data_client
Excel и Python. Создание сводной таблицы при помощи Python

Для начала давайте представим, что мы являемся аналитиками в фирме по продаже компьютеров, программного обеспечения к ним, а также оказываем услуги по техническому сопровождению. Нам поставлена задача проанализировать участие компании в различных аукционах. Таблица с исходными данными представлена ниже:
| Аукцион | Контрагент | Контакт | Менеджер | Продукт | Количество | Цена | Статус |
| 424845 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Компьютер | 4 | 45 200 | на рассмотрении |
| 312058 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Софт | 2 | 37 600 | на рассмотрении |
| 918390 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Тех. сопровождение | 2 | 21 200 | в ожидании |
| 997345 | Ильин и Ко | Сергей Ильин | Илья Сергеев | Компьютер | 5 | 39 100 | отменен |
| 496901 | Шахты плюс | Данил Сидоров | Илья Сергеев | Компьютер | 3 | 13 600 | выигран |
| 800437 | Шахты плюс | Данил Сидоров | Илья Сергеев | Компьютер | 1 | 24 400 | в ожидании |
| 967756 | Шахты плюс | Данил Сидоров | Илья Сергеев | Софт | 1 | 6 700 | на рассмотрении |
| 871434 | Альма | Женя Сидин | Илья Сергеев | Тех. сопровождение | 2 | 7 000 | в ожидании |
| 131102 | Альма | Женя Сидин | Илья Сергеев | Компьютер | 4 | 42 000 | отменен |
| 191777 | Микрошкин | Сергей Минин | Павел Попов | Компьютер | 3 | 28 900 | выигран |
| 225531 | Микрошкин | Сергей Минин | Павел Попов | Компьютер | 5 | 15 000 | на рассмотрении |
| 159172 | Микрошкин | Сергей Минин | Павел Попов | Тех. сопровождение | 2 | 2 300 | в ожидании |
| 346287 | Микрошкин | Сергей Минин | Павел Попов | Софт | 4 | 46 900 | на рассмотрении |
| 170247 | Кружка и ложка | Виктор Юдин | Павел Попов | Тех. сопровождение | 1 | 14 800 | выигран |
| 769790 | Кружка и ложка | Виктор Юдин | Павел Попов | Компьютер | 1 | 47 500 | выигран |
| 106612 | Кружка и ложка | Виктор Юдин | Павел Попов | Компьютер | 5 | 36 400 | отменен |
| 151606 | Кружка и ложка | Виктор Юдин | Павел Попов | Монитор | 4 | 9 300 | на рассмотрении |
Сохраните таблицу в Excel файл, вставив начиная с ячейки А1, а также назовите лист «База». Сохраните файл с названием «Отчет по аукционам.xlsx».
Итак сначала давайте прочитаем данные из Excel файла, создадим Pandas Dataframe и передадим туда данные:
import pandas as pd
import numpy as np
data_pd=pd.read_excel(‘Отчет по аукционам.xlsx’,sheet_names=’База’)
data_pd[‘Статус’] = data_pd[‘Статус’].astype(‘category’)
data_pd[‘Статус’].cat.set_categories([‘выигран’,’в ожидании’,’на рассмотрении’,’отменен’],inplace=True)
Сводная таблица в Python
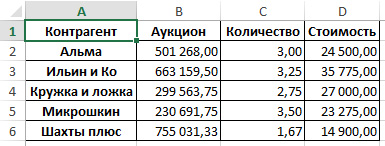
Cоздать сводную таблицу в Python при помощи пакета Pandas очень просто. К примеру давайте создадим сводную таблицу по столбцу Контрагент:
Откройте файл result.xlsx, который скрипт создал в той же папке, где он располагается. Результат должен быть следующего вида:
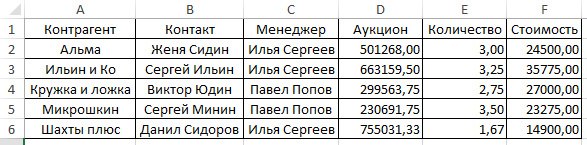
Мы можем создать сводную таблицу по нескольким индексируемым столбцам:
data_pt = pd.pivot_table(data_pd,index=[‘Контрагент’, ‘Контакт’, ‘Менеджер’])
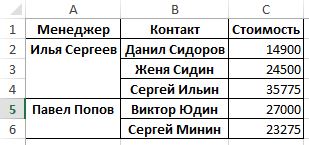
По умолчанию сводная таблица выводится по всем числовым полям, однако это не всегда удобно, а иногда и лишено смысла, поэтому можно выводить сводные данные только по отдельным столбцам. Для примера выведем только столбец «Стоимость», для этого добавим параметр values=[‘Стоимость’]:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’])
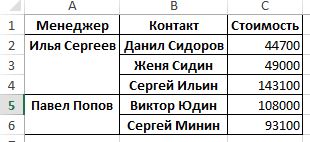
Столбец стоимость по умолчанию выводит среднее значение, однако нам скорее интересна сумма продаж. Добавляем параметр aggfunc=np.sum:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], aggfunc=np.sum)
С помощью aggfunc можно выводить несколько значений, к примеру средную стоимость и количество продаж:
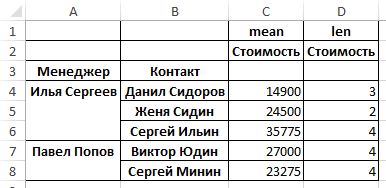
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], aggfunc=[np.mean,len])
Также как в Excel, в Pandas индексируемые параметры можно выводить не только в строки, но и в столбцы, для этого служит параметр columns. Например выведем в столбцы наименование продуктов:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’], values=[‘Стоимость’], columns=[‘Продукт’], aggfunc=np.sum)
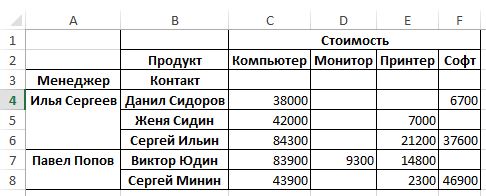
Наверное вы обратили внимание, что в ячейках, где нет данных пусто, хотя нам привычнее, что бы в таких полях указывалось бы значение 0. Добавим параметр fill_value=0:
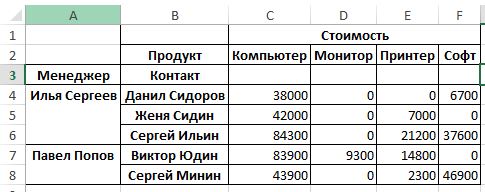
Вероятно полезно было бы рассматривать эффективность деятельности наших менеджеров не только по стоимости продаж, но и по их количеству.
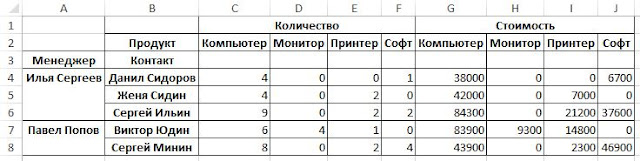
Как и в Excel, мы можем перемещать индексируемые поля между столбцами и строками. К примеру перенесем «Продукт» из столбцов в строки:
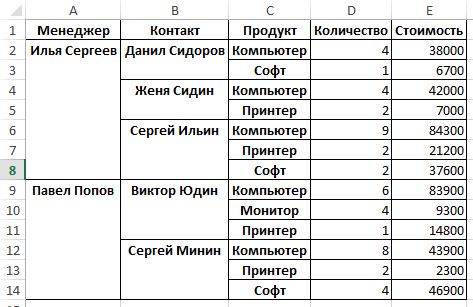
Если нужно добавить итоговую строчку в таблицу, то за это отвечает параметр margins=True:
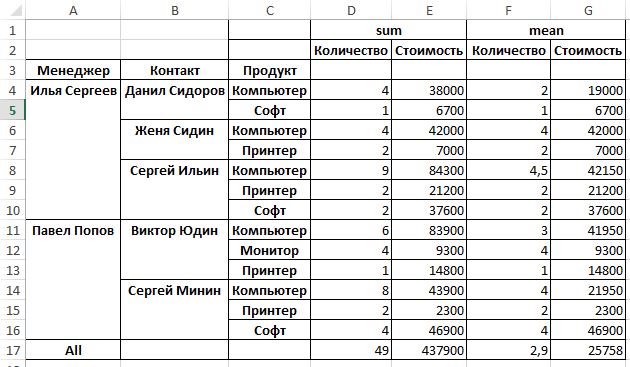
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Контакт’, ‘Продукт’], values=[‘Стоимость’, ‘Количество’], aggfunc=[np.sum,np.mean],fill_value=0,margins=True)
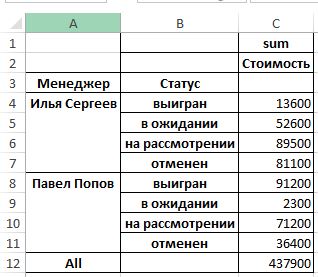
Как мы помним исходной таблице у нас есть столбец «Статус», которому мы присвоили тип категория. Давайте проанализируем работу наших менеджеров этому параметру. Обратите внимание на то, что статусы выводятся именно в том порядке, что мы определили выше:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Стоимость’], aggfunc=[np.sum],fill_value=0,margins=True)
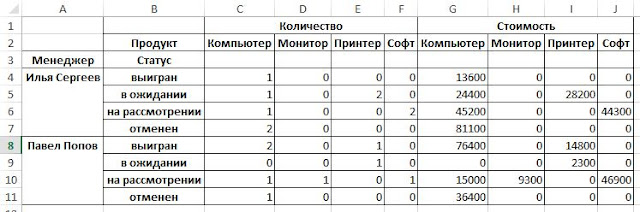
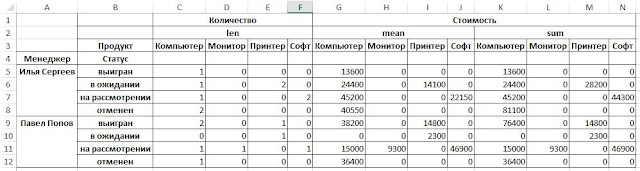
