1.14 Устройства ввода-вывода речевой информации
1.14 Устройства ввода-вывода речевой информации
Модель речи. Устройства ввода – вывода (УВв) речевой информации относятся к совмещенным периферийным устройствам.
Структурная схема анализатора речи. Анализаторы подразделяются на два основных класса: анализаторы сигналов и анализаторы сообщений. В анализаторах сигналов достигается сжатие (компрессия) информационного потока сигналов с микрофона (105 бит/c) за счет учета акустических и статистических характеристик речевого сигнала без обращения к его смысловой функции.
Для получения значений шести спектральных параметров звука (при анализе по методу спектральных характеристик речи) электрический сигнал, полученный с микрофона, пропускается через три полосовых фильтра (рисунок 1.66) с полосами пропускания, равными поддиапазонам речевого спектра. В каждом канале трех поддиапазонов пиковый детектор выделяет максимальное значение амплитуд сигналов за время кванта; аналого-цифровой преобразователь выдает в двоичном коде значение величины выделенной амплитуды. Для обеспечения стабильной работы в схему анализатора введены усилители, охваченные обратной связью, которые осуществляют автоматическую регулировку усиления амплитуды сигнала.
На выходе порогового устройства получаются полуволны гармонических составляющих спектра сигнала в данном поддиапазоне.
Затем программно производится объединение или разбиение квантов речи в зависимости от того, установившийся сегмент речи или переходной, параметры соседних квантов которого резко меняются. Для этого необходимо измерять сходство между параметрами двух соседних квантов, а затем и сегментов. При большом сходстве кванты объединяются, если же изменение параметров слишком велико, сегменты разбиваются. Таким образом определяются границы фонем.
Речевой ввод как альтернатива клавиатурному
Андрей Жданов, Александр Прохоров
Разработчик новой операционной системы выходит на трибуну и, потрясая ноутбуком, говорит:
«Перед вами первая ОС, которая полностью управляется с голоса!»
Пораженная аудитория выдерживает длинную паузу, и вдруг с галерки доносятся слова:
«Format C, двоеточие, Enter».
Современный анекдот
 появлением компьютеров перед человеком встал целый ряд новых проблем, связанных с передачей и хранением информации. Ввод данных всегда требовал значительных затрат времени и сил, а стремление свести эти затраты к минимуму заставляет постоянно работать над способами перевода знаковой системы, которой пользуется человек, на тот язык, который понятен машине. Перфокарты, а потом клавиатура не до конца решили эту проблему, так как эти способы передачи информации не являются естественными для человека, а потому они неэффективны, неэкономичны и, кроме того, требуют длительного освоения.
появлением компьютеров перед человеком встал целый ряд новых проблем, связанных с передачей и хранением информации. Ввод данных всегда требовал значительных затрат времени и сил, а стремление свести эти затраты к минимуму заставляет постоянно работать над способами перевода знаковой системы, которой пользуется человек, на тот язык, который понятен машине. Перфокарты, а потом клавиатура не до конца решили эту проблему, так как эти способы передачи информации не являются естественными для человека, а потому они неэффективны, неэкономичны и, кроме того, требуют длительного освоения.
При современных масштабах распространения ПК работать с ними приходится не только специалистам, владеющим быстрым набором с клавиатуры, но и малоподготовленным пользователям, для которых ввод информации выливается в отдельную проблему. Любой поработавший с современным графическим пакетом согласится, что около десятка движений мышью при создании какого-либо эффекта порой можно заменить одним словом. Таким образом, задача состоит в том, чтобы научить компьютер понимать без посредника тот язык, на котором говорят люди между собой, то есть придумать алгоритм распознавания звукового образа.
На уровне письменного текста указанная проблема уже частично решена: такие программы, как FineReader или CuneiForm, позволяют вводить через сканер любой напечатанный текст. Однако в данном случае мы имеем дело с уже готовым текстом, а ввод информации в процессе его создания представляет определенную сложность. Пока человек не научится телепатически передавать свои мысли, единственным инструментом, служащим ему для этого, является речь, и потому каждому пользователю ПК очень хотелось бы, чтобы его помощник слышал, а главное, понимал своего хозяина.
На первый взгляд все очень просто: если печатный текст распознается, то и речь тоже можно распознать, ведь компьютеру все равно, что обрабатывать звук или рисунок. Казалось бы, нужно только разделить полученное изображение или звуковой поток на повторяющиеся стандартные образы, сопоставить их с используемыми нами знаками и дать им определенные числовые значения, по которым их будет узнавать машина. Все бы так и было, если бы печатный текст и речь были действительно аналогичными методами передачи информации, но в действительности они очень непохожи, и дело здесь вовсе не в типе носителя информации. Человеческую речь скорее можно сравнить с рукописным текстом, который, как и человеческая речь, очень зависит от индивидуальных характеристик каждого человека. Почерк и тембр голоса уникальны и практически неповторимы, и эти непредсказуемые в каждом случае параметры серьезно затрудняют вычленение и систематизацию знаковых образов.
