подаются на вход фрагменты массивов, состоящие из трёх частей. В случае MergeLeft это буфер длины P, отсортированный фрагмент длины Q и отсортированный фрагмент длины R, где S≥R. Функция должна слить второй и третий фрагменты, положить результат в начало, а элементы буфера в произвольном порядке в конец данного фрагмента. Функция MergeRight работает зеркально — на входе у неё два отсортированных фрагмента, а за ними буфер, а на выходе — наоборот, буфер, а за ним отсортированный фрагмент. Выглядит это примерно так: 
Сложность обеих функций не превосходит Q+R — как по сравнениям, так и по обменам.
Пользуясь функцией MergeLeft, мы можем отсортировать данные сначала по парам, потом по четвёркам,… вплоть до фрагментов длины S (напомню, что S — степень двойки). Каждый раз при сортировке M элементов мы используем кусочек буфера длины M/2, который в результате уезжает в правую часть массива. На этапе сортировки пар мы воспользуемся кусочком буфера длины 2, так что в итоге к моменту, когда отсортированные куски будут длины S, массив данных у нас окажется прижатым влево, а S элементов буфера будут справа. Теперь мы можем использовать MergeRight, отсортировать фрагменты длиной 2*S, и заодно, вернуть буфер в начало.
A.2. Этап блочной сортировки.
Сейчас у нас отсортированы фрагменты длиной G=2*S. Мы будем сливать их попарно, потом ещё раз попарно и т.д., пока не достигнем размера всего массива данных. Для этого у нас есть буфер длиной S и массив с ключами длиной K, где K ≤ L/S (L — полная длина массива данных).
Итак, цикл «пока G ≤ L».
Мы хотим слить два подряд идущих фрагмента длины G, причём непосредственно перед ними находится буфер длины S (G и S — степени двойки). Делим наши фрагменты на блоки длины S. Пусть их получилось K1. Второй фрагмент в самом конце массива мог иметь длину меньше G, и после деления от него может остаться неполный блок, его мы тоже посчитаем (хотя двигать не будем). Возьмём первые K1 ключей (они лежат в начале исходного массива), отсортируем их (например, вставками) и запомним индекс ключа с номером G/S (сейчас он равен G/S, но потом будет меняться) — назовём его midkey. Каждому ключу соответствует свой блок. Мы их используем, во-первых, чтобы различить первый и второй сливаемые фрагменты, а во-вторых, чтобы поддержать порядок блоков с одинаковыми элементами. Потому что сейчас мы их будем перемешивать как попало.
Отсортируем блоки. Порядок будет определяться первыми элементами, а если они равны — то соответствующими этим блокам ключами. Единственная сортировка, которой мы можем здесь воспользоваться — это сортировка выбором минимального элемента, поскольку она требует не более K1 обмена (и K1 2 /2 сравнений): обмен двух блоков это дорогая процедура, но, поскольку S это примерно sqrt(N), то весь этап сортировки укладывается в O(N) операций. Когда мы переставляем два блока, то переставим и соответствующие им ключи, не забывая следить за ключом midkey. Неполный блок (если он есть) при этой сортировке мы не трогаем!
Блоки, ранее принадлежавшие первому фрагменту, мы будем обозначать буквой A, а блоки, принадлежавшие второму — буквой B. При нашей сортировке порядок блоков, соответствовавших каждому фрагменту,
сохранился.
Неполный блок всегда принадлежит фрагменту B. Просмотрим блоки, идущие перед ним, чтобы узнать, перед каким блоком его следовало бы вставить. Возможно, что его придётся вставить в самое начало, или оставить на месте — в алгоритме на эти случаи нужно обратить особое внимание. На следующем этапе трогать блоки, которые следовало бы подвинуть (все они из фрагмента A), мы пока не будем.