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Количество’, ‘Стоимость’], columns=[‘Продукт’], aggfunc=<'Количество':len, 'Стоимость':np.sum>,fill_value=0)
Также для отдельного значения мы можем использовать несколько агригирующих функций:
data_pt = pd.pivot_table(data_pd,index=[‘Менеджер’, ‘Статус’], values=[‘Количество’, ‘Стоимость’], columns=[‘Продукт’], aggfunc=<'Количество':len, 'Стоимость':[np.sum,np.mean]>,fill_value=0)
Также мы можем фильтровать данные, выводя только те записи, которые нам интересны. К примеру выведем продажи только менеджера «Илья Сергеев»:
data_pt = data_pt.query(‘Менеджер == [«Илья Сергеев»]’)

Или к примеру мы можем вывести только те продажи, у которых статус «выигран» или «в ожидании»:
Сводные таблицы Панд в Python – Простое руководство
В этой статье мы поговорим о сводных таблицах в Python. Мы реализуем то же самое с помощью функции pivot_table в модуле Pandas.
Что такое Сводная таблица?
Сводные таблицы являются ключевой особенностью Microsoft Excel и одной из причин, по которой Excel стал таким популярным в корпоративном мире.
Сводные таблицы обеспечивают большую гибкость для выполнения анализа данных.
Шаги по реализации сводных таблиц в Python
Давайте сразу перейдем к реализации сводных таблиц в Python.
1. Загрузите набор данных по вашему выбору
Независимо от того, любите ли вы покемонов или нет, вы все равно можете получить 100% от этой статьи.
Нужно поймать их всех.… 🙂
2. Синтаксис метода pivot_table()
Это будет намного яснее на примере.
3. Реализация сводных таблиц в Python
Допустим, нам нужно найти среднюю скорость покемонов, принадлежащих к типу 1.
С каждым примером мы будем медленно исследовать pivot_table во всей его красе.
Аналогичный результат с использованием pivot_table
4. Найдите среднюю скорость с помощью сводных таблиц
Но теперь, если бы нас попросили найти среднюю скорость каждого покемона типа 1, а также разделить их на легендарных и Не Легендарных.
Тада! С помощью одной строки кода мы смогли добиться желаемых результатов.
Я не мог не заметить, что в среднем Легендарные Покемоны были быстрее, чем нелегендарные. Магия сводных таблиц.
Здесь важно понять, что нам нужен столбец типа 1 в качестве индекса, поэтому мы передали его в аргумент индекса в методе pivot_table.
Но теперь, поскольку каждый покемон типа 1 принадлежал либо к Легендарной категории, либо к Не Легендарной, мы просто преобразовали наш фрейм данных таким образом, чтобы он теперь показывал среднюю скорость каждого типа.
Теперь у нас есть легендарные или не легендарные функции в наших данных.
Теперь мы создаем ячейки переменной скорости в качестве новой добавленной функции.
Теперь давайте выведем фрейм данных, который показывает среднюю скорость на основе легендарной функции и функции диапазона скоростей.
Я призываю вас попробовать pandas pivot_table на наборе данных Titanic, поскольку это дополнит вашу практику в этой теме.