Несмотря на перечисленные трудности, системы распознавания речи совершенствуются довольно быстро и постепенно начинают конкурировать с клавиатурным вводом. При этом необходимо подчеркнуть, что пока компьютер еще весьма далек от человека, улавливающего интонации и настроение собеседника.
Обычно человек, впервые услышав о технологии распознавании речи, полагает, что для надиктовывания текста системе, распознающей речь, не требуется особых навыков, однако это не так. В отличие от клавиатурного, речевой ввод помимо основной информации несет и данные о поле говорящего, о его возрасте, состоянии здоровья, настроении, отношении к передаваемой информации, а также много других дополнительных сведений. Для распознавания речи абсолютное большинство этих данных не помощь, а помеха, то есть как для разговора по телефону, так и для надиктовывания текста системе распознавания от человека требуется так или иначе приспосабливать речь к этим устройствам.
Сегодня нам кажется, что для того, чтобы эффективно пользоваться телефоном, не нужны никакие навыки. Это связано с тем, что обучение происходит исподволь: с раннего возраста дети наблюдают, как взрослые разговаривают по телефону, и незаметно для себя приобретают определенные умения. В подтверждение этому приведем небольшую цитату из «Почтово-телеграфного журнала» за 1902 год:
«Человек, редко прибегающий к посредству телефона, будет говорить или слишком громко, или слишком тихо, и лишь после некоторого навыка можно научиться приспособить свою речь таким образом, чтобы она внятно передавалась телефоном. При этом, однако, не безразлично, на каком языке происходит разговор, так как некоторые языки к этому более пригодны, чем другие. Такое различие особенно ясно сказалось со времени открытия телефонного сообщения между Германией и Францией. Самым неудобным из европейских языков для телефонной передачи оказывается английский язык, изобилующий шипящими звуками и представляющий при телефонировании большие затруднения, так как их очень легко смешать с обычным мешающим шумом в аппаратах».
Итак, речевой ввод информации предъявляет следующие требования:
• говорить следует не слишком громко и не слишком тихо. Лучше всего обычным спокойным голосом. Повышенные интонации несут много побочных данных, вследствие чего процент распознавания падает;
• произносить слова нужно монотонно, но четко. Не должны проглатываться окончания, так как в отличие от человека компьютер пока не может следить за контекстом и додумывать окончания;
• чем меньше посторонних шумов, тем лучше;
• надо стараться поддерживать постоянное расстояние до микрофона;
• в микрофон не должно попадать придыхание, поэтому микрофон нужно держать не прямо напротив рта, а приблизительно на сантиметр вправо и на сантиметр ниже.
Плохое аппаратное обеспечение тоже является источником проблем для распознавания речи, поэтому качественный микрофон и хорошая звуковая плата со встроенным фильтром шумов могут значительно улучшить работу системы распознавания речи. Но когда все трудности решены, перед пользователем программы распознавания звучащей речи открываются совершенно новые возможности. Во-первых, скорость ввода любого текста увеличивается в несколько раз по сравнению с вводом с клавиатуры; при этом затраты необходимых усилий уменьшаются, а обучение вообще не нужно, так как говорить мы все умеем. Во-вторых, такая программа позволяет управлять другими приложениями и операционной системой в целом с помощью голосовых команд, что очень облегчает и ускоряет работу за компьютером.
Возможности голосового управления открывают перед пользователями огромные перспективы. Если учесть, что сегодня во многих офисах компьютер управляет принтером, модемом, факсом, а с появлением DVD стало возможно подключать к домашнему компьютеру аудиоцентры и домашние кинотеатры, то можно себе представить следующую картину из нашего недалекого будущего. Вы сидите на мягком диване и говорите: «Телевизор», потом «МузТВ» включается цепочка «микрофон звуковая карта компьютер телевизор», и вы видите на экране телевизора свой любимый клип. Или вы произносите: «Отправить факс», «номер. », диктуете текст сообщения, потом «Готово», и через несколько секунд услышите в ответ: «Факс отправлен». И все это вполне реально и осуществимо. Теперь добавьте к этому возможность голосовой навигации по Интернету, распознавание голоса, записанного на любой аудионоситель или в звуковой файл. В общем, пора уже наконец задуматься о приобретении системы распознавания звучащей речи, ведь не за горами тот день, когда вам надо будет только произнести слово!
Первые программы, обеспечивающие голосовой ввод данных, были разработаны за рубежом раньше отечественных. Самыми популярными сегодня из англоязычных являются Scansoft Dragon Naturally Speaking и IBM ViaVoice, а из отечественных разработок наибольшее распространение получила программа «Горыныч».
Dragon NaturallySpeaking 7 Essentials
Разработчик: Scansoft
Цена: 59,99 долл.