Чтобы обработать очередной блок, нам придётся написать ещё одну функцию SmartMergeLeft (и она не последняя!). На вход ей, как и MergeLeft, подаются буфер и два фрагмента, причём порядок этих фрагментов может быть неправильным (тогда при слиянии надо будет в случае равных элементов брать элемент из второго фрагмента). Функция должна переставлять элементы в начало только до тех пор, пока оба фрагмента непусты. Как только один из них кончится, она должна перенести оставшиеся элементы другого фрагмента в конец (если второй фрагмент кончился раньше), сообщить их число, и то, в каком фрагменте они были.
Примерно так:
В первом случае сначала кончились элементы из B, и в конце остались последние элементы из A, а во втором — наоборот.
Пользуясь этой функцией, мы легко можем продвинуться на один блок. Если тип следующего блока такой же, как у последних необработанных элементов, мы меняем их с буфером, и говорим, что T=0, а необработанным является новый блок (ситуация такая же, как в начале). Если типы разные, вызываем SmartMergeLeft, и она всё делает сама — элементы, которые останутся в конце блока, и будут необработанными.
Так, перебирая блоки, мы дойдём либо до конца, либо до того места, где должен стоять неполный блок из конца фрагмента B. Здесь у нас несколько вариантов.
Либо последние оставшиеся необработанные элементы — из фрагмента B. Тогда последний из этих элементов меньше, чем первый элемент из следующего за ним блока A (если такой есть), и мы можем смело обменять необработанные элементы с буфером.
Либо эти элементы из фрагмента A. Тогда мы просто виртуально приклеиваем их к следующим за ними блокам (опять же, если они есть).
В обоих случаях получаем одну и ту же ситуацию — буфер, за ним элементы из фрагмента A, потом — не более, чем S элементов из фрагмента B. Готовая ситуация для функции MergeLeft. Вызываем её — и фрагменты слиты, причём буфер оказался после них.
Проходим этой процедурой по всем парам фрагментов длины G, пока не дойдём до конца массива данных. После чего сдвигаем все данные вправо на S элементов (возвращая буфер в начало), и удваиваем значение S.
Конец цикла.
A.3. Завершение.
У нас получился отсортированный массив данных, перед которыми идут в случайном порядке найденные в начале ключи. Отсортируем их (опять вставками), и нам останется слить два отсортированных фрагмента без использования дополнительного буфера. На этот раз нас спасёт то, что один из них очень короткий.
Функция MergeWithoutBuffer получает на вход два отсортированных фрагмента длины P и Q. Предположим, что P 1/3 (напомним, что M — число различных ключей в массиве). Размером блока у нас будет S=2*G/K1.
Сортируем ключи и блоки так же, как в A.2. Для этого буфера не нужно.
Теперь нам нужно пройтись по массиву и слить блоки. Напишем функцию SmartMergeWithoutBuffer, являющуюся гибридом MergeWithoutBuffer и SmartMergeLeft. В ней предполагается, что первый фрагмент короче второго. Она работает так же, как MergeWithoutBuffer, но учитывает, что порядок фрагментов мог быть неправильным, а кроме того, сообщает, сколько элементов и из какого фрагмента остались в конце массива. Вызывая эту функцию вместо SmartMergeLeft, а функцию MergeWithoutBuffer — вместо MergeLeft в конце, получим слитые фрагменты.
Казалось бы, здесь мы и проиграли — максимальная длина блока в худшем случае (K=4,G=N/2) равна N/4, а значит, функции SmartMergeWithoutBuffer может потребоваться O(N^2) операций. Но нас спасает то, что число различных ключей в массиве мало — и можно показать, что сложность SmartMergeWithoutBuffer не превосходит P*m+Q, где m — число различных ключей в первом фрагменте. А поскольку сумма числа различных ключей по всем K/2 блокам фрагмента длины G (сделайте глубокий вдох и перечитайте — проще я сформулировать не могу) не превосходит K/2+M, то на слияние двух фрагментов длины G потратится не более O(G) операций.
