Укажите с помощью чего определяют оптимальное количество интервалов при построении гистограммы
Число интервалов группирования, используемое при вычислении оценок параметров, построении гистограмм, вычислении статистик типа отношения правдоподобия или c 2 Пирсона колеблется в очень широких пределах. Большинство рекомендуемых формул для оценки числа интервалов k носит эмпирический характер и обычно дает завышенные значения.
Определение числа интервалов связано с объемом выборки. Целый ряд рекомендаций из различных источников по выбору числа интервалов k дан в [25].
При выборе интервалов равной длины определяющим является требование, чтобы число наблюдений, попавших в интервалы, было не слишком малым и сравнимым. Такое требование выдвигают в связи с опасением, что в противном случае распределение статистики типа c 2 не будет являться c 2 r –распределением. При этом наиболее часто рекомендуют, чтобы число наблюдений, попавших в интервал, было не менее 10. В [26] отмечено, что на практике допустимо, чтобы число наблюдений в крайних интервалах было менее пяти. В работах [21], [27], посвященных изучению мощности критерия c 2 Пирсона, в случае унимодального распределения допускается уменьшение ожидаемых частот попадания наблюдений для одного или двух интервалов до 1 и даже ниже. Статистическое моделирование подтверждает, что и в такой ситуации распределения статистик типа c 2 хорошо согласуются с соответствующими c 2 r –распределениями.
Во многих источниках, например в [28], можно найти упоминание эвристической формулы Старджесса для определения “оптимального” числа интервалов
В [29] для определения “оптимального” числа интервалов рекомендуют формулу Брукса и Каррузера
В [30] рекомендуют соотношение
В [27] для равновероятных интервалов их число устанавливают порядка
где t – квантиль стандартного нормального распределения для заданного уровня значимости. В ряде работ приводят модификации данной формулы. В [31] предлагают значение
а в [32] – дальнейшее развитие этого соотношения
В исследовании [33] получено соотношение
Все вышеперечисленные рекомендации опирались на предположение, что k следует выбирать таким образом, чтобы вид гистограммы был как можно ближе к плавной кривой плотности распределения генеральной совокупности. В [35] показано, что уклонение гистограммы от плотности распределения в лучшем случае имеет порядок 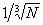 , достигаемый при числе интервалов k порядка
, достигаемый при числе интервалов k порядка 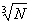 .
.
Очевидно, что “оптимальное” значение k зависит не только от объема выборки, но и от вида закона распределения и от способа группирования.
При асимптотически оптимальном группировании относительно скалярного параметра при 10-11 интервалах в группированной выборке сохраняется около 98% информации, при оптимальном группировании относительно вектора параметров (два параметра) для 15 интервалов – около 95%. Дальнейшее увеличение числа интервалов существенного значения не имеет.
Конкретное число интервалов при асимптотически оптимальном группировании выбирают, исходя из следующих соображений. При оптимальном группировании вероятности попадания в интервалы в общем случае не равны. Обычно минимальны вероятности попадания в крайние интервалы. Поэтому k желательно выбирать из условия NPi ( q ) ³ 5-10 для любого интервала при оптимальном группировании. По крайней мере, минимальная ожидаемая частота должна быть больше 1. В случае использования равновероятного группирования порядок k должен быть примерно таким же, как и при асимптотически оптимальном группировании.
Все наиболее разумные рекомендации по выбору числа интервалов, в том числе по выбору числа интервалов в случае асимптотически оптимального группирования, исходят из того, чтобы при данном N приблизить плотность распределения ее непараметрической оценкой (гистограммой) как можно лучше. Но ни одни из рекомендаций, за исключением [21], [27], не подходят к выбору k с позиций мощности критерия согласия! Не опираются на требование построения наиболее мощного критерия при близких конкурирующих гипотезах.
Об изменении мощности критерия c 2 Пирсона с ростом числа интервалов при проверке простой гипотезы можно судить по рисунку 10. Через X 2 N обозначена статистика, вычисляемая в соответствии с формулой (1). На рисунке 10 представлены полученные экспериментально распределения статистики G k ( X 2 N | H 0 ) и G k ( X 2 N | H 1 ) при числе интервалов k =7,10,15,20 и объеме выборки N =500, когда гипотеза H 0 соответствует нормальному закону, а H 1 – логистическому (два очень близких закона). Для k =7 на рисунке приведены распределения при равновероятном G 7 РВГ ( X 2 N | H 1 ) и асимптотически оптимальном G 7 АОГ ( X 2 N | H 1 ) группировании. Ордината нижнего конца соответствующей вертикальной черты определяет значение b (вероятность ошибки 2-го рода) при уровне значимости a=0,1 для соответствующего числа интервалов. Мощность равна 1- b. Как видно, в полном соответствии с результатами работ [36], [37] при увеличении числа интервалов мощность критерия падает.