Dragon NaturallySpeaking 7 Essentials наиболее точная система распознавания речевого ввода, получившая более 160 наград за точность распознавания речи и простоту использования. Программа позволяет диктовать текст непрерывно со скоростью примерно 160 слов в минуту. Dragon NaturallySpeaking полностью интегрирована в Microsoft Internet Explorer и AOL, а также позволяет диктовать текст в большинство Windows-приложений.

Кроме того, программа позволяет автоматически добавлять термины и имена контактных персон за счет сканирования документов пользователя ПК и его электронной почты, так что пользователю не придется вводить спеллинг незнакомых имен. Программа позволяет ускорить рутинные задачи по вводу данных, запускать приложения голосом, посылать e-mail, заполнять формы и осуществлять навигацию в Web. Все это уже сегодня приносит значительную экономию времени и средств, необходимых для подготовки документов для медицинских, юридических и иных госучреждений.
ViaVoice Standard Edition V10
Разработчик: IBM
Цена: 44,99 долл.
Система распознавания речи IBM ViaVoice Standard Edition включает режим надиктовывания и режим подачи голосовых команд. В версии Standard Edition поддерживаются Windows XP Home/98 SE/Me.

Пользователи ViaVoice могут надиктовывать текст, редактировать, корректировать и форматировать текст в текстовом процессоре с голосовым вводом SpeakPad. Текст, надиктовываемый в SpeakPad, можно экспортировать в другие текстовые редакторы. Пользователи могут также диктовать непосредственно в Microsoft Word 2002/2000/97.
Кроме того, можно добавить новые слова, адреса, акронимы и иную персональную информацию. Пользователи Standard Edition могут инициировать базовые команды управления Internet Explorer.
Горыныч ПРОФ 3.0
Самой продвинутой отечественной программой является программа «Горыныч» от российского разработчика VoiceLock. Следует отметить, что разработка распознавания русской речи является весьма специфической задачей. При распознавании речи, произносимой на нашем родном языке, возникает целый ряд трудностей. Те параметры звука, которые легче всего описать машине, наименее важны в русском языке: в частности, долгота звука, критичная в английском языке, в русском не играет практически никакой роли. Весьма остро стоит проблема омофонов (слов, которые пишутся по-разному, а звучат одинаково). Конечно, и в английском языке есть такие слова, но их гораздо меньше, чем в русском, из-за редуцирования гласных, присущего русской фонетике, и вследствие развитой системы склонений и спряжения. Скажите собеседнику слово «красивая» вне контекста неизвестно, что он услышит: «красивая», «красивое» или «красивые»? То же самое со словом «смотрит» может быть, «смотрят»? А в английском языке гласные произносятся отчетливо, согласные не оглушаются, да и окончаний там немного.
Но на этом проблемы вовсе не кончаются. Наша страна преподносит разработчикам систем распознавания русской речи еще один сюрприз диалекты и говоры: необходимо также учитывать различия в произношении в разных регионах России. Как правило, подобные проблемы решаются с помощью предварительной настройки. А технологии, разработанные специалистами фирмы VoiceLock, позволяют настраивать программу всего за несколько минут.
На момент написания статьи в продаже имелась версия программы «Горыныч» 2.0, но готовилась к изданию новая версия «Горыныч ПРОФ» 3.0, описание которой мы приводим ниже.
Следует обратить внимание читателей на то, что дальнейшее описание подготовлено по бета-версии продукта и в коммерческой версии картинки и функционал могут несколько измениться.
По информации издателя компании «Новый Диск» эта версия должна появиться в продаже уже в сентябре этого года.
В новой версии программы значительно улучшено качество распознавания, переработан интерфейс, добавлен модуль автоматической настройки микрофона, облегчена работа со словарями. Программа использует оригинальное ядро, полностью основанное на российских разработках. Вывод текста может производиться в любые текстовые редакторы. Кроме того, имеется возможность управлять голосом отдельными функциями операционных систем Microsoft Windows 98 SE/Mе/2000/XP.
Системные требования
Установка «Горыныч ПРОФ» 3.0 возможна на компьютеры под управлением русских версий Microsoft Windows 98 SE/Mе/2000/XP. Программа не предназначена для работы с Microsoft Windows 95 и NT. Пользователям Microsoft Windows 2000 и XP в зависимости от настроек операционной системы для работы с программой могут потребоваться полномочия администратора.
Чтобы установить саму программу, достаточно 50 Мбайт свободного дискового пространства. Рекомендуется же более 250 Мбайт, так как при меньшем объеме свободного места на жестком диске работа компьютера будет серьезно замедлена. Для работы программы необходим процессор с тактовой частотой не ниже 500 МГц. Оперативной памяти должно быть не менее 64 Мбайт. При увеличении мощности компьютера соответственно возрастает и производительность программы. На компьютере должна быть установлена как минимум 16-разрядная звуковая карта, имеющая микрофонный вход. Для более устойчивой работы подходят звуковые карты среднего и высшего уровня: Sound Blaster, Gravis Ultrasound и т.д., однако при должной настройке возможна работа и на более дешевых моделях звуковых карт.
