Вооруженный глаз: как распознать дипфейк

Дипфейки — это видеоролики, в которых одно лицо подменяется другим с помощью алгоритмов машинного обучения. Если несколько лет назад подобные имитации были довольно топорными и вызывали большей частью смех, то сегодня технология качественно эволюционировала. И, как это часто бывает с новинками, немедленно была взята на вооружение криминалом. Сгенерированный компьютером голос начальника просит сотрудника перевести крупную сумму, а звезд шоу-бизнеса и политиков терроризируют фальшивыми порнороликами с их участием. Эксперты прогнозируют, что по мере сбора биометрических данных риск мошенничества возрастает. Как распознать дипфейк и какие меры вводятся для борьбы с подобного рода манипуляциями — в материале «Известий».
Кейдж и обнаженка
Считается, что первые дипфейки появились в конце 2017 года, когда пользователь Deepfakes выложил на Reddit порнографические ролики, в которых лица актеров были заменены на лица голливудских звезд. Технология разошлась по Сети и породила массу подобного контента. Чуть позже, наигравшись с роликами для взрослых, пользователи взялись за Николаса Кейджа. С помощью приложения FakeApp, запущенного в январе 2018-го, американский актер был помещен в фильмы, в которых никогда не принимал участия. А несовершенность технологии только прибавила видео веселости.
В дальнейшем опыты стали более разнообразными: Сильвестр Сталлоне «превратился» в мальчика Кевина из фильма «Один дома», Арнольд Шварценеггер «сыграл» всех персонажей во «Властелине колец», а Илон Маск «исполнил» песню «Трава у дома».
Между дипфейками есть свои различия. Наверняка многие встречали видео, на которых пользователи «примеряют маску» знаменитых политиков, дарят им свою артикуляцию и заставляют говорить странные вещи. Данный метод называется Face2Face. Подделка создается в режиме реального времени и в отличие от собственно DeepFake не подменяет одно лицо другим, а искажает мимику исходного объекта.
Однако в последние годы термин deepfake используется в широком смысле — им обозначают все типы имитирующих видео, созданных искусственным интеллектом.

Механизм работы
Дипфейки создаются при помощи метода глубокого обучения, известного как генеративно-состязательная сеть (GAN). Его суть заключается в соревновании двух нейросетей: генератора и дискриминатора. Генератор создает подделку, а дискриминатор пытается понять, настоящее перед ним изображение или нет. Чем лучше обманывает генератор, тем выше конечный результат.
Прежде созданные GAN изображения отличались довольно низким разрешением. По размытости картинки можно было легко идентифицировать запись как сгенерированную. Это ограничение было преодолено в версии ProGAN, благодаря которой разрешение подскочило до 1024×1024 пикселей.
Другая модель — StyleGAN — научилась мастерски создавать лица несуществующих людей. Нейросеть обучилась на библиотеке реальных фотопортретов и стала сама генерировать человеческие образы.
Насколько высоки результаты в генерации новых лиц, можно убедиться на примере картинки ниже. Только на одной из трех фотографий изображена реальная девушка. Она посередине.


Как распознать подделку?
Точность и высокое качество дипфейков вызвали рост недоверия пользователей Сети к видеоконтенту. Однако при более внимательном рассмотрении в некоторых роликах заметны цифровые артефакты — недостатки, которые выдают имитацию. Для обоих поколений дипфейков (ранних недостаточно реалистичных и поздних гиперреалистичных) выявление артефактов происходит по одним и тем же участкам лица. Ученые из Университета Эрлангена–Нюрнберга описали возможные ограничения в своей статье.
Несуществующие лица. Часто у сгенерированных моделей не совпадает цвет левого и правого глаза. В природе явление гетерохромии встречается весьма редко, поэтому смешанные или отличающиеся цвета могут стать сигналом для опознания дипфейка. Также стоит иметь в виду, что расстояние от центра глаза до края радужной оболочки должно быть одинаковым для обоих глаз. Кроме того, ожидается, что оба лимба будут иметь правильный округлый контур. Обнаруженные артефакты проиллюстрированы на картинках ниже.

Face2Face. Для данного метода будут показательны границы лица и кончик носа. Неточное наложение маски приводит к артефактам затемнения, когда, например, одна сторона носа может казаться темнее другой. При этом контуры маски резко отделяются: это хорошо видно внизу лица и над бровями. Элементы, которые частично закрывают части лица (например, пряди волос), моделируются неправильно и могут привести к образованию «дыр».