B.3. Завершение.
Этот этап не отличается от A.3.
Случай C. Различных ключей не больше трёх.
Здесь мы пишем обычную сортировку слиянием (без рекурсии — сортируем по 2, потом по 4 элемента и т.д.), а для слияния фрагментов используем MergeWithoutBuffers. Поскольку различных ключей в массиве мало, её сложность будет линейной от длины сливаемых фрагментов, а значит, общая сложность — O(N*log(N)).
Реализация и выводы.
Реализация получилась громоздкой — почти 400 строк на C++ (фактически, он написан на C — надо только перенести описания переменных в начало функций). Скорость работы сильно различается для случаев A и B. Хуже всего ситуация, когда различных ключей много, но чуть-чуть меньше, чем нужно для перехода к случаю A — в этой ситуации алгоритм работает медленнее, чем в случае A, примерно в 3 раза. Тем не менее, оценка сложности N*log(N) сохраняется.
На больших массивах (примерно от 10 миллионов) алгоритм почти всегда (кроме случаев совсем уж маленького числа различных ключей) обыгрывает InPlaceStableSort (тот, который за O(N*log(N) 2 )). Но тягаться с std::stable_sort он не в силах: хоть немного памяти найдётся всегда, а в этом случае std::stable_sort быстро переключается на обычный MergeSort, и легко и непринуждённо обгоняет всех, включая quicksort :). Так что реализованный алгоритм имеет лишь теоретическое значение.
Но всё-таки, он существует 🙂
UPDATE: Этап B2 можно сильно ускорить. Пока число G достаточно мало, может случиться так, что (K/2)^2>=2*G. В этом случае мы можем разделить множество ключей пополам, и половину использовать в качестве буфера обмена (а вторую половину — как ключи), и сливать фрагменты с помощью более быстрого метода из A2. А на обмены без буфера перейти в самом конце, когда G приблизится к размеру массива.
Чем больше у нас разных ключей, тем дольше работает слияние без буфера, но и тем дольше мы можем обойтись без него.
Эксперименты показывают, что в самом неблагоприятном случае алгоритму требуется не больше, чем 1.61*N*log2N сравнений и 2.12*N*log2N обменов (при N≤1000000, на случайных данных с заранее заданным числом различных ключей).
Устойчивость и неустойчивость алгоритмов
Поскольку в системе чисел с плавающей точкой нарушаются основные законы арифметики, то при реализации алгоритмов на ЭВМ большую роль играет порядок организации вычислений, а именно: результат вычислений может сильно зависеть от порядка.
Алгоритм, в котором погрешность, допущенная в начальных данных или допускаемая при вычислениях, с каждым шагом не увеличивается или увеличивается незначительно, называется устойчивым. В противном случае, если погрешность существенно увеличивается от шага к шагу, алгоритм называется неустойчивым.
Чаще всего неустойчивость алгоритма связана с итерационными процессами, когда результат получается посредством последовательности итераций, причем на каждой итерации в качестве исходных данных используются значения, полученные на предыдущей итерации. Существуют неустойчивые алгоритмы, не связанные с итерационными процессами.
Пример. Известно, что ряд Тейлора для функции 

сходится для всех  . Рассмотрим один из возможных алгоритмов суммирования этого ряда:
. Рассмотрим один из возможных алгоритмов суммирования этого ряда:
Шаг 1. Задать . 
 ;
; 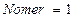 .
.
Шаг 2. 
Шаг 3. Если 
 =
=  ,
,
иначе = ,  ,
,
Проверка на шаге 3 учитывает то обстоятельство, что машинная арифметика является приближенной. Выражение будет иметь то же значение, что и , если число достаточно мало. Если провести вычисления по этому алгоритму для различных значений  , получим числа, представленные в табл.1. Для
, получим числа, представленные в табл.1. Для  эти числа соответствуют истинным значениям, но для
эти числа соответствуют истинным значениям, но для  картина неудовлетворительная: в некоторых случаях неверны даже знаки результатов. Это говорит о неустойчивости рассмотренного алгоритма.
