Зачем процессорам нужен кэш и чем отличаются уровни L1, L2, L3

Во всех центральных процессорах любого компьютера, будь то дешёвый ноутбук или » target=»_blank»>сервер за миллионы долларов, есть устройство под названием «кэш». И с очень большой вероятностью он обладает несколькими уровнями.
Наверно, он важен, иначе зачем бы его устанавливать? Но что же делает кэш, и для чего ему разные уровни? И что означает «12-канальный ассоциативный кэш» (12-way set associative)?
Что такое кэш?
TL;DR: это небольшая, но очень быстрая память, расположенная в непосредственной близости от логических блоков центрального процессора.
Однако мы, разумеется, можем узнать о кэше гораздо больше…
Давайте начнём с воображаемой волшебной системы хранения: она бесконечно быстра, может одновременно обрабатывать бесконечное количество операций передачи данных и всегда обеспечивает надёжное и безопасное хранение данных. Конечно же, ничего подобного и близко не существует, однако если бы это было так, то структура процессора была бы гораздо проще.
Процессорам бы тогда требовались только логические блоки для сложения, умножения и т.п, а также система управления передачей данных, ведь наша теоретическая система хранения способна мгновенно передавать и получать все необходимые числа; ни одному из логических блоков не приходится простаивать в ожидании передачи данных.
Но, как мы знаем, такой волшебной технологии хранения не существует. Вместо неё у нас есть жёсткие диски или твердотельные накопители, и даже самые лучшие из них далеки от возможностей обработки, необходимых для современного процессора.

Великий Т’Фон хранения данных
Причина этого заключается в том, что современные процессоры невероятно быстры — им требуется всего один тактовый цикл для сложения двух 64-битных целочисленных значений; если процессор работает с частотой 4 ГГЦ, то это составляет всего 0,00000000025 секунды, или четверть наносекунды.
В то же время, вращающемуся жёсткому диску требуются тысячи наносекунд только для нахождения данных на дисках, не говоря уже об их передаче, а твердотельным накопителям — десятки или сотни наносекунд.
Очевидно, что такие приводы невозможно встроить внутрь процессоров, поэтому между ними будет присутствовать физическое разделение. Поэтому ещё добавляется время на перемещение данных, что усугубляет ситуацию.
Увы, но это Великий А’Туин хранения данных
Именно поэтому нам нужна ещё одна система хранения данных, расположенная между процессором и основным накопителем. Она должна быть быстрее накопителя, способна одновременно управлять множеством операций передачи данных и находиться намного ближе к процессору.
Ну, у нас уже есть такая система, и она называется ОЗУ (RAM); она присутствует в каждом компьютере и выполняет именно эту задачу.
Почти все такие хранилища имеют тип DRAM (dynamic random access memory); они способны передавать данные гораздо быстрее, чем любой накопитель.
Однако, несмотря на свою огромную скорость, DRAM не способна хранить такие объёмы данных.
Одни из самых крупных чипов памяти DDR4, разработанных Micron, хранят 32 Гбит, или 4 ГБ данных; самые крупные жёсткие диски хранят в 4 000 раз больше.
Итак, хоть мы и повысили скорость нашей сети данных, нам потребуются дополнительные системы (аппаратные и программные), чтобы разобраться, какие данные должны храниться в ограниченном объёме DRAM, готовые к обработке процессором.
DRAM могут изготавливаться в корпусе чипа (это называется встроенной (embedded) DRAM). Однако процессоры довольно малы, поэтому в них не удастся поместить много памяти.