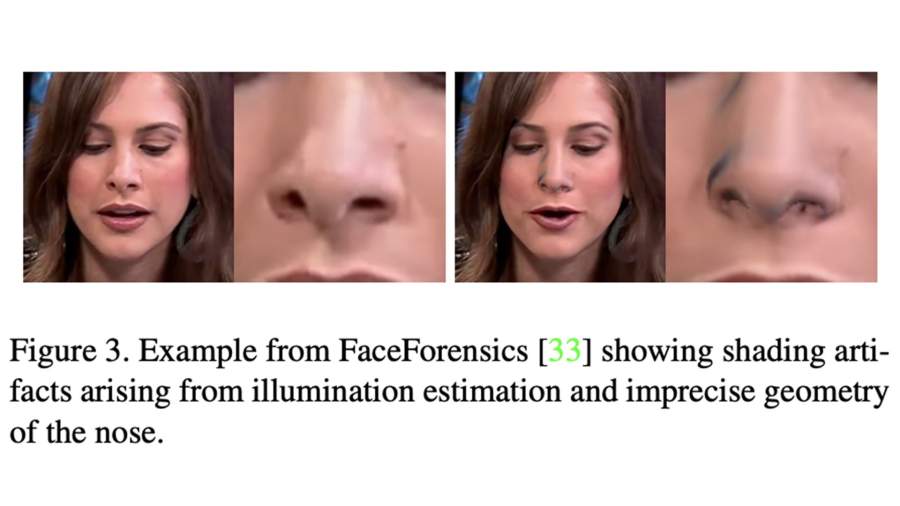
DeepFake. Для дипфейков наиболее уязвимыми считаются глаза и зубы. Многие образцы имеют неубедительные зеркальные отражения — блики в глазах либо отсутствуют, либо кажутся упрощенными. Этот артефакт делает глаза тусклыми. Другой минус — непрорисованные зубы. Бывает, они вообще не моделируются, а выглядят как отдельное белое пятно.
Как делают deepfake-видео и почему лучше говорить «face swap»
Рассказываем о работе технологии face swap, создании известных сегодня deepfake-видео, как трансфер лиц поможет медиарынку и в каком направлении развивается эта область машинного обучения.
Каждый день из многочисленных Telegram-каналов, изданий об ИТ прилетают новости о создании алгоритмов, работающих над преобразованием контента.
Недавно компания Тимура Бекмамбетова и разработчики робота «Вера» придумали технологию синтеза голосов знаменитостей. Учёные из МФТИ научили компьютер воспроизводить изображения, которые видит человек в данный момент, а компания OpenAI создала алгоритм, пишущий почти осмысленный текст на основе минимальных исходных данных.
Нейросети оперируют и видеоконтентом: генерируют движущиеся пейзажи, убирают объекты или же заставляют танцевать людей на фото.
Сложнее обстоят дела с трансфером человеческих лиц или тел на изображениях. Эту сферу начинают осваивать стартапы, которые создают продукты для оптимизации процессов производства контента: Dowell (проект компании Everypixel Group, Россия), Synthesia (Великобритания), а также RefaceAI — создатели приложений Doublicat и Reflect (Украина).
Есть несколько сервисов вроде Reflect, Doublicat или Morhine, которые работают в реальном времени со статичным форматами или GIF. Недавно китайские разработчики зашли на поле видеоформата и выпустили приложение Zao, которое встраивает лица пользователей в известные фильмы.
В остальном широкая аудитория остаётся непричастной к созданию такого контента и потребляет deepfake-видео, которые выпускают известные продакшн-студии или свободные художники на YouTube.
Существуют разные архитектуры алгоритмов, которые переносят лица с видео на видео. Мы расскажем о нескольких самых распространённых.
Метод перемещения лица, в основе которого — кодировщик и декодировщик. Работает это так:
Один из распространённых кодов для переноса лиц таким методом написал российский разработчик-энтузиаст Иван Перов. В его репозитории DeepFaceLab на GitHub есть подробнейшие руководства с комментариями, системные требования к оборудованию и программному обеспечению и даже видеоинструкция.
В подходе с использованием этого метода улучшить результат можно только вручную, корректируя базы данных перед обучением или на постпродакшене.
Поэтому всё чаще в архитектуру с кодировщиком и декодировщиком вплетаются генеративно-состязательные сети. Их суть заключается в соревновании генератора и дискриминатора (отсюда — GAN, Generative Adversarial Network, генеративно-состязательная сеть).
Генераторы учатся создавать наиболее реалистичную картинку, дискриминаторы — определять, какая из них сгенерированная, а какая оригинальная. По мере того как генераторы обучаются обманывать дискриминатор, изображение получается всё более реалистичным.
Таким образом, кодировщик и декодировщик отвечают за перенос изображения, а дискриминатор от генеративных сетей — за улучшение результата. По этой логике работает архитектура Face Swap GAN, созданная японским разработчиком Shaoanlu.
Ещё один подход — архитектуры с использованием нескольких генеративно-состязательных сетей. Каждая сеть отвечает за свою операцию, что сводит к минимуму количество этапов с применением ручного труда.
Чтобы обучить такую нейросеть, требуется несколько суток и мощный кластер видеокарт. Несмотря на это, такой подход является наиболее перспективным, потому что даёт лучший результат.
Одно из решений, созданных по этой технологии, — FSGAN, которое в скором времени обещает опубликовать в открытом доступе его создатель, израильский исследователь Юваль Ниркин.
Здесь одна нейросеть учится подгонять лицо донора под параметры целевого видео (поворот головы, наклон вбок или вперёд), вторая переносит черты лица, а третья делает image blending (слияние изображений), чтобы картинка была более реалистичной, без разрывов или артефактов.
Сегодня перенос лиц, если он выполняется исключительно алгоритмами, всё ещё заметен человеческом глазу: выдают либо визуальные артефакты, например мимика или положение глаз, либо непохожесть нового лица ни на реципиента, ни на донора — в результате получается третья сущность.
Гладкий трансфер лиц всё ещё обеспечивают не нейросети, а навыки в CGI (многие широко известные сегодня создатели deepfake-видео вроде Corridor Crew и Ctrl Shift Face правят работу алгоритмов вручную на постпродакшене или же совершают манипуляции перед самим обучением).
Как правится контент до или после обучения нейросети, нам рассказал моушн-дизайнер студии Clan Андрей Чаушеску, который несколько месяцев назад создал нашумевший в России ролик с актёром Михаилом Ефремовым в трейлере фильма «Ангелы Чарли».
Недавно он опубликовал новую работу, поместив в фильм «Великий Гэтсби» изображение актёра Сергея Бурунова, который обычно озвучивает Леонардо Ди Каприо в русском дубляже. Свои проекты Андрей делает в программе DeepFaceLab, поэтому мы будем говорить о правках, которые требуются для работы именно с этим алгоритмом.
На этапе препродакшена проводится работа с данными перед началом обучения нейросети. Когда два видео разложены на наборы кадров, нужно отсмотреть эти базы и обратить внимание на несколько моментов.
Во-первых, не все люди могут обменяться друг с другом лицами незаметно. Сегодня переносимая алгоритмами область — от бровей до подбородка и от уха до уха (то есть уши, лоб и волосы остаются в целевом видео родными). Поэтому на схожесть результата влияют влияют пол, возраст, цвет кожи и волос, а также комплекция и форма лица.
Некоторые студии, делая поддельные видео с известными артистами, ищут максимально похожих на них людей: ребята из Corridor нашли человека, очень похожего на Тома Круза, а актёр, играющий в ролике с Киану Ривзом, надел чёрный парик, чтобы воссоздать образ актера.
Ctrl Shift Face недавно выпустил три ролика с разными актёрами в одной сцене из фильма «Старикам здесь не место». Лучше всего получился Арнольд Шварценеггер, так как форма его головы больше всего подходит под форму актёра Хавьера Бардема, в отличие от Дефо и Ди Каприо.
Во-вторых, если в донорском видео лицо всегда анфас, а в целевом голова поворачивается и виден профиль, алгоритм не перенесёт лицо корректно, потому что не знает, как выглядит человек в профиль. Так же обстоят дела с положением глаз, движением губ, мимикой и эмоциями (смех или плач): оба человека должны побывать в максимально совпадающем диапазоне ситуаций.
Часто нейросеть некорректно распознаёт глаза. Конечно, больше пользы принесёт подбор фотографий с нужным положением глаз, хорошо считываемой мимикой, но «обман» нейросети тоже может дать хороший результат.
После обучения то, что не углядели в начале, и то, в чём оказался бессилен алгоритм, докрашивается на постпродакшене. В ролике с Сергеем Буруновым Андрею пришлось столкнуться с проблемой разной формы лица двух актеров, которую он решал уже на завершающем этапе.
