style

Смотреть что такое «style» в других словарях:
stylé — stylé … Dictionnaire des rimes
STYLE — Sous l’égide de la linguistique, le style devient aujourd’hui l’objet d’une science: la stylistique veut être la science des registres de la langue, et elle s’efforce de définir le style comme concept opératoire. Mais le mot style a, dans l’usage … Encyclopédie Universelle
Style — may refer to:* Genre, a loose set of criteria for a category or composition * Design, the process of creating something * Format, various terms that refer to the style of different things * Human physical appearance * Fashion, a prevailing mode… … Wikipedia
style — [staɪl] noun [countable] 1. a way of doing something, designing something, or producing something, especially one that is typical of a particular time, place, or group of people: style of • the Japanese style of stock investment • 1980s style… … Financial and business terms
Style — Style, n. [OE. stile, F. style, Of. also stile, L. stilus a style or writing instrument, manner or writing, mode of expression; probably for stiglus, meaning, a pricking instrument, and akin to E. stick. See
style — Style, et maniere d escrire, Stylus, Vena. Style legier et doux, Oratio tenuis. Style de haut appareil, Magniloquentia. Qui n a pas style vulgaire, Cui non est publica vena. Le style, La practique, Iurisdictionis forma et vsus fori, Bud. Chose… … Thresor de la langue françoyse
stylé — stylé, ée 1. (sti lé, lée) adj. Terme d histoire naturelle. Qui est muni d un style, d un long style. stylé, ée 2. (sti lé, lée) part. passé de styler. • Tant ces nouveaux réformateurs avaient de peine à se contenter, et tant ils étaient peu… … Dictionnaire de la Langue Française d’Émile Littré
Style — 〈[ staıl] m. 6; engl. Bez. für〉 Stil * * * Style [sta̮il ], der; s, s [engl. style, über das Afrz. zu lat. stilus, ↑ Stil] (Jargon): Stil. * * * Style [»Stil«] Formatvorlage … Universal-Lexikon
style — [n1] fashion, manner appearance, approach, bearing, behavior, carriage, characteristic, cup of tea*, custom, cut*, description, design, druthers*, flash*, form, genre, groove*, habit, hand, idiosyncrasy, kind, method, mode, number, pattern,… … New thesaurus
-style — [ staıl ] suffix used with some adjectives and nouns to make adjectives describing someone s qualities or the way something is done or designed: a gangland style shooting an old style (=traditional) politician … Usage of the words and phrases in modern English
Как, где и зачем тренировать мышцы лица

Силовые тренировки для лицевых мышц или «фейс-фит» — мода последнего времени. Если о том, что спорт помогает поддерживать хорошую форму тела, знают все, то о сохранении молодости за счет «прокачки» мышц лица слышали немногие. Именно на этом специализируется студия Face Fit, которую основали в Москве Мария Фадеева и Елена Берштейн в конце 2018 года. За несколько недель до открытия их нового флагманского салона на Белорусской, разбираемся, как проходит такая тренировка и чем она отличается от обычного похода в фитнес-клуб.
«Фейс-фит» — это авторская методика лифтинг-массажа лица, которая, как утверждают ее создатели, позволяет вернуть молодость без инъекций и хирургии. Она направлена на борьбу с возрастными изменениями, формирование идеального овала лица, похудение и улучшение качества кожи. Один сеанс включает сразу несколько сложных техник: испанский скульптурирующий массаж, хиромассаж, буккальный и медовый массажи, миофасциальный, а также китайский с использованием неинвазивного роллера и гребней гуаша из натурального камня.
Каждого «спортсмена» в студии вместо обычного косметолога-массажиста встречает профессиональный «тренер» по прокачке лицевых мышц. Все специалисты, работающие в Face Fit, имеют специальное медицинское образование и прошли обучение за рубежом. Перед началом сеанса мастер подробно расспрашивает клиента о его пожеланиях, самочувствии, о хронических и острых заболеваниях, а также обязательно просит поставить в известность, если прежде в лицо вводились какие-либо инъекции. После осмотра определяются тип и состояние кожи, в зависимости от чего подбирается основа для массажа.
Киберпанк, который мы заслужили, или как Prisma превращает ваши селфи в произведение искусства