10 МБ DRAM слева от графического процессора Xbox 360. Источник: CPU Grave Yard
Подавляющее большинство DRAM расположено в непосредственной близости от процессора, подключено к материнской плате и всегда является самым близким к процессору компонентом. Тем не менее, эта память всё равно недостаточно быстра…
DRAM требуется примерно 100 наносекунд для нахождения данных, но, по крайней мере, она способна передавать миллиарды битов в секунду. Похоже, нам нужна ещё одна ступень памяти, которую можно разместить между блоками процессора и DRAM.
На сцене появляется оставшаяся ступень: SRAM (static random access memory). DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, а SRAM для той же задачи применяет транзисторы, которые работают с той же скоростью, что и логические блоки процессора (примерно в 10 раз быстрее, чем DRAM).
Разумеется, у SRAM есть недостаток, и он опять-таки связан с пространством.
Память на основе транзисторов занимает гораздо больше места, чем DRAM: в том же размере, что чип DDR4 на 4 ГБ, можно получить меньше 100 МБ SRAM. Но поскольку она производится по тому же технологическому процессу, что и CPU, память SRAM можно встроить прямо внутрь процессора, максимально близко к логическим блокам.
С каждой дополнительной ступенью мы увеличивали скорость перемещаемых данных ценой хранимого объёма. Мы можем продолжить и добавлять новые ступени,, которые будут быстрее, но меньше.
И так мы добрались до более строгого определения понятия кэша: это набор блоков SRAM, расположенных внутри процессора; они обеспечивают максимальную занятость процессора благодаря передаче и сохранению данных с очень высокими скоростями. Вас устраивает такое определение? Отлично, потому что дальше всё будет намного сложнее!
Кэш: многоуровневая парковка
Как мы говорили выше, кэш необходим, потому что у нас нет волшебной системы хранения, способной справиться с потреблением данных логических блоков процессора. Современные центральные и графические процессоры содержат множество блоков SRAM, внутри упорядоченных в иерархию — последовательность кэшей, имеющих следующую структуру:
На приведённом выше изображении процессор (CPU) обозначен прямоугольником с пунктирной границей. Слева расположены ALU (arithmetic logic units, арифметико-логические устройства); это структуры, выполняющие математические операции. Хотя строго говоря, они не являются кэшем, ближайший к ALU уровень памяти — это регистры (они упорядочены в регистровый файл).
Каждый из них хранит одно число, например, 64-битное целое число; само значение может быть элементом каких-нибудь данных, кодом определённой инструкции или адресом памяти каких-то других данных.
Регистровый файл в десктопных процессорах довольно мал, например, в каждом из ядер Intel Core i9-9900K есть по два банка таких файлов, а тот, который предназначен для целых чисел, содержит всего 180 64-битных целых чисел. Другой регистровый файл для векторов (небольших массивов чисел) содержит 168 256-битных элементов. То есть общий регистровый файл каждого ядра чуть меньше 7 КБ. Для сравнения: регистровый файл потоковых мультипроцессоров (так в GPU называются аналоги ядер CPU) Nvidia GeForce RTX 2080 Ti имеет размер 256 КБ.
Регистры, как и кэш, являются SRAM, но их скорость не превышает скорость обслуживаемых ими ALU; они передают данные за один тактовый цикл. Но они не предназначены для хранения больших объёмов данных (только одного элемента), поэтому рядом с ними всегда есть более крупные блоки памяти: это кэш первого уровня (Level 1).

Одно ядро процессора Intel Skylake. Источник: Wikichip
На изображении выше представлен увеличенный снимок одного из ядер десктопного процессора Intel Skylake.
ALU и регистровые файлы расположены слева и обведены зелёной рамкой. В верхней части фотографии белым обозначен кэш данных первого уровня (Level 1 Data cache). Он не содержит много информации, всего 32 КБ, но как и регистры, он расположен очень близко к логическим блокам и работает на одной скорости с ними.
Ещё одним белым прямоугольником справа показан кэш инструкций первого уровня (Level 1 Instruction cache), тоже имеющий размер 32 КБ. Как понятно из названия, в нём хранятся различные команды, готовые к разбиению на более мелкие микрооперации (обычно обозначаемые μops), которые должны выполнять ALU. Для них тоже существует кэш, который можно классифицировать как Level 0, потому что он меньше (содержит всего 1 500 операций) и ближе, чем кэши L1.
Вы можете задаться вопросом: почему эти блоки SRAM настолько малы? Почему они не имеют размер в мегабайт? Вместе кэши данных и инструкций занимают почти такую же площадь на чипе, что основные логические блоки, поэтому их увеличение приведёт к повышению общей площади кристалла.
Но основная причина их размера в несколько килобайт заключается в том, что при увеличении ёмкости памяти повышается время, необходимое для поиска и получения данных. Кэшу L1 нужно быть очень быстрым, поэтому необходимо достичь компромисса между размером и скоростью — в лучшем случае для получения данных из этого кэша требуется около 5 тактовых циклов (для значений с плавающей запятой больше).