Рисунок 10 – Распределения статистики X 2 N при проверке простой гипотезы
Рисунок 11 – Распределения статистики X 2 N при проверке сложной гипотезы
Рисунок 12 – Распределения статистики Y 2 N при проверке сложной гипотезы
Аналогичные изменения мощности критерия для статистики X 2 N в зависимости от числа интервалов при проверке сложной гипотезы иллюстрирует рисунок 11. Здесь также с ростом k мощность критерия падает.
Мощность критерия Никулина с использованием статистики Y 2 N с ростом k уменьшается существенно медленней (рисунок 12) и она выше, чем мощность критерия c 2 Пирсона.
В таблице 2 приведены значения мощности критериев для k от 6 до 30. Проследив изменение мощности критериев при k c 2 Пирсона с уменьшением числа интервалов продолжает возрастать, то мощность критерия Никулина со статистикой Y 2 N при k £ 6 начинает падать. Это свидетельствует о том, что для критерия Никулина существует оптимальное число интервалов, при котором его мощность максимальна.
В [38] мощность критериев типа c 2 в зависимости от выбираемого числа интервалов k была исследована при различных проверяемых гипотезах H 0 и различных альтернативах H 1 при различных объемах выборок. Величина мощности для критериев типа c 2 может быть вычислена в соответствии с формулой [39]:
Таблица 2 – Значения мощности критериев c 2 Пирсона и типа c 2 Никулина при уровне значимости a=0,1 ( H 0 – нормальный закон, H 1 – логистический закон)
Определяем число интервалов (групп) вариационного ряда




![]()
![]()
Число групп (интервалов) приближенно определяется по формуле Стерджесса:
Полученную по формуле Стерджесса величину округляют обычно до целого большего числа, поскольку количество групп не может быть дробным числом.
Если ряд интервальный ряд с таким количеством групп по каким-то критериям не устраивает, то можно построить другой интервальный ряд, округлив m до целого меньшего числа и выбрать из двух рядов более подходящий.
Число групп не должно быть больше 15.
Также можно пользоваться следующей таблицей, если совсем нет возможности вычислить десятичный логарифм.
| Объем выборки, n | 25-40 | 40-60 | 60-100 | 100-200 | Больше 200 |
| Число интервалов, m | 5-6 | 6-8 | 7-10 | 8-12 | 10-15 |
2. Определяем ширину интервала
Ширина интервала для интервального вариационного ряда с равными интервалами определяется по формуле:
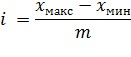
Величину интервала ( i ) обычно округляют до целого числа, исключение составляют лишь случаи, когда изучаются малейшие колебания признака (например, при группировке деталей по величине размера отклонений от номинала, измеряемого в долях миллиметра).
3. Интервальный вариационный ряд.
Гистограмма относительных частот
На предыдущем уроке по математической статистике (Занятие 1) мы разобрали дискретный вариационный ряд (Занятие 2), и сейчас на очереди интервальный. Его понятие, графическое представление (гистограмма и эмпирическая функция распределения), а также рациональные методы вычислений, как ручные, так и программные. В том числе будут рассмотрены задачи с достаточно большим количеством (100-200) вариант – что делать в таких случаях, как обработать большой массив данных.
Предпосылкой построения интервального вариационного ряда (ИВР) является тот факт, что исследуемая величина принимает слишком много различных значений. Зачастую ИВР появляется в результате измерения непрерывной характеристики изучаемых объектов. Типично – это время, масса, размеры и другие физические характеристики. Подходящие примеры встретились в первой же статье по матстату, вспоминаем Константина, который замерял время на лабораторной работе и Фёдора, который взвешивал помидоры.
Для изучения интервального вариационного ряда затруднительно либо невозможно применить тот же подход, что и для дискретного ряда. Это связано с тем, что ВСЕ варианты многих ИВР различны. И даже если встречаются совпадающие значения, например, 50 грамм и 50 грамм, то связано это с округлением, ибо полученные значения всё равно отличаются хоть какими-то микрограммами.
Поэтому для исследования ИВР используется другой подход, а именно, определяется интервал, в пределах которого варьируются значения, затем данный интервал делится на частичные интервалы, и по каждому интервалу подсчитываются частоты – количество вариант, которые в него попали.
Разберём всю кухню на конкретной задаче, и чтобы как-то разнообразить физику, я приведу пример с экономическим содержанием, кои десятками предлагают студентам экономических отделений. Деньги, строго говоря, дискретны, но если надо, непрерывны :), и по причине слишком большого разброса цен, для них целесообразно строить интервальный ряд:
По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в некоторых денежных единицах): 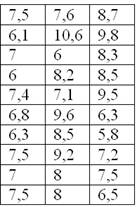
Требуется составить вариационный ряд распределения, построить гистограмму и полигон относительных частот + бонус – эмпирическую функцию распределения.
Такое обывательское исследование проводит каждый из нас, начиная с анализа цены на пакет молока вот это дожил в нескольких магазинах, и заканчивая ценами на недвижимость по гораздо бОльшей выборке. Что называется, не какие-то там унылые сантиметры.
Поэтому представьте свой любимый товар / услугу и наслаждайтесь решением🙂
Очевидно, что перед нами выборочная совокупность объемом 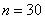 наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
Начнём с экстремальной ситуации, когда у вас под рукой нет Экселя или другого подходящего программного обеспечения. Только ручка, карандаш, тетрадь и калькулятор.
Тактика действий похожа на исследование дискретного вариационного ряда. Сначала окидываем взглядом предложенные числа и определяем примерный интервал, в который вписываются эти значения. «Навскидку» все значения заключены в пределах от 5 до 11. Далее делим этот интервал на удобные подынтервалы, в данном случае напрашиваются промежутки единичной длины. Записываем их на черновик: 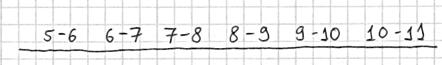
Теперь начинаем вычёркивать числа из исходного списка и записывать их в соответствующие колонки нашей импровизированной таблицы: 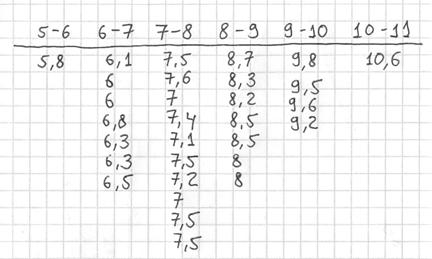
После этого находим самое маленькое число в левой колонке и самое большое значение – в правой. Тут даже ничего искать не пришлось, честное слово, не нарочно получилось:)
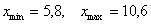 ден. ед. – хорошим тоном считается указывать размерность.
ден. ед. – хорошим тоном считается указывать размерность.
Вычислим размах вариации:
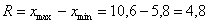 ден. ед. – длина общего интервала, в пределах которого варьируется цена.
ден. ед. – длина общего интервала, в пределах которого варьируется цена.
Теперь его нужно разбить на частичные интервалы. Сколько интервалов рассмотреть? По умолчанию на этот счёт существует формула Стерджеса:
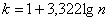 , где
, где 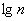 – десятичный логарифм* от объёма выборки и
– десятичный логарифм* от объёма выборки и 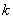 – оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
– оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
* есть на любом более или менее приличном калькуляторе
В нашем случае получаем:
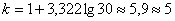 интервалов.
интервалов.
Следует отметить, что правило Стерджеса носит рекомендательный, но не обязательный характер. Нередко в условии задачи прямо сказано, на какое количество интервалов нужно проводить разбиение (на 4, 5, 6, 10 и т.д.), и тогда следует придерживаться именно этого указания.
Длины частичных интервалов могут быть различны, но в большинстве случаев использует равноинтервальную группировку:
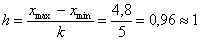 – длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
– длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
И коль скоро мы прибавили 0,04, то по 5 частичным интервалам у нас получается «перебор»: 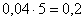 . Посему от самой малой варианты
. Посему от самой малой варианты 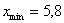 отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по
отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по 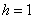 , получая тем самым частичные интервалы. При этом сразу рассчитываем их середины
, получая тем самым частичные интервалы. При этом сразу рассчитываем их середины 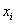 (например,
(например, 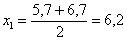 ) – они требуются почти во всех тематических задачах:
) – они требуются почти во всех тематических задачах: 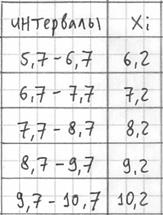
– убеждаемся в том, что самая большая варианта 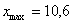 вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
Далее подсчитываем частоты по каждому интервалу. Для этого в черновой «таблице» обводим значения, попавшие в тот или иной интервал, подсчитываем их количество и вычёркиваем: 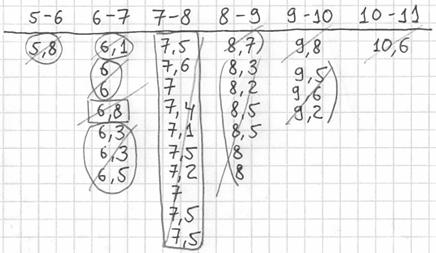
Так, значения из 1-го интервала я обвёл овалами (7 штук) и вычеркнул, значения из 2-го интервала – прямоугольниками (11 штук) и вычеркнул и так далее.