Привет, Хабр! Я Миша, R&D инженер в Prisma Labs. Наш отдел занимается разработкой новых фичей для мобильных приложений Prisma и Lensa. Prisma это AI-based фоторедактор, который по нажатию одной кнопки всего за пару секунд переносит художественный стиль с картин на ваши фотографии. Недавно мы решили расширить его функционал и дать пользователям возможность переносить стиль с портретов, нарисованных художниками, на свои селфи. В этом посте я расскажу про особенности задачи портретного Style Transfer, о существующих методах, которые мы попробовали, и о том, как адаптировали их под смартфоны.
Кто такой этот ваш Style Transfer?!
Чтобы мы с вами были на одной волне, я начну свой рассказ с небольшого описания задачи Style Transfer (ST) и обзора наиболее популярных подходов к её решению.
В общем случае, задача ST формулируется так: у нас есть фотография C и стилевое изображение S (например, это может быть картина маслом, диджитал арт и др.); мы хотим получить изображение, в котором “контент” из C (под контентом подразумевается всё что изображено на фотографии) будет нарисован в том же “стиле”, что и S (более строгое определение контента и стиля изображений можно найти тут).
Исследователи занимаются этой задачей уже давно, но широкую известность она получила в 2015 году, когда вышла статья Л. Гатиса, и др., в которой предложили ST на основе нейронных сетей (они на тот момент были на вершине своего хайпа). Вот так выглядит пайплайн метода:
 Пайплайн гатисовского ST [1]
Пайплайн гатисовского ST [1]
Верхнеуровнево этот метод можно описать так: значения пикселей картинки с шумом итеративно изменяются так, чтобы её дескрипторы (фичи) после каждой итерации приближались к дескрипторам стилевой и контентной картинок в терминах L2 нормы. На современных GPU весь процесс обычно занимает несколько минут.
Если вас не интересуют детали этого метода или вы уже знакомы с ним, можете смело читать дальше, остальным же – велкам под кат
До запуска итерационного процесса стилизации извлекаются дескрипторы контентного p и стилевого a изображений (для данной пары изображений это делается один раз). В качестве дескрипторов используются фичемапы (aka карты признаков) с разных слоёв свёрточной нейросети VGG-19, предобученной на датасете ImageNet.
Фичемапа на L-ом слое сети представляет собой тензор размерности  , где
, где  ,
, ,
, – количество фичемап, их высота и ширина соответственно. Фичемапы изображения сами по себе являются хорошими дескрипторами контента на изображении, но при этом они не подходят в качестве дескрипторов стиля. Поэтому фичемапы стилевого изображения сначала преобразуются в матрицы размерности
– количество фичемап, их высота и ширина соответственно. Фичемапы изображения сами по себе являются хорошими дескрипторами контента на изображении, но при этом они не подходят в качестве дескрипторов стиля. Поэтому фичемапы стилевого изображения сначала преобразуются в матрицы размерности  , а затем для каждой такой матрицы рассчитывается матрица Грама
, а затем для каждой такой матрицы рассчитывается матрица Грама  – матрица кросс-корреляций фичемап в слое L. Эти матрицы каким-то магическим образом содержат в себе всю необходимую информацию о стиле (на самом деле, существует объяснение, почему матрица Грама является хорошим дескриптором стиля).
– матрица кросс-корреляций фичемап в слое L. Эти матрицы каким-то магическим образом содержат в себе всю необходимую информацию о стиле (на самом деле, существует объяснение, почему матрица Грама является хорошим дескриптором стиля).
Перед началом первой итерации x (результат стилизации) инициализируется шумом. На каждом последующем шаге извлекаются его дескрипторы контента F и стиля G, рассчитываются расстояния от них до дескрипторов контентного и стилевого изображений соответственно:
 ,
, 
где  и
и – дескрипторы контента и стиля, извлечённые из x с k-ого слоя сети,
– дескрипторы контента и стиля, извлечённые из x с k-ого слоя сети,  и
и – дескрипторы контента и стиля, извлечённые из p и a соответственно. Целевой функцией будет взвешенная сумма таких расстояний:
– дескрипторы контента и стиля, извлечённые из p и a соответственно. Целевой функцией будет взвешенная сумма таких расстояний:

Методом обратного распространения ошибки (backpropagation) находим градиенты этой функции по значениям пикселей x, и “двигаем” значения х в направлении, противоположном найденному градиенту.
Повторяем эти шаги заданное количество итераций, или пока лосс не упадет ниже заданного значения. Силу наложения стиля можно регулировать, изменяя веса лоссов: хотим больше стиля – уменьшаем вес  или увеличиваем вес
или увеличиваем вес  .
.
При удачном подборе контентного и стилевого изображений, а также весов лоссов, можно получить впечатляющие результаты:
 Гатисовский Style Transfer в действии
Гатисовский Style Transfer в действии
Несмотря на это, гатисовский ST работает очень медленно – на GeForce GTX 1080 стилизация изображения в разрешении 1024х1024 занимает в среднем около минуты.
В 2016 году вышла работа Д. Джонсона и др., в которой предлагается первый real-time Style Transfer на нейросетях. Основная идея метода заключается в обучении под каждый стиль свёрточной нейронной сети с архитектурой вида энкодер-декодер с использованием функции потерь, предложенной Гатисом: 
Схема обучения нейросети для real-time Style Transfer [3]
Этот подход явно уступает гатисовскому ST в качестве, но по скорости заметно превосходит его (стилизация одного изображения занимает сотни миллисекунд), а значит, хорошо подходит для запуска на смартфонах. Именно этот метод и стал основой для нашего приложения Prisma.
В последующие годы вышло много работ, в которых предлагались те или иные улучшения метода Джонсона. Под катом перечислено несколько из них:
[AdaIN] – предлагают метод для “arbitrary style transfer” – это когда одна нейросеть умеет делать style transfer с произвольным стилем в real-time;
[WCT] – это тоже разновидность arbitrary style transfer, отличительной особенностью которого является улучшенное качество стилизаций и возможность регулировать силу переноса стиля даже после обучения сети;
[D&R] – по аналогии с Laplacian Pyramid авторы предложили многоуровневую архитектуру, состоящую из Drafting блока, который осуществляет стилизацию в низком разрешении 128х128, и нескольких Refinement блоков, последовательно увеличивающих разрешение до 512х512. По качеству стилизаций и времени инференса есть существенный буст по сравнению с AdaIn и WCT;
[UltraST] – в этой статье авторы оптимизировали AdaIN и WCT с помощью Knowledge Distillation, что позволило делать arbitraty style transfer в разрешении 10240 х 4096 (!).
Зачем нужно придумывать что-то ещё для портретов?
В процессе написания портрета художник обычно использует различные типы мазков и композиции цветов для лица, глаