Мысли вслух
вторник, 23 октября 2012 г.
Ещё раз про однозначное декодирование
Введение
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А — 00, Б — 01, В — 100, Г — 101, Д — 110. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны. Выберите правильный вариант ответа.
1) для буквы Д — 11; 2) это невозможно; 3) для буквы Г — 10; 4) для буквы Д — 10
Как показывает практика, эта задача вызывает серьезные трудности не только у многих учеников, но даже у учителей информатики.
Нужно сказать, что этот материал практически не рассматривается в существующих школьных учебниках информатики, поэтому все (как ученики, так и учителя) вынуждены разбираться самостоятельно. В то же время вузовские учебники 5, где соответствующая теория изложена строго и научно, достаточно сложны для понимания. Попробуем разобраться в сути кодирования и декодирования на школьном уровне, то есть так, как можно объяснить ученикам 8-11 классов.
В чём проблема?
Предположим, нам нужно передать сообщение по цифровым каналам связи. Для этого его необходимо закодировать, то есть сопоставить каждому символу исходного сообщения некоторый код (кодовое слово). Для определенности будем использовать двоичные коды, то есть последовательности нулей и единиц.
Пример 1. Пусть для кодирования фразы «МАМА МЫЛА ЛАМУ» выбран такой код:
| М | А | Ы | Л | У | пробел | (1) |
|---|---|---|---|---|---|---|
| 00 | 1 | 01 | 0 | 10 | 11 |
Коды букв «сцепляются» в одну битовую строку и передаются, например, по сети:
Эта цепочка битов приходит в пункт назначения, и тут возникает проблема — как восстановить исходное сообщение (конечно, при условии, что мы знаем код, то есть знаем все пары «символ–кодовое слово», которые использовались при кодировании).
Итак, мы получили 0010011100010111010010. Легко понять, что при использовании кода (1) раскодировать такое сообщение можно самыми разными способами. Например, можно предположить, что оно составлено только из букв А (код 1) и Л (код 0). Тогда получаем
В общем, ни мамы, ни ламы.
Определение. Код называется однозначно декодируемым, если любое кодовое сообщение можно расшифровать единственным способом (однозначно).
Сказанное выше означает, что код (1) НЕ является однозначно декодируемым. Как же определить, является ли заданный код однозначно декодируемым? Этим вопросом мы и займемся.
Равномерные коды
Проблема состоит в том, чтобы правильно разбить полученную битовую цепочку на отдельные кодовые слова. Для того, чтобы её решить, можно, например, использовать равномерный код, то есть код, в котором все кодовые слова имеют одинаковую длину. Например, в нашей фразе 6 символов, поэтому можно использовать 3-битный код (который позволяет закодировать 8 = 2 3 различных символов).
Пример 2. Закодируем фразу из примера 1, используя код:
| М | А | Ы | Л | У | пробел | (2) |
|---|---|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 100 | 101 |
Получаем закодированное сообщение
Длина этого сообщения — 42 бита вместо 22 в предыдущем варианте, зато его легко разбить на отдельные кодовые слова и раскодировать («_» обозначает пробел):
Видим, что равномерные коды неэкономичны (закодированное сообщение в примере 2 почти в два раза длиннее, чем в примере 1), но зато декодируются однозначно.
Неравномерные коды
Для того, чтобы сократить длину сообщения, можно попробовать применить неравномерный код, то есть код, в котором кодовые слова, соответствующие разным символам исходного алфавита, могут иметь разную длину.
Пример 3. Используем для кодирования фразы из примера 1 следующий код:
| М | А | Ы | Л | У | пробел | (3) |
|---|---|---|---|---|---|---|
| 01 | 00 | 1011 | 100 | 1010 | 11 |
Получаем
Здесь 34 бита. Это, конечно, не 22, но и не 42.
Несложно показать, что эта битовая цепочка декодируется однозначно. Действительно, первая буква — М (код 01), потому что ни одно другое кодовое слово не начинается с 01. Аналогично определяем, что вторая буква — А. Действительно, за 01 следует 00 (код буквы А) и никакое другое кодовое слово не начинается с 00. Это же свойство, которое называется условием Фано, выполняется не только для кодовых слов 01 и 00, но и кодовых слов всех других букв (проверьте это самостоятельно).