Микрофон рекомендуется использовать в виде гарнитуры типа Voice Direct (наушники + микрофон) (рис. 1). Такая гарнитура обеспечивает достаточное качество передачи речи и позволяет минимизировать влияние сторонних фоновых шумов.
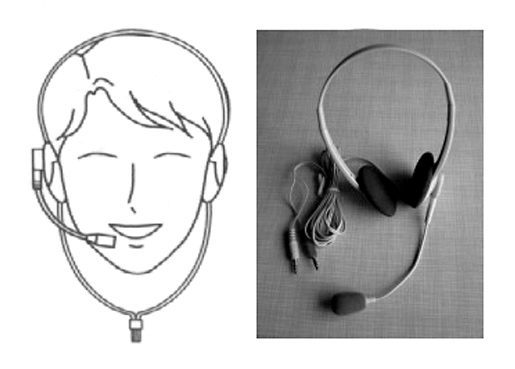
Рис. 1. При работе с программой желательно использовать гарнитуру типа Voice Direct
Не следует использовать встроенные (например, в монитор) и профессиональные микрофоны, ибо они конструктивно не предназначены для распознавания речи.
Работа с программой
В средней части главного окна программы (рис. 2) расположена панель с основными кнопками управления: включения и выключения звукозаписи, выхода из программы, помощи, настроек, прослушивания предыдущего произнесенного слова и кнопка включения/выключения режима диктовки.
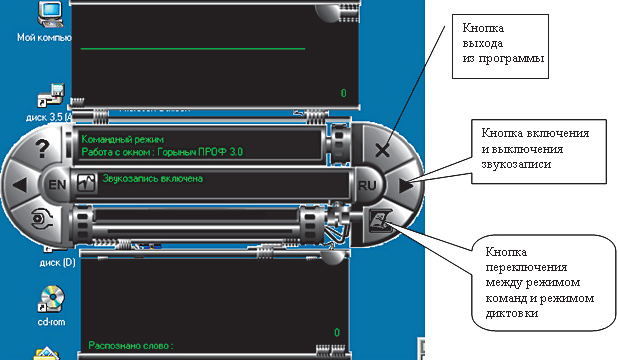
Рис. 2. Главное окно программы
Программа запускается в режиме команд. Если нужно диктовать текст, необходимо нажать на кнопку включения/выключения режима диктовки и включить звукозапись. Чтобы вернуться в режим команд из режима диктовки, следует повторно нажать на эту кнопку.
В верхней и нижней частях главного окна расположены два вспомогательных окна мониторинга, предназначенные для наблюдения за сигналом с микрофона во время произнесения слов. В верхнем окне сигнал отображается по мере поступления со звуковой карты, а в нижнее окно выводится графическое отображение произнесенного слова.
Настройка микрофона
Корректная настройка микрофона является обязательным условием для нормальной работы программы
С помощью «Настройки микрофона» настраивается уровень записи данных. Можно выбрать один из двух вариантов настройки микрофона вручную или автоматически.
При настройке вручную необходимо настроить нормальный уровень записи, ориентируясь на визуальное отображение сигнала: если в микрофон ничего не говорится, то монитор записи должен отображать ровную полосу в середине окна. Когда вы что-нибудь говорите в микрофон, отображение сигнала при произнесении ударных гласных должно немного не доходить до верхних краев окна мониторинга (рис. 3). Если же наблюдается слишком низкий уровень для ударной гласной (рис. 4), то следует говорить громче или повысить уровень записи с микрофона.
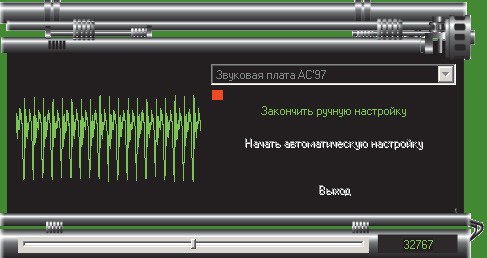
Рис. 3. Оптимальный уровень для ударной гласной
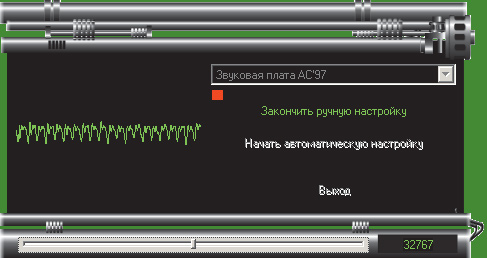
Рис. 4. Слишком низкий уровень для ударной гласной
Необходимо также настроить уровень записи, чтобы уровень шума был приемлемым (рис. 5), а при высоком уровне шума (рис. 6) следует уменьшить уровень записи с микрофона и убедиться, что в микрофон не попадает придыхание и отсутствуют посторонние шумы.