Сводные таблицы в Python-непростая тема для освоения, но, учитывая преимущества, которые она может предложить, необходимо обязательно включить эти знания в свой инструментарий анализа. Помните, что практика-это ключ здесь!
Вывод
Python, pandas и решение трёх задач из мира Excel
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
Сравним то, что будет выведено, с тем, что можно видеть в Excel.

Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
Реализация возможностей Excel-функции IF в Python
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.
Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
Создание сводной таблицы в Excel
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
Итоги
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
Pandas pivot_table () – анализ данных DataFrame
Функция Panda Pivot_Table () используется для создания таблицы пивота в стиле электронной таблицы в качестве DataFrame. Мы можем запустить совокупную функцию для анализа данных на DataFrame
Что такое пивотный стол?
Пивочный стол – это таблица статистики, которая суммирует данные более обширной таблицы. Сводка данных достигается через различные совокупные функции – сумма, среднее, мин, макс и т. Д.
Таблица Pivot – это техника обработки данных для получения полезной информации из таблицы.
Функция Pandas pivot_table ()
Функция Panda Pivot_Table () используется для создания таблицы Pivot из объекта DataFrame. Мы можем генерировать полезную информацию из строк и столбцов DataFrame. Синтаксис функции pivot_table ():
Примеры таблицы Pandas Pivot
Лучше использовать реальные данные для понимания фактической выгоды от поворотных таблиц. Я скачал образец файла CSV из Эта ссылка Отказ Вот прямая ссылка для CSV-файл Отказ
Файл CSV представляет собой список 1 460 отчетов о финансирования компании, сообщаемых TechCrunch. На следующем изображении показаны данные образца из файла.
Мы заинтересованы в колоннах – «Company», «Город», «штат», «Raisedamt» и «раунд». Давайте создадим некоторые поворотные таблицы для создания полезных статистических данных из этих данных.
1. Простое пример таблицы Pivot
Давайте попробуем создать сводную таблицу для среднего финансирования государством.
Мы также можем вызвать функцию pivot_table () непосредственно на объекте dataframe. Вышеуказанная таблица поворота может быть сгенерирована с помощью фрагмента с ним ниже.
2. Пивовая таблица с совокупной функцией
Функция совокупности по умолчанию – numpy.mean Отказ Мы можем указать функцию совокупности как numpy.sum генерировать общее финансирование государством.
3. Общее финансирование компанией
4. Установка столбца индекса в таблице Pivot
Попробуем создать сводную таблицу для среднего финансирования раунда, сгруппированным государством. Хитрость состоит в том, чтобы генерировать таблицу поворота с «раундом» в качестве столбца индекса.
5. Замена нулевых значений с значением по умолчанию
5. Несколько индексных столбцов столбцов Pivot
Давайте посмотрим на более сложный пример. Мы создадим сводную таблицу общего финансирования на одну компанию за раунд, государственную мудрому.
pandas.pivot_table¶
Create a spreadsheet-style pivot table as a DataFrame.
The levels in the pivot table will be stored in MultiIndex objects (hierarchical indexes) on the index and columns of the result DataFrame.
Parameters data DataFrame values column to aggregate, optional index column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list can contain any of the other types (except list). Keys to group by on the pivot table index. If an array is passed, it is being used as the same manner as column values.
columns column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list can contain any of the other types (except list). Keys to group by on the pivot table column. If an array is passed, it is being used as the same manner as column values.
aggfunc function, list of functions, dict, default numpy.mean
If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names (inferred from the function objects themselves) If dict is passed, the key is column to aggregate and value is function or list of functions.
fill_value scalar, default None
Value to replace missing values with (in the resulting pivot table, after aggregation).
margins bool, default False
Add all row / columns (e.g. for subtotal / grand totals).
dropna bool, default True
Do not include columns whose entries are all NaN.
margins_name str, default вЂAll’
Name of the row / column that will contain the totals when margins is True.
observed bool, default False
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
Changed in version 0.25.0.
Specifies if the result should be sorted.
New in version 1.3.0.
An Excel style pivot table.
Pivot without aggregation that can handle non-numeric data.
Unpivot a DataFrame from wide to long format, optionally leaving identifiers set.
Wide panel to long format. Less flexible but more user-friendly than melt.
This first example aggregates values by taking the sum.
We can also fill missing values using the fill_value parameter.
The next example aggregates by taking the mean across multiple columns.
We can also calculate multiple types of aggregations for any given value column.