Условие Фано. Никакое кодовое слово не совпадает с началом другого кодового слова.
Коды, для которых выполняется условие Фано, называют префиксными (префикс слова — это его начальный фрагмент). Все сообщения, закодированные с помощью префиксных кодов, декодируются однозначно.
Префиксные коды имеют важное практическое значение — они позволяют декодировать символы полученного сообщение по мере его получения, не дожидаясь, пока всё сообщение будет доставлено получателю.
Упражнение. Расшифруйте сообщение, закодированное кодом (3). При расшифровке кода очередной буквы не заглядывайте вперёд!
Термины «условие Фано» и «префиксный код» не используются в заданиях ЕГЭ и ГИА, однако для решения этих задача важно, чтобы ученики понимали содержание условия Фано.
Пример 4. Рассмотрим ещё один код
| М | А | Ы | Л | У | пробел | (4) |
|---|---|---|---|---|---|---|
| 10 | 00 | 1101 | 001 | 0101 | 11 |
Ясно, что он не является префиксным: код буквы А (00) совпадает с началом кода буквы Л (001) и код пробела (11) совпадает с началом кода буквы Ы (11). Закодированное сообщение
также имеет длину 34 бита, как и при использовании кода (3). Начнем раскодировать с начала. Ясно, что первой стоит буква М, потому что ни один другой код не начинается с 10. Затем — комбинация 001, которая может быть кодом буквы Л или кодом буквы А (00), за которым следует код буквы Ы или пробела. Получается, что для декодирования сообщения нам нужно «заглядывать вперёд», что очень неудобно.
Попробуем декодировать с конца битовой строки. Последние биты 0101 могут представлять только букву У, следующие 10 — только букву М и т.д. Можно проверить, что теперь сообщение однозначно декодируется с конца! Это происходит потому, что выполняется условие, которое можно назвать «обратным» условием Фано: никакое кодовое слово не совпадает с окончанием другого кодового слова. Коды, для которых выполняется обратное условие Фано, называют постфиксными (постфикс или суффикс слова — это его конечный фрагмент). В этом случае тоже обеспечивается однозначное декодирование. Таким образом,
Сообщение декодируется однозначно, если для используемого кода выполняется прямое или обратное условие Фано.
Однозначно декодируемые коды
Пример 5. Рассмотрим код, предназначенный для кодирования сообщений, состоящих только из букв А, Б и В:
| А | Б | В | (5) |
|---|---|---|---|
| 0 | 11 | 010 |
Так как код буквы А (0) совпадает как с началом, так и с концом кода буквы В (010), для этого кода не выполняются ни прямое, ни обратное условие Фано. Поэтому пока мы не можем с уверенностью сказать, декодируется ли он однозначно.
Закодируем сообщение
и попытаемся раскодировать эту строку, используя код (5). В первую очередь, замечаем, что две соседние единицы могут появиться только при использовании буквы Б (код 11), поэтому сразу выделяем две таких группы:
Здесь жёлтым фоном выделена уже декодированная часть сообщения. В оставшейся части единица может появиться только в коде буквы В (010), в битовой строке находим две такие группы:
Оставшиеся нули — это коды букв А. Анализ алгоритма показывает, что такой код всегда однозначно декодируется.
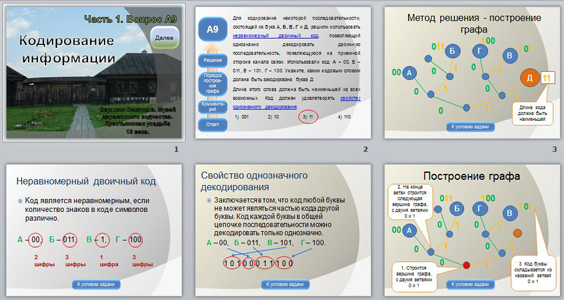
Полный ответ на вопрос об однозначной декодируемости получил в начале 1960-х годов советский математик Ал.А. Марков, предложивший решение с помощью графов [2]. Продемонстрируем его метод на примере.
Пример 6. Рассмотрим код
| А | Б | В | Г | Д | (6) |
|---|---|---|---|---|---|
| 01 | 010 | 011 | 11 | 101 |
Здесь не выполняется ни «прямое», ни «обратное» условие Фано, поэтому возможно, что декодировать сообщение однозначно не удастся. Но утверждать это заранее нельзя.


Код является однозначно декодируемым тогда и только тогда, когда в построенном таким образом графе нет ориентированных циклов, включающих вершину Λ.
Таким образом, код (6) не обладает свойством однозначной декодируемости.
Проверим таким же способом код (5), который, как мы уже выяснили, не является ни префиксным, ни постфиксным. Множество последовательностей, которые совпадают с началом и концом кодовых слов, состоит из пустой строки и единицы: <Λ, 1>. Граф, построенный с помощью приведённого выше алгоритма, содержит два узла и одну петлю:

В этом графе нет цикла, содержащего вершину Λ, поэтому любое сообщение, записанное с помощью такого кода, декодируется однозначно. Выше мы показали это с помощью простых рассуждений.
Нужно отметить, что на практике применяются, главным образом, префиксные коды, поскольку они позволяют декодировать сообщение по мере его получения, не дожидаясь окончания приёма данных.
Ещё примеры
Пример 7. Рассмотрим задачу А9 из демо-варианта КИМ ЕГЭ-2013 [1], которая сформулирована в начале статьи. Нужно оптимизировать код
выбрав один из вариантов
Решение. Сначала давайте посмотрим на исходный код, приведённый в условии. Можно заметить, что он префиксный — для него выполняется условие Фано: ни один из трехбитных кодов не начинается ни с 00 (код А), ни с 01 (код Б). Поэтому сообщения, закодированные с помощью такого кода, декодируются однозначно.
Заметим, что «обратное» условие Фано не выполняется: код буквы А (00) совпадает с окончанием кода буквы В (100), а код буквы Б (01) совпадает с окончанием кода буквы Г (101).
Теперь проверим, что получится, если сократить код буквы Д до 11 (вариант 1). Свойство однозначной декодируемости может быть потеряно только тогда, когда в результате такого сокращения нарушится условие Фано, то есть код буквы Д совпадёт с началом какого-то другого кодового слова. Видим, что этого не произошло — нет других кодовых слов, которые начинаются с 11, поэтому вариант 1 — это и есть верное решение.
Остается убедиться, что варианты 3 и 4 не подходят. Если мы сократим код буквы Г до 10 (вариант 3), условие Фано оказывается нарушенным, так как теперь код буквы Г (10) совпал с началом кода буквы В (100). Одновременно нарушено и «обратное» условие Фано: код буквы А (00) совпадает с окончанием кода буквы В (100). Но, как мы знаем, при этом код может всё-таки быть однозначно декодируемым.
Конечно, можно построить граф, как было сделано выше, и проверить, есть ли в нём циклы, включающие вершину Λ. В данном случае граф выглядит так:

Построение и анализ графа — дело достаточно трудоемкое и требующее аккуратности. Обычно в таких случаях значительно легче просто подобрать последовательность, которая может быть декодирована двумя разными способами.
Наконец, нужно убедиться, что вариант 4 не удовлетворяет условию. Если мы сократим код буквы Д до 10, условие Фано оказывается нарушенным, так как теперь код буквы Д (10) совпал с началом кода буквы В (100). Как и раньше, нарушено «обратное» условие Фано: код буквы А (00) совпадает с окончанием кода буквы В (100) и код буквы Б (01) совпадает с окончанием кода буквы Г (101).
Построим граф по методу Ал.А. Маркова:

Пример 8. Оптимизируйте код
сохранив свойство однозначной декодируемости сообщений. Выберите один из вариантов:
Решение. Определим, за счёт чего обеспечивается однозначная декодируемость исходного кода. Легко видеть, что код префиксный — для него выполняется условие Фано: ни одно из трёхбитовых кодовых слов не начинается ни с 11 (код А), ни с 10 (код Б). В то же время, обратное условие Фано не выполняется, потому что код буквы А (11) совпадает с окончанием кода буквы В (011).