картина неудовлетворительная: в некоторых случаях неверны даже знаки результатов. Это говорит о неустойчивости рассмотренного алгоритма.
Пример. Необходимо вычислить 
При вычислении интеграла по частям получим:
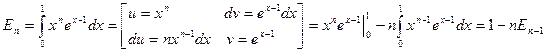 ,
,
т.е.  . (10)
. (10)
Предположим, что вычисления проводятся в системе чисел с плавающей точкой, для которой  :
:
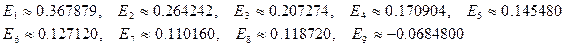
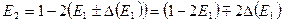 ,
,
т.е. ошибка в  ―
―  . Аналогично, ошибка в
. Аналогично, ошибка в  ―
― 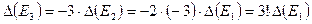 и т.д. Ошибка в
и т.д. Ошибка в  ―
―  . Истинное значение
. Истинное значение  . Таким образом, возникающая вследствие неустойчивости алгоритма ошибка – абсолютная погрешность – при вычислении значительно больше искомого значения , что не даст возможности получить ни одного верного знака в записи числа , что и наблюдается при вычислении по абсолютно точной с точки зрения обычной арифметики формуле (10).
. Таким образом, возникающая вследствие неустойчивости алгоритма ошибка – абсолютная погрешность – при вычислении значительно больше искомого значения , что не даст возможности получить ни одного верного знака в записи числа , что и наблюдается при вычислении по абсолютно точной с точки зрения обычной арифметики формуле (10).
Преобразуем формулу (10) эквивалентным образом:
 . (20)
. (20)
Теперь на каждом шаге вычислений ошибка в  умножается на множитель
умножается на множитель 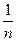 . Таким образом, если начать вычисления с некоторого для
. Таким образом, если начать вычисления с некоторого для  и проводить вычисления в обратном порядке, то любая начальная ошибка или промежуточные ошибки округлений будут уменьшаться на каждом шаге, что говорит об устойчивости алгоритма, отвечающего (20).
и проводить вычисления в обратном порядке, то любая начальная ошибка или промежуточные ошибки округлений будут уменьшаться на каждом шаге, что говорит об устойчивости алгоритма, отвечающего (20).
Оценим значения в общем виде. Поскольку при 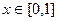 :
:  , то на сегменте
, то на сегменте  :
: 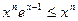 , а значит:
, а значит:
 , (25)
, (25)
а это значит, что  .
.
Таким образом, если в качестве стартового значения для вычислений в соответствии с формулой (20) взять, например,  , значение которого положить равным нулю
, значение которого положить равным нулю
 , (30)
, (30)
то начальная ошибка, допущенная при этом в (30), не превосходит в соответствии с (25) 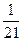 . Эта ошибка умножится на
. Эта ошибка умножится на  при вычислении
при вычислении  , так что ошибка в —
, так что ошибка в —  .
.
Вычисления, проведенные по ормуле (20), приведут к следующему результату:
 ,
,
что говорит об устойчивости алгоритма (20).
Чувствительность задачи
Очевидно, что при решении произвольной реальной задачи в общем случае невозможно получить точное значение искомого численного результата. Существование неустранимой погрешности в математической модели объекта или процесса, фигурирующего в задаче, погрешности входных данных, многие из которых в реальных условиях получены экспериментально, погрешность метода, используемого для решения, и вычислительная, погрешности, возникающие при каких-либо дополнительных воздействиях на объект, которые часто трактуются как возмущения входных данных, приводят к необходимости их совокупного учета при оценке погрешности результата. Даже в случае, когда входные данные математической модели не имеют погрешностей, а метод, выбранный для решения полученной математической задачи является точным, избежать вычислительной погрешности при проведении вычислений в системе чисел с плавающей точкой, а значит и погрешности в полученном результате, невозможно. После построения математической модели реального процесса, которая необходимо удовлетворяет требованию адекватности (решение математической задачи, полученное с ее помощью, незначительно отличается от истинного решения реальной задачи), исходная задача и ее математическая формализация в процессе решения и анализа полученного результата, как правило, не разделяются. Однако, в силу особенностей машинной арифметики, невозможно в общем случае получить точное решение даже смоделированной математической задачи (пренебрегая неустранимой погрешностью и погрешностью метода).
Полученное приближенное (в силу перечисленных выше причин) решение некоторой вычислительной задачи  может рассматриваться как точное решение, но другой, возмущенной задачи
может рассматриваться как точное решение, но другой, возмущенной задачи  ( отличается от возмущением входных данных). В этом случае для определения качества полученного приближения необходимо иметь возможность оценить степень зависимости решения от возмущений исходных данных.
( отличается от возмущением входных данных). В этом случае для определения качества полученного приближения необходимо иметь возможность оценить степень зависимости решения от возмущений исходных данных.
Некоторые вычислительные задачи очень сильно «реагируют» на даже малые изменения данных, причем это не зависит от системы с плавающей точкой или выбранного алгоритма, а является свойством самой задачи.
Пример. Рассмотрим квадратное уравнение, корни которого являются «почти» кратными:
 .
.
Корни уравнения: 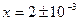 . Изменение правой части уравнения лишь на
. Изменение правой части уравнения лишь на  вызовет изменение в корнях
вызовет изменение в корнях  , т.е. на три порядка большее, чем начальное. Рассмотренная задача является чувствительной.
, т.е. на три порядка большее, чем начальное. Рассмотренная задача является чувствительной.
Назовем задачу чувствительной к погрешностям исходных данных, если даже малые погрешности исходных данных могут привести к значительной погрешности результата, и нечувствительной в противном случае.
Для чувствительных задач «правильные» ответы (ответы с очень малой погрешностью) принципиально нельзя получить никаким алгоритмом, поскольку даже малые ошибки, допущенные при представлении данных и при вычислениях (а эти ошибки сопровождают вычислительный процесс всегда) приведут к значительным погрешностям в результатах. В силу этого чрезвычайно важной и актуальной является численная оценка такой чувствительности, установления параметров, определяющих чувствительность, достаточных условий нечувствительности задачи.
Пусть 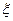 ― входные данные для некоторой задачи, результатом решения которой является
― входные данные для некоторой задачи, результатом решения которой является  ;
; 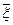 ― возмущенные входные данные, а решение задачи, полученное для этих входных данных, ―
― возмущенные входные данные, а решение задачи, полученное для этих входных данных, ―  . Числом обусловленности задачи называется величина, определяемая соотношением:
. Числом обусловленности задачи называется величина, определяемая соотношением:
 . (2.1)
. (2.1)
Очевидно, чем меньше число обусловленности, тем меньше возмущение результата зависит от возмущения входных данных, тем меньше чувствительность задачи, а при малом числе обусловленности задача окажется нечувствительной к погрешностям исходных данных. Таким образом, число обусловленности задачи является ее мерой чувствительности к возмущающим воздействиям.
Пример. Решить систему уравнений:

Предположим, что вычисления проводятся в системе с плавающей точкой, для которой  . Решая систему методом Гаусса, получим:
. Решая систему методом Гаусса, получим:
 .
.
При подстановке решения в исходную систему получим:
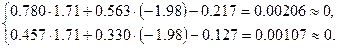
И хотя подстановка показала «хороший результат», точное решение системы, на самом деле, равно:
 .
.
Вычисленное решение очень отличается от точного, хотя ведет себя примерно также, как точное. Рассмотренная задача является чувствительной (или плохо обусловленной, или некорректно поставленной).