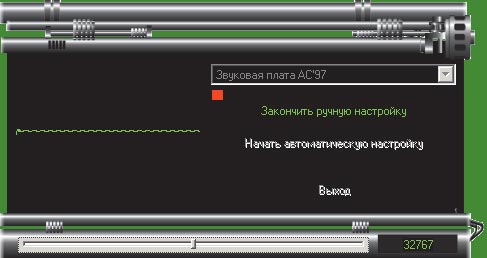
Рис. 5. Приемлемый уровень для шума
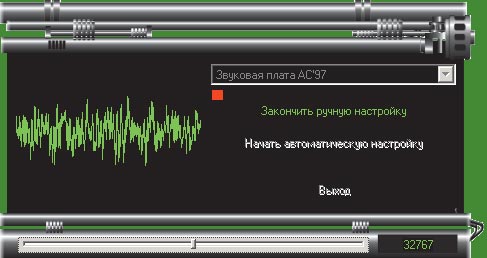
Рис. 6. Неприемлемый уровень для шума
Иногда трудно уловить ситуацию: или сигнал только близок к краям, или уже пересекает их, но для таких случаев предусмотрена автоматическая настройка. Один цикл автоматической настройки состоит из двух последовательно проводящихся тестов шума и сигнала с данными. При тесте шума программа предлагает соблюдать тишину (то есть ничего не говорить в микрофон) для определения уровня фонового шума. В тесте сигнала с данными пользователю предлагается произнести любую фразу из двух-трех слов. При успешном завершении автоматической настройки выдается соответствующее сообщение.
Режим команд
В окно доступных команд (рис. 7) выводится список слов, которые пользователь может произнести в данный момент.
Рис. 7. Окно доступных команд
Вследствие запуска или активации других программ список доступных команд изменяется. Например, для «Блокнота» имеется доступное действие «Меню» (рис. 8). При произнесении слова «меню» активируется встроенное меню «Блокнота». В результате список доступных команд снова изменится: туда добавятся действия, возможные для встроенного меню «Блокнота», «Файл», «Правка», «Поиск», «Справка» (рис. 9). Если теперь сказать «Файл», то это будет эквивалентно щелчку мышью на пункте меню «Файл». Соответственно результату изменится и список доступных действий. Таким же образом список работает и для других запущенных приложений.
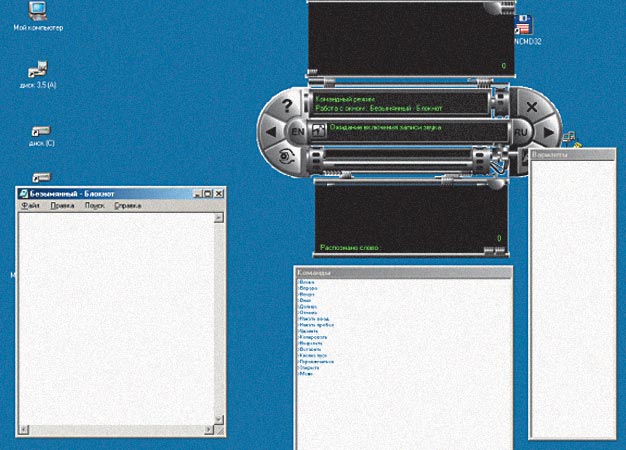
Рис. 8. Изменение списка команд при вызове нового приложения
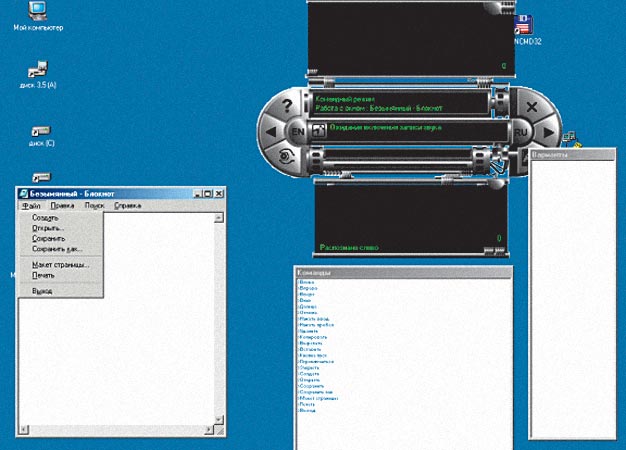
Рис. 9. Изменение списка команд при вызове меню приложения
Режим диктовки
Программа может распознавать те слова, которые внесены в ее словарь. Если диктовать слова, отсутствующие в словаре, то программа подберет ближайшее по характеристикам слово из словаря. Посмотреть список слов, которые внесены в словарь, а также изменить его содержимое можно с помощью модуля «Настройка словарей»: слово, наиболее похожее на сказанное пользователем, будет выведено в активированное для диктовки окно, а другие похожие на сказанное слова, будут выведены в очередь в окне справа.
Для лучшего распознавания в словаре можно заменить (протренировать) уже находящиеся в нем слова либо настроить слово под свое произношение. Если не превышен размер словаря, можно также добавить любое слово по своему выбору. Например, на рис. 10 показано, как может быть протренировано слово «сохранить» из командного словаря. Сначала необходимо указать в списке нужный словарь, а потом нажать кнопку «Загрузить словарь» в итоге в левую часть окна программы в столбец будут выведены все слова из выбранного и загруженного словаря.
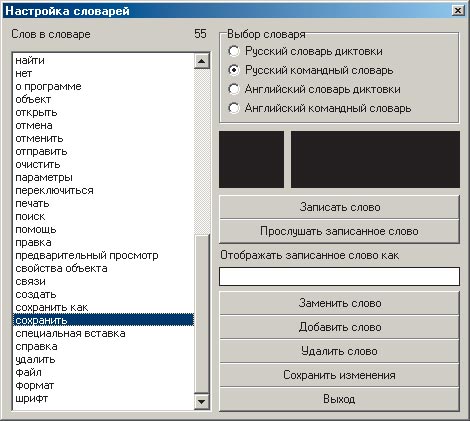
Рис. 10. Настройка словарей
Теперь двойным щелчком мыши укажите в списке слов нужное, затем нажмите кнопку «Записать слово» и произнесите нужное слово так, как вы собираетесь произносить его при дальнейшей работе с программой. Успешно записанное слово будет выведено на экран (рис. 11).
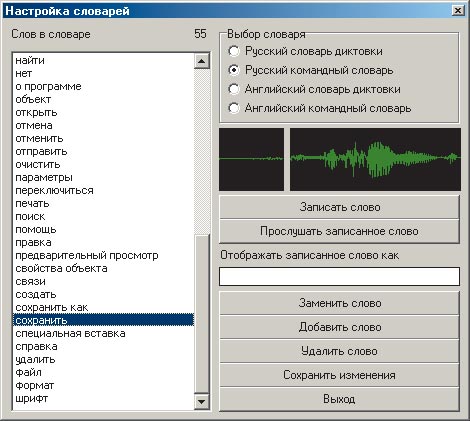
Рис. 11. Пример записи нового произношения слова
Для контроля записанное слово можно прослушать, и если результат вас не устраивает (например, слышен сильный хлопок дверью поблизости), то слово можно записать снова.
Устройства ввода-вывода речевой информации
Устройства ввода – вывода (УВв) речевой информации относятся к совмещенным периферийным устройствам.
Общение с ЭВМ по речевому каналу дает пользователю следующие преимущества:
— общение ведется в двух направлениях, что обеспечивается универсальностью канала;
— общение проходит на естественном языке благодаря удобному интерфейсу;
— речевой канал для пользователя является самым быстродействующим и позволяет освободить зрительный и тактильный аппараты и повысить степень сосредоточенности на основной выполняемой работе;
— УВв речи легко совмещаются с другими ПУ;
— аппаратные средства при современном уровне электронной техники могут быть выполнены малогабаритными и механически прочными.
Человеческая речь представляет собой последовательность звуковых колебаний в диапазоне от 50 до 5000 Гц. Средняя скорость произнесения равна примерно 200 слов/мин.
Структурная схема анализатора речи.
Анализаторы подразделяются на два основных класса: анализаторы сигналов и анализаторы сообщений. В анализаторах сигналов достигается сжатие (компрессия) информационного потока сигналов с микрофона (105 бит/c) за счет учета акустических и статистических характеристик речевого сигнала без обращения к его смысловой функции.
В анализаторах речевых сообщений осуществляется компрессия информационного потока за счет введения операции распознавания смысловых элементов речи (фразы, слова, морфемы, фонемы). Анализаторы речевых сообщений подразделяются на две группы: с ограниченным словарем и универсальные.
Анализаторы ограниченного словаря ориентированы на распознавание заданного конкретной задачей числа речевых команд (обычно 100), то есть на идентификацию одной из произносимых речевых команд словаря в виде номера команды. На этапе распознавания производится сопоставление эталонов команд с произносимой командой и выбора наиболее схожего эталона.
Универсальные анализаторы ориентированы на текущее распознавание полного набора смысловых элементов речи (фонем или морфем), из которых может быть составлено и в дальнейшем распознано любое слово или слитно произнесенное речевое сообщение. Распознавание осуществляется лингвистическим процессором по правилам, заложенным в базе знаний.