Проверим вариант 1 — сократим код буквы Г до 00. При этом нарушилось условие Фано, которое обеспечивало однозначную декодируемость исходного варианта: теперь код буквы Г (00) совпадает с началом кода буквы Д (001). Но и обратное условие Фано тоже не выполняется для пары букв А-В. Поэтому можно предположить, что такой код не обладает свойством однозначной декодируемости. И действительно, легко находится цепочка 001011, которую можно раскодировать как ГБА (00 10 11) или ДВ (001 011).
Рассмотрим вариант 3 — сократим код буквы В до 01. При этом условие Фано выполняется, поскольку ни одно из кодовых слов не начинается с 01, то есть код является префиксным и однозначно раскодируется. Это и есть правильный ответ.
На всякий случай проверяем вариант 4 — сокращает код буквы Б до 1. При этом код перестает быть префиксным, и обратное условие Фано также не выполнено (код буквы Б совпадает с началом и концом кода буквы А). Сразу понятно, что последовательность 11 можно раскодировать как А или как ББ, поэтому этот вариант неверный.
Выводы
В заметке выполнен подробный анализ задачи на кодирование, которая предлагается на ЕГЭ в последние несколько лет. Нужно заметить, что в нём затрагивается вузовский курс дискретной математики. Понятно, что нельзя требовать от школьников знания теорем Ал.А. Маркова об однозначном декодировании, но учителю полезно более глубоко представлять себе эти вопросы, которые можно разбирать на факультативах. В качестве дополнительной литературы по этой теме можно рекомендовать 4.
С точки зрения практического подхода, для решения всех известных автору реальных задач подобного типа достаточно найти вариант, при котором выполняется условие Фано или обратное условие Фано (одно из двух!).
Литература
Комментарии: 16:
Спасибо, что «на пальцах» объяснили еще раз!
Действительно, спасибо. Очень понятно.
Просто великолепная статья!
Спасибо!
Уважаемый Константин! Бесконечно благодарна Вам за неоценимую помощь в подготовке детей к ЕГЭ по информатике.
Спасибо), всё понятно)))
Отличная статья! Спасибо!
Спасибо за статью. В учебнике информатики 10 класса Полякова содержится опечатка в последовательности построения графа Маркова, которая, при всей схожести текста, исправлена у вас. Порадовало также более ясное объяснение примеров.
> В учебнике информатики 10 класса Полякова содержится опечатка
Да, действительно была в первом издании. Сейчас исправлена.
Программа, скачанная отсюда, на codeTable = выдала следующий список вершин графа: [‘Lambda’, ‘0’, ‘1’].
Но разве ‘2’ не должна входит в список вершни, так как является началом ‘E’ и концом ‘C’ и не является кодовым словом?
> Но разве ‘2’ не должна входит в список вершин, так как является началом
> ‘E’ и концом ‘C’ и не является кодовым словом?
Программа предназначена только для обработки двоичных кодов.
А как можно доказать на пальцах, что из отсутствия данного граф-цикла следует однозначность декодируемости? А то зашел в учебник Маркова, а там просто жесть какая-то. Развитие моего ума не позволяет мне это изучить в разумные сроки.
Последний граф для кода А — 00, Б — 01, В — 100, Г — 101, Д — 10 составлен не совсем точно.
Нужно еще из вершины Λ в вершину 1 провести дугу Д → Г.
Подпишитесь на каналы Комментарии к сообщению [Atom]
 Константин Поляков Санкт-Петербург
Константин Поляков Санкт-Петербург
Кодирование информации
| Определение: |
| Кодирование информации (англ. information coding) — отображение данных на кодовые слова. |
Обычно в процессе кодирования информация преобразуется из формы, удобной для непосредственного использования, в форму, удобную для передачи, хранения или автоматической обработки. В более узком смысле кодированием информации называют представление информации в виде кода. Средством кодирования служит таблица соответствия знаковых систем, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем.
Содержание
Код [ править ]
Виды кодов [ править ]
Все вышеперечисленные коды являются однозначно декодируемыми — для такого кода любое слово, составленное из кодовых слов, можно декодировать только единственным способом.