Самый быстрый способ сделать поддельный ролик — наложить лицо, не выходя за рамки головы человека с целевого видео (в данном случае — Ди Каприо). Лицо Бурунова шире, и, как мне кажется, сходство терялось, поэтому приходилось вручную масками прорисовывать его овал.
Основная программа, которой я пользуюсь на постпродакшене, — Adobe After Effects. Я делаю цветокоррекцию, добавляю размытие для имитации движения камеры и шум для эффекта кинопленки.
Отдельная история — работа с изображениями, в которых перед лицом есть искажающая преграда: скафандр, искривлённое зеркало или очки. Тут единственный выход — ПО вроде After Effects, Cinema 4D.
В них вручную создаётся текстура материала, которая затем ставится перед лицом, чтобы выглядело, как в оригинале. Из-за таких ограничений часто бывает, что очень классные сцены фильмов сложно использовать в deepfake-роликах.
Для YouTube-формата, когда каждый вышедший ролик становится информационным поводом и предполагает вау-реакцию аудитории, такой подход применим. Видео можно долго шлифовать, а потом ещё отдельно описывать процесс, как это часто делают в Corridor Crew.
Очевидно, рынок сервисов для пользователей не предполагает какой-либо постпродакшн: результат нужен сейчас. Того же хочет и профессиональная индустрия (кино и реклама), которая руками переносить лица уже умеет, но сейчас фокусируется на удешевлении и автоматизации процесса.
Монетизируется технология face swap по двум стандартным моделям. Для b2c-аудитории создаются развлекательные приложения вроде Zao или Doublicat. Для b2b-аудитории — продукты, которые используются для оптимизации продакшена, маркетинговых коммуникаций, персонализации брендированного контента или в игровой индустрии.
Среди них Dowell и RefaceAI, создатели которых рассказали, по какой логике работает их продукт и какую нишу на рынке они планируют освоить.
Dowell вырос в офисе компании Everypixel Group, которая занимается производством контента и создаёт продукты на основе искусственного интеллекта. Изучив рынок, создатели стартапа поняли, что развитие продуктов для пользователей и демонстрация deppfake-публикаций на YouTube не их путь, и проработали сценарии использования в киноиндустрии и маркетинге.
Один из кейсов они реализовали с BBDO — рекламный ролик с изображением генерального директора крупного автомобильного бренда, в съёмках которого этот человек не принимал непосредственного участия.
Жизненный цикл сервисов, которые позволяют заменять лица, ограничен: пользователи не будут заходить туда каждый день. Это инструмент, который позволяет «пошуметь», рассказать о себе, оседлать волну хайпа. Но мы решили сосредоточиться на решении бизнес-задач.
Во-первых, это маркетинговая коммуникация брендов с аудиторией. Мы создаём персонализированный контент и с помощью видео помогаем обрести их клиентам пользовательский опыт перед покупкой.
Во-вторых, решаем проблему увеличения доходности агентств, работающих со звёздами, их клиентов. Представьте, что Джордж Клуни одновременно снимается в голливудском фильме, рекламном ролике Nespresso и проводит презентацию нового Mercedes в Штутгарте.
В таком формате доступ к «телу» звёзд появится у тех брендов и организаций (вроде благотворительных фондов), которые никогда не могли себе позволить пригласить звезду живьём.
На старте разработки продукта изучение алгоритмов, находящихся в открытом доступе, помогло нам понять логику работы, увидеть слабые места, но зависеть от чужого кода — тупиковый путь. Это чёрный ящик, содержание которого слабо можно представить, результат будет непредсказуемым.
В процессе собственных разработок мы одновременно проводили несколько исследований. Во-первых, искали влияние одних признаков и черт лица на другие, чтобы ими можно было управлять независимо друг от друга, по отдельности переносить глаза, нос, форму лица и губы.
Во-вторых, мы разделяем персону (черты лица) и контент (условия, в которой лицо появляется: свет, сюжет, эмоции), после чего можем взять персону и поместить её в те условия, которые нам нужны.
Чем страдают все открытые алгоритмы, так это маленьким разрешением переносимой области — 256 на 256 пикселей. Продакшн-студии работают с более качественными изображениями, и здесь мы задались целью увеличить область до стороны в 1024 пикселей.
Проблему можно решить, обучив нейросеть наращивать разрешение с 256 до 1024 пикселей и с помощью дискриминатора оценивать, насколько хорошо это получилось сделать. По такому же принципу можно «деблюрить» изображения, делая из размытых чёткие.
Компания RefaceAI, которая исторически занималась анализом текста и генеративными сетями, связанными с автоматической конвертацией 2D-видео в 3D, video inpainting (удаление или восстановление фрагментов на видео), пришла к технологии face swap случайно, получив запрос на модификацию лиц от одной киностудии.
Тогда они решили протестировать гипотезу: насколько востребованным формат станет для обычных пользователей, и сделали сервис Reflect, который создаёт изображения с заменой лиц.
Сейчас команда выводит на рынок второе приложение, Doublicat. Оно будет менять лица на видео (в бета-версии перенос перенос в формате GIF).
В начале мы провели глубокий анализ всех общедоступных решений, которые используются для создания deepfake, поняли фундаментальные недостатки этих подходов, не позволяющие их масштабировать.
Сейчас для тренировки сетей мы используем существующие фреймворки машинного обучения (PyTorch), но основной код полностью создан нашей командой.
Использование нейросетей позволяет нам работать в более абстрактном пространстве, чем пиксели. Мы не занимаемся вырезанием и вставкой лиц, а затем гармонизацией результата, что требует много ручной работы.
Вместо этого мы натренировали нейросеть модифицировать минимальное количество визуальных признаков лица для максимальной схожести с нужным человеком. Она делает это на основе изученного пространства всех возможных черт лиц людей. Таким образом, необходимость в ручной постобработке видео сведена к минимуму.
Что касается приоритетов в разработке трансфера лиц в видео, для b2c-модели сейчас главное — максимально быстрое обучение алгоритма, чтобы сервис работал в режиме реального времени и обучение не занимало долгие часы. Китайское приложение Zao сделало это первым.
Но его слабая сторона — алгоритм работает с предобученными данными. Пользователь не может загрузить свой контент, он загружает туда лишь изображение, которое переносится в заданный разработчиками набор видео.
B2b-решения больше сфокусированы на качестве переноса лиц, схожести результата и увеличении разрешения переносимой области, оптимизации времени обучения. Команда RefaceAI планирует, помимо лиц, освоить перенос туловища.
Часть нашей команды работает над технологией замены всего тела, это будет следующий большой шаг после замены лиц. Технология тоже основана на концепции генеративно-состязательных сетей. Но в замене тела больше вызовов и проблем, которые нужно решить, прежде чем выводить технологию в производство.
Синхронно с развитием технологии встаёт вопрос о риске распространения ложных новостей и их определения. Разработчики RefaceAI одновременно со своими сервисами создают антидоты, помогающие распознать сгенерированные изображения и видео.
Сейчас подделку можно определить по тем частям тела человека, перенос которых не предусмотрен технологией: уши, волосы, лоб. Если эти части тела особенно выдающиеся, определить можно и невооруженным взглядом, но есть базы данных для распознавания ушей. Но очевидно, что когда-то их тоже станут переносить, и этот способ перестанет работать.
Ещё один распространённый инструмент — бинарный классификатор, который учится определять реальные и поддельные изображения. Однако сама логика работы генеративных сетей подразумевает, что такой классификатор обречён оставаться обманутым.
Интересный подход использовал учёный Хао Ли: у каждого человека есть индивидуальные паттерны мимики и движения лица, которые при переносе наследуются от реципиента. Таким образом можно математическим методом вычислить, что лицо донора ведёт себя неестественным для него образом.
У технологии трансфера лиц пока не устоялось одно название, и во многих источниках в пределах одной и той же публикации её могут называть и так, и так (этот текст — не исключение).
Термин «face swap», предположительно, пришёл в язык в 2000-х годах с появлением в графических редакторах функций, которые позволяли пользователям трансформировать лица на изображениях (иногда употребляли термины «face replacement», «face morphing»), а также из научных работ.
Но сфера применения была очень узкой, поэтому в 2017 году, когда интернет взорвали ложные порноролики с участием известных артистов, технологию стали называть deepfake — по нику пользователя Reddit, который эти ролики публиковал. И это слово легко подвинуло термин, которому на тот момент было полтора десятка лет, и стало употребляться наравне с ним.
Противостояние двух определений заключается в том, что первое удобнее для тех, кто стремится вывести технологию в правовое поле и адаптировать к современным реалиям коммуникации. В конце концов спичрайтинг — это тоже своего рода подделка, но никто его так не называет.
Deepfake: краткая история появления и нюансы работы технологии
Немного истории
Технологии синтезирования видео и аудио нельзя назвать новыми. Они разрабатываются с конца 90-х годов XX века. Конечно, разные попытки делались и до этого, но мы говорим о тех технологиях, которые получили продолжение. Так, в 1997 году компания Video Rewrite представила технологию, которая позволяла сформировать видео, где артикуляция лица совпадала с синтезированной аудиодорожкой. Т.е. моделировалась артикуляционная мимика лица, которая полностью соответствовала синтезированной компьютером аудиодорожкой.
Но это были лишь первые попытки, которые активно развивались в течение двух десятков лет. Сейчас нам доступны технологии обработки голоса, объединения компьютерной графики с реальными видео и многое другое. Не везде применяется ИИ, но все же самые реалистичные системы сформированы на базе машинного обучения.
Появление «настоящих» дипфейков
Технология Deepfake упрощает процесс синтезирования изображения и создания звуковых дорожек с заданными параметрами за счет использования нейронных сетей. Они обучаются на сотнях или даже тысячах примеров лиц и голосов, с ними связанными. После этого ИИ показывает весьма впечатляющие результаты.
Нет сомнения, что с течением времени будут появляться все более реалистичные дипфейки. Уже сейчас они никого не удивляют, а в ближайшем будущем и вовсе станут привычным делом. Но кто отвечает за развитие технологий, где они используются, как работают и чего нам ожидать в будущем?
Современные игроки

Большинство крупнейших технологических игроков и развлекательных компаний активно исследуют отрасль «синтетических медиа». Amazon стремится сделать голос Алексы более реалистичным, Disney изучает, как использовать технологию смены лица в фильмах, а производители оборудования, такие как Nvidia, расширяют границы синтетических аватаров, а также услуг для кинопроизводства и телевидения.
Но есть и организации, которые создают технологии, позволяющие отличить подделку от реальности. В их число входят, например, Microsoft и DARPA.
К слову, у большинства ПО по созданию дипфейков открытый исходный код, что дает возможность работать с дипфейками даже небольшим компаниям. Проектов достаточно много. Это, например, Wombo, Аvatarify, FaceApp, Reface, MyHeritage и многие другие.

Как создаются дипфейки

Классическая компьютерная обработка изображений использует сложные алгоритмы, созданные при помощи традиционного программного обеспечения. Эти алгоритмы чрезвычайно сложны. Как говорилось выше, совсем недавно дипфейки представляли собой контролируемую модель, которой управляют разработчики. Подавляющее большинство элементом артикуляционной мимики жестко прописывалось в алгоритмах.
Правда, для того, чтобы создать убедительный дипфейк, требуются большие объемы видео, статические изображения, голосовые записи, а иногда даже сканирование головы реального актера с последующим анализом в качестве обучающих вводных данных. Например, клиенты Synthesia в течение примерно 40 минут снимают на видео, как они зачитывают заранее подготовленную речь, чтобы потом этот контент использовался для обучения нейронными сетями.
Несмотря на весьма впечатляющие результаты, дипфейки, создаваемые ИИ, не являются идеальными. У дипфейков есть ряд хорошо заметных (не для человека, для специализированного ПО) признаков, которые пока еще позволяют отличить реальность от вымысла. Это, например, нюансы освещения и теней, мигание, артикуляция, выражение и тон голоса. Для создания убедительного дипфейка все это нужно правильно комбинировать.
Изображения и видео

Достаточно часть в этом направлении используется Variational Autoencoder – VAE. Это генеративная модель, которая находит применение во многих областях исследований: от генерации новых человеческих лиц до создания полностью искусственной музыки. Что касается видео, то VAE позволяет достаточно быстро перенести особенности мимики и артикуляции определенного человека на сформированную объемную модель. VAE используется достаточно давно, но дипфейк, созданный при помощи этой технологии, несложно выявить.
А вот с 2017 года развиваются генеративные состязательные сети (GAN). Здесь в единое целое объединены, по сути, две нейронные сети. Одна, «дискриминатор», определяет реалистичность модели, созданной другой нейросетью. На выходе получается модель, которая была «одобрена» и является наиболее реалистичной.

Что дальше?

Дипфейки также поднимают множество вопросов о том, кому какой контент принадлежит, что делать с лицензиями и как наказывать нарушителей. Так, уже сейчас актеры заключают контракты с компаниями, разрешая использовать их образ и голос в рекламе или фильмах. Но, вероятно, некоторые компании будут использовать дипфейки знаменитостей в своих целях без всяких разрешений.