Для получения значений шести спектральных параметров звука (при анализе по методу спектральных характеристик речи) электрический сигнал, полученный с микрофона, пропускается через три полосовых фильтра (рисунок 1.66) с полосами пропускания, равными поддиапазонам речевого спектра. В каждом канале трех поддиапазонов пиковый детектор выделяет максимальное значение амплитуд сигналов за время кванта; аналого-цифровой преобразователь выдает в двоичном коде значение величины выделенной амплитуды. Для обеспечения стабильной работы в схему анализатора введены усилители, охваченные обратной связью, которые осуществляют автоматическую регулировку усиления амплитуды сигнала.

методу спектральных характеристик
На выходе порогового устройства получаются полуволны гармонических составляющих спектра сигнала в данном поддиапазоне.
Затем программно производится объединение или разбиение квантов речи в зависимости от того, установившийся сегмент речи или переходной, параметры соседних квантов которого резко меняются. Для этого необходимо измерять сходство между параметрами двух соседних квантов, а затем и сегментов. При большом сходстве кванты объединяются, если же изменение параметров слишком велико, сегменты разбиваются. Таким образом определяются границы фонем.
Структура устройства ввода речи.

В основе лежит принцип распознавания образов. Система выделяет из поступающего речевого сигнала набор некоторых признаков, составляющий его описание, затем сравнивает полученное описание с эталонными описаниями, хранящимися в библиотеке.

Различия систем речевого ввода определяется тем, какие элементы речевого сообщения выделяются и распознаются, какие признаки образуют описание речевого сигнала, какие алгоритмы используются для определения меры сходства и какими аппаратно-программными средствами они реализуются. Помимо распознавания элементарных составляющих речевых сигналов, система должна интерпретировать речевые сообщения (находить соответствующие им орфографические текстовые последовательности).
Базовым элементом для большинства систем распознавания и интерпретирования речевых сообщения является слово, Разграничение слов выполняется на основе анализа длительности паузы, скорости изменения сигнала перед и после паузы и ряда других признаков, выделяемых из звукового сигнала.
Все системы ввода речи делятся по следующим критериям:
− способности распознавать слитную речь или отдельно произносимые слова;
− объему словаря распознаваемых слов;
− ориентированности на одного говорящего или на произвольное число говорящих.
В системах речевого ввода для повышения достоверности обычно предусматривают визуальную обратную связь (на экране выдается символьное представление произнесенного слова).
Эталоны слов в виде их описаний на уровне фонем помещаются в словарь, хранящийся в памяти ЭВМ либо в ПЗУ эталонов. Затем полученное на этапе анализа описание сравнивается по типу ассоциативного поиска методом перебора или на матричном процессоре с описаниями всех эталонов. Вводимой фонеме (слову) приписывается имя того эталона, код описания которого наиболее близок к коду описания распознаваемого слухового образа.
Если набор слов ограничен, то распознавать слова и границы между ними довольно просто (рисунок 1.68, а). В этом случае алгоритм распознавания речевых команд основан на принципе перцептрона.
Лучшие из современных программ после предварительной настройки на голос пользователя распознают дискретную речь с ошибкой, не превышающей 5%. При распознавании слитной речи (рисунок 1.68, б) число ошибок примерно в 5 раз больше. При спонтанном диалоге ошибок распознавания примерно вдвое больше, чем при чтении текста. С увеличением объема словаря разбиение на слова становится сложнее, качество распознавания падает.


Рисунки 1.68 – Структурные схемы устройств ввода речевых сообщений
Устройства вывода речевой информации – синтезаторы. Задача вывода речевой информации сводится к преобразованию машинных кодов, в колебания звуковых частот, составляющих речевой сигнал. Устройства вывода речевых сообщений при любой реализации аппаратно и программно проще, чем устройства ввода.
Синтезаторы подразделяются на классы и группы по тем же признакам, что и анализаторы. Классам анализаторов речевых сигналов и сообщений соответствуют такие же классы синтезаторов: речевых сигналов и речевых сообщений. Синтезаторы речевых сообщений, как и анализаторы речевых сообщений, делятся на две группы: синтезаторы ограниченного словаря – компиляторы и универсальные.

При формировании по образцам словарь компилируемых слов ограничен объемом описаний образцов, хранимых в ПЗУ, при формировании по правилам словарь практически не ограничен.
Системы ввода-вывода речевой информации.
Способы формирования речевого сигнала делятся на 2 группы:
— формирование по образцам (компилятивный синтез);
— синтез по правилам.
Процесс преобразования символьного представления информации в сигнал речевого сообщения состоит из 2-х основных этапов: конструирование речевого сообщения и синтеза речевого сигнала.
Конструирование речевого сообщения заключается в построении команд управления аппаратными средствами синтезатора, в соответствии с которыми на выходе синтезатора формируется речевой сигнал.
Формирование речевого сообщения по образцам.