Примеры кодов [ править ]
Однозначно декодируемый код [ править ]
| Определение: |
| Однозначно декодируемый код (англ. uniquely decodable code) — код, в котором любое слово составленное из кодовых слов можно декодировать только единственным способом. |
Пусть есть код заданный следующей кодовой таблицей:
[math]a_1 \rightarrow b_1[/math]
[math]a_2 \rightarrow b_2[/math]
[math]a_k \rightarrow b_k[/math]
Код является однозначно декодируемым, только тогда, когда для любых строк, составленных из кодовых слов, вида:
Всегда выполняются равенства:
Заметим, что если среди кодовых слов будут одинаковые, то однозначно декодировать этот код мы уже не сможем.
Префиксный код [ править ]
| Определение: |
| Префиксный код (англ. prefix code) — код, в котором никакое кодовое слово не является префиксом какого-то другого кодового слова. |
Предпочтение префиксным кодам отдается из-за того, что они упрощают декодирование. Поскольку никакое кодовое слово не выступает в роли префикса другого, кодовое слово, с которого начинается файл, определяется однозначно, как и все последующие кодовые слова.
Пример кодирования [ править ]
Закодируем строку [math]abacaba[/math] :
Такой код можно однозначно разбить на слова:
[math]00\ 01\ 00\ 1\ 00\ 01\ 00[/math]
Преимущества префиксных кодов [ править ]
Недостатки префиксных кодов [ править ]
Пример неудачного декодирования [ править ]
Предположим, что последовательность [math]abacaba[/math] из примера передалась неверно и стала:
[math]c^<**>(abacaba) = 0001001\ 1\ 00100[/math]
Разобьем ее согласно словарю:
[math] 00\ 01\ 00\ 1\ 1\ 00\ 1\ 00[/math]
[math]a\quad b\quad a\ c\ c\quad a\ c\ a[/math]
Полученная строка совпадает только в битах, которые находились до ошибочного, поэтому декодирование неравномерного кода, содержащего ошибки, может дать абсолютно неверные результаты.
Не префиксный однозначно декодируемый код [ править ]
Как уже было сказано, префиксный код всегда однозначно декодируем. Обратное в общем случае неверно:
Мы можем ее однозначно декодировать, так как знаем, что слева от двойки и справа от тройки всегда стоит единица.
После декодирования получаем: [math]abbca[/math]
А9. Кодирование информации

![]()
Описание разработки
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А – 00, Б – 011, В – 101, Г – 100. Укажите, каким кодовым словом должна быть закодирована буква Д. Длина этого слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования.
1) 001 2) 10 3) 11 4) 110
žКод является неравномерным, если количество знаков в коде символов различно.
Свойство однозначного декодирования зЗаключается в том, что код любой буквы не может являться частью кода другой буквы. Код каждой буквы в общей цепочке последовательности можно декодировать только однозначно.
Содержимое разработки

Верхняя Синячиха. Музей деревянного зодчества. Крестьянская усадьба

При кодировании информации неравномерным кодом однозначного декодирования можно добиться
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую. Каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Код состоит из определенного количества знаков (имеет определенную длину), которое называется длиной кода. Например, текстовое сообщение состоит из определенного количества букв, число — из определенного количества цифр.
Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием.
При кодировании один символ исходного сообщения может заменяться одним или несколькими символами нового кода, и наоборот — несколько символов исходного сообщения могут быть заменены одним символом в новом коде. Примером такой замены служат китайские иероглифы, которые обозначают целые слова и понятия.
Кодирование может быть равномерным и неравномерным. При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Примером неравномерного кодирования является код азбуки Морзе. Длительное время он использовался для передачи сообщений по телеграфу. Кодовый алфавит включал точку, тире и паузу. При передаче по телеграфу точка означала кратковременный сигнал, тире — сигнал в 3 раза длиннее. Между сигналами букв одного слова делалась пауза длительностью одной точки, между словами — длительностью трех точек, между предложениями — длительностью семи точек.
Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский.
Коды Морзе для некоторых букв.

Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов.
Декодирование информации
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно. Равномерные коды всегда могут быть декодированы однозначно.
Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов.
Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова.
Закодированное сообщение можно однозначно декодировать с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними.
Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Конспект урока по информатике «Кодирование и декодирование информации».