Правило: если варианта попадает на «стык» интервалов, то её следует относить в правый интервал. У нас такая варианта встретилась одна: 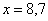 – и её нужно причислить к интервалу
– и её нужно причислить к интервалу 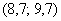 .
.
В результате получаем интервальный вариационный ряд, при этом обязательно убеждаемся в том, что ничего не потеряно: 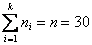 , и, кроме того, рассчитываем относительные частоты
, и, кроме того, рассчитываем относительные частоты 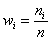 по каждому интервалу, которые уместно округлить до двух знаков после запятой:
по каждому интервалу, которые уместно округлить до двух знаков после запятой: 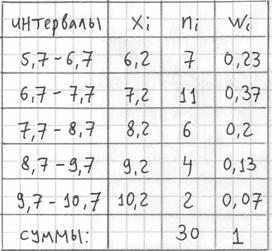
Дело за чертежами. Для ИВР чаще всего требуется построить гистограмму.
Гистограмма относительных частот – это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов, а высота – соответствующим относительным частотам: 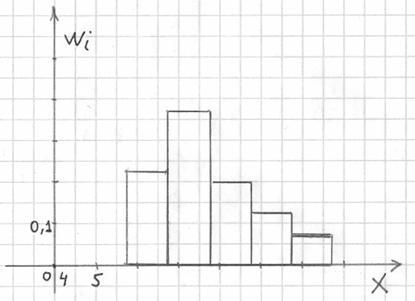
При этом вполне допустимо использовать нестандартную шкалу по оси абсцисс, в данном случае я начал нумерацию с четырёх.
Площадь гистограммы равна единице, и это статистический аналог функции плотности распределения непрерывной случайной величины. Построенный чертёж даёт наглядное и весьма точное представление о распределении цен на ботинки по всей генеральной совокупности. Но это при условии, что выборка представительна.
Вместе с гистограммой нередко требуют построить полигон. Без проблем, полигон относительных частот – это ломаная, соединяющая соседние точки 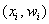 , где
, где 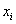 – середины интервалов:
– середины интервалов: 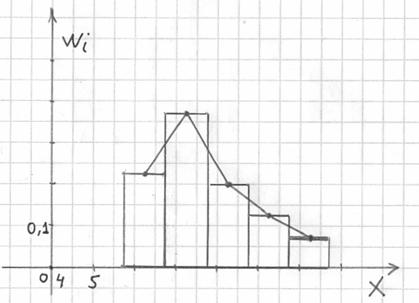
Автоматизируем решение в Экселе:
 Как составить ИВР и представить его графически? (Ютуб)
Как составить ИВР и представить его графически? (Ютуб)
И бонус – эмпирическая функция распределения. Она определяется точно так же, как в дискретном случае:
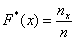 , где
, где 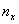 – количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
– количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
Но вот построить её для интервального ряда намного проще. Находим накопленные относительные частоты: 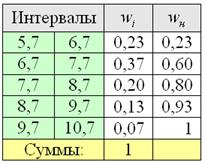
И строим кусочно-ломаную линию, с промежуточными точками 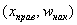 , где
, где 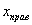 – правые концы интервалов, а
– правые концы интервалов, а 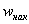 – относительная частота, которая успела накопиться на всех «пройденных» интервалах:
– относительная частота, которая успела накопиться на всех «пройденных» интервалах: 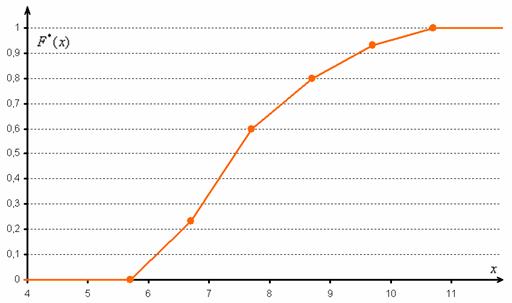
При этом 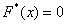 если
если 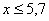 и
и 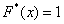 если
если 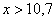 .