Представляет собой восстановление аналогового сигнала, где выходные речевые сообщения (аналоговые сигналы) находятся в библиотеках-словарях. При необходимости вывести сообщение – производится поиск нужного сообщения в библиотеке и выводится через канал воспроизведения.
Системы формирования речевых сигналов по образцам различаются возможностями библиотек, качеством звучания восстановленной речи и сложностью аппаратной реализации.
Недостаток – медленный поиск нужного сообщения.
Достоинство – обеспечивает сравнительно хорошее качество речи.
Синтез речевых сообщения по правилам.
Основано на расчленении речевого сигнала на отдельные фонетические составляющие. Что бы вывести речевые сообщения, необходимо иметь фонетическое описание произносимого слова, Фонетическое описание представляет собой последовательность элементов фонетического алфавита, включая паузы.
Конструирование речевого сообщения по правилам включает в себя два этапа:
— символьное представление «орфографического текста» преобразуется в фонетическое описание;
— последовательность элементов фонетического алфавита преобразуется в последовательность управляющих слов для непосредственного управления синтезатором.
Система ввода речевых сообщений.
В основе лежит принцип распознавания образов. Система выделяет из поступающего речевого сигнала набор некоторых признаков, составляющий его описание, затем сравнивает полученное описание с эталонными описаниями, хранящимися в библиотеке.
Различия систем речевого ввода определяется тем, какие элементы речевого сообщения выделяются и распознаются, какие признаки образуют описание речевого сигнала, какие алгоритмы используются для определения меры сходства и какими аппаратно-программными средствами они реализуются. Помимо распознавания элементарных составляющих речевых сигналов, система должна интерпретировать речевые сообщения (находить соответствующие им орфографические текстовые последовательности).
Базовым элементом для большинства систем распознавания и интерпретирования речевых сообщения является слово, Разграничение слов выполняется на основе анализа длительности паузы, скорости изменения сигнала перед и после паузы и ряда других признаков, выделяемых из звукового сигнала.
Все системы ввода речи делятся по следующим критериям:
— способности распознавать слитную речь или отдельно произносимые слова;
— объему словаря распознаваемых слов;
— ориентированности на одного говорящего или на произвольное число говорящих.
В настоящее время отсутствуют системы, способные воспринимать слитную речь при большой библиотеке, для интерпретирования речевых сообщений с неограниченным словарем должны быть созданы экспертные системы (словари, наборы эталонных описаний речевых сигналов, наборы лингвистических правил). Так же не решена задача определения границ слов.
Численные значения этих характеристик зависят от объема словаря и алгоритмов распознования. Для словаря в 200-300 слов вероятность правильного распознования составляет 95-98 %.
В системах речевого ввода для повышения достоверности обычно предусматривают визуальную обратную связь (на экране выдается символьное представление произнесенного слова).
Блок питания ПЭВМ
Интерфейс управления питанием блока ATX позволяет организовать программное отключение питания после закрытия операционной системы. Полезным элементом блока является выключатель, позволяющий отключать его от силовой сети, так как при выключении питания программно или кнопкой блок остается под напряжением, и, например, возможные ночные броски напряжения могут его повредить. Разъемы жгутов блоков питания AT и ATX также различны. Распайка основных разъемов питания и дополнительных жгутов для питания накопителей представлена на рисунке 2.1.
Цепь +3.3 В Sense блока питания ATX служит для подачи сигнала обратной связи стабилизатору напряжения +3.3 В. На блоке питания ATX может быть также дополнительный разъем для управления вентилятором и питания интерфейса IEEE-1394.
К блокам питания предъявляется следующие требований:
— по уровню помех, передаваемых во вторичные цепи;
— по стабильности питающих напряжений (при разбросе напряжений в сети и колебании токов нагрузки);
— по температурной стабильности;
— по защите ПЭВМ от значительного повышения или понижения напряжения в первичной сети;
— по уровню электромагнитного излучения;
— по уровню обратных помех, генерируемых в питающую сеть.

а) основные разьемы блока АТ;
б) основной разьем блока АТХ;
в, г) разьемы питания накопителей.
Структурная схема блока питания с импульсным трансформатором представлена на рисунке 2.2.
Напряжение сети, после сетевого фильтра выпрямляется диодным мостиком и поступает на высокочастотный преобразователь. На выходе преобразователя формируются высокочастотные импульсы, поступающие на понижающий импульсный трансформатор, с обмоток которого снимаются номиналы напряжений, преобразуемые в постоянные напряжения на отдельных выпрямителях. Стабилизация выходных напряжений осуществляется за счет изменения ширины импульсов напряжения на выходе преобразователя: через усилитель обратной связи на формирователь поступает стабилизируемое напряжение, величина которого управляет шириной импульсов. Это, в свою очередь, увеличивает или уменьшает отдаваемый в нагрузку ток.

Рисунок 2.2 – Структурная схема блока питания ПЭВМ