Кэш L2 процессора Skylake: 256 КБ SRAM
Но если бы это был единственный кэш внутри процессора, то его производительность наткнулась бы на неожиданное препятствие. Именно поэтому в ядра встраивается еще один уровень памяти: кэш Level 2. Это обобщённый блок хранения, содержащий инструкции и данные.
Он всегда больше, чем Level 1: в процессорах AMD Zen 2 он занимает до 512 КБ, чтобы кэши нижнего уровня обеспечивались достаточным объёмом данных. Однако большой размер требует жертв — для поиска и передачи данных из этого кэша требуется примерно в два раза больше времени по сравнению с Level 1.
Во времена первого Intel Pentium кэш Level 2 был отдельным чипом, или устанавливаемым на отдельной небольшой плате (как ОЗУ DIMM), или встроенным в основную материнскую плату. Постепенно он перебрался в корпус самого процессора, и, наконец, полностью интегрировался в кристалл чипа; это произошло в эпоху таких процессоров, как Pentium III и AMD K6-III.
За этим достижением вскоре последовал ещё один уровень кэша, необходимый для поддержки более низких уровней, и появился он как раз вовремя — в эпоху расцвета многоядерных чипов.

Чип Intel Kaby Lake. Источник: Wikichip
На этом изображении чипа Intel Kaby Lake в левой части показаны четыре ядра (интегрированный GPU занимает почти половину кристалла и находится справа). Каждое ядро имеет свой «личный» набор кэшей Level 1 и 2 (выделены белыми и жёлтым прямоугольниками), но у них также есть и третий комплект блоков SRAM.
Кэш третьего уровня (Level 3), хоть и расположен непосредственно рядом с одним ядром, является полностью общим для всех остальных — каждое ядро свободно может получать доступ к содержимому кэша L3 другого ядра. Он намного больше (от 2 до 32 МБ), но и намного медленнее, в среднем более 30 циклов, особенно когда ядру нужно использовать данные, находящиеся в блоке кэша, расположенного на большом расстоянии.
Ниже показано одно ядро архитектуры AMD Zen 2: кэши Level 1 данных и инструкций по 32 КБ (в белых прямоугольниках), кэш Level 2 на 512 КБ (в жёлтых прямоугольниках) и огромный блок кэша L3 на 4 МБ (в красном прямоугольнике).

Увеличенный снимок одного ядра процессора AMD Zen 2. Источник: Fritzchens Fritz
Но постойте: как 32 КБ могут занимать больше физического пространства чем 512 КБ? Если Level 1 хранит так мало данных, почему он непропорционально велик по сравнению с кэшами L2 и L3?
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.
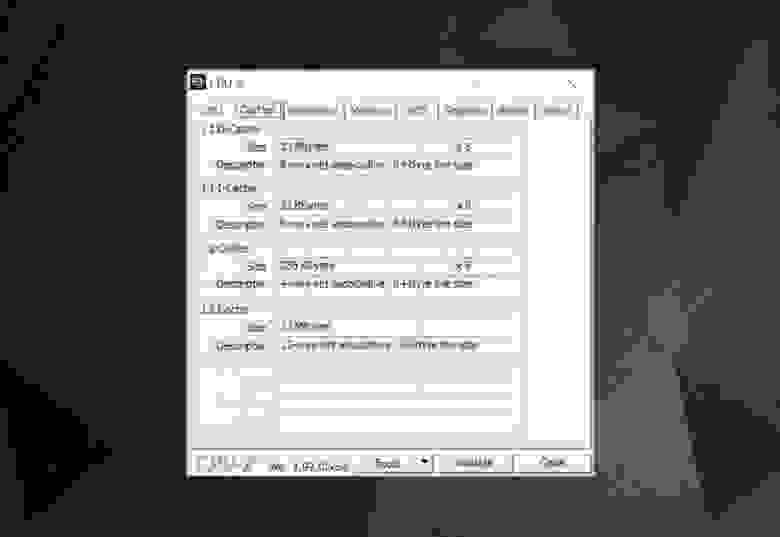
Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.
«8-way» означает, что один блок может быть связан с 8 строками кэша в сете. Чем выше уровень ассоциативности (т.е. чем больше «way»), тем больше шансов на кэш-попадание во время поиска процессором данных и тем меньше потери, вызываемые промахами кэша. Недостатки такой системы заключаются в повышении сложности и энергопотребления, а также понижении производительности, потому что для каждого блока данных нужно обрабатывать больше строк кэша.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду » target=»_blank»>серверы с процессорами от Intel и AMD. В последнем случае — это эпичные