.
Напоминаю, что данная функция не убывает, принимает значения из промежутка 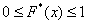 и, кроме того, для ИВР она ещё и непрерывна.
и, кроме того, для ИВР она ещё и непрерывна.
Эмпирическая функция распределения является аналогом функции распределения НСВ и приближает теоретическую функцию 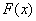 , которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
, которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
Помимо перечисленных графиков, вариационные ряды также можно представить с помощью кумуляты и огивы частот либо относительных частот, но в классическом учебном курсе эта дичь редкая, и поэтому о ней буквально пару абзацев:
Кумулята – это ломаная, соединяющая точки:
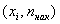 * либо
* либо 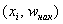 – для дискретного вариационного ряда;
– для дискретного вариационного ряда;
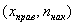 либо
либо 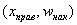 – для интервального вариационного ряда.
– для интервального вариационного ряда.
* 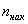 – накопленные «обычные» частоты
– накопленные «обычные» частоты
В последнем случае кумулята относительных частот 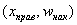 представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
Огива – это обратная функция по отношению к кумуляте – здесь варианты откладываются по оси ординат, а накопленные частоты либо относительные частоты – по оси абсцисс.
С построением данных линий, думаю, проблем быть не должно, чего не скажешь о другой проблеме. Хорошо, если в вашей задаче всего лишь 20-30-50 вариант, но что делать, если их 100-200 и больше? В моей практике встречались десятки таких задач, и ручной подсчёт здесь уже не торт. Считаю нужным снять небольшое видео:
Как быстро составить ИВР при большом объёме выборки? (Ютуб)
Ну, теперь вы монстры 8-го уровня 🙂
Но не всё так сурово. В большинстве задач вам предложат готовый вариационный ряд, и на счёт молока, то, конечно, была шутка:
Выборочная проверка партии чая, поступившего в торговую сеть, дала следующие результаты: 
Требуется построить гистограмму и полигон относительных частот, эмпирическую функцию распределения
Проверяем свои навыки работы в Экселе! (исходные числа и краткая инструкция прилагается) И на всякий случай краткое решение для сверки в конце урока.
Что ещё важного по теме? Время от времени встречаются ИВР с открытыми крайними интервалами, например: 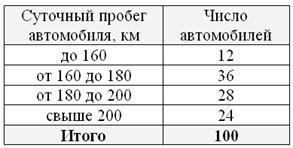
В таких случаях, что убийственно логично, интервалы «закрывают». Обычно поступают так: сначала смотрим на средние интервалы и выясняем длину частичного интервала: 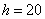 км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:)
км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:)
Ну вот, пожалуй, и вся практически важная информация по ИВР.
На очереди числовые характеристики вариационных рядов и начнём мы с их центральных характеристик, а именно – Моды, медианы и средней.
Пример 7. Решение: заполним расчётную таблицу 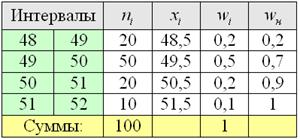
Построим гистограмму и полигон относительных частот: 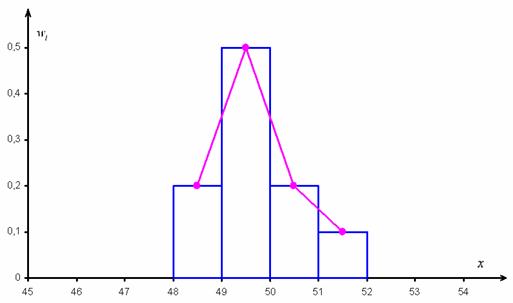
Построим эмпирическую функцию распределения: 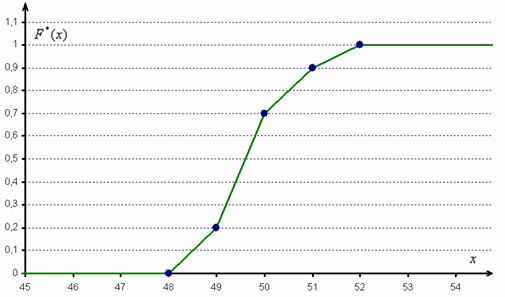
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5
Tutoronline.ru – онлайн репетиторы по математике и другим предметам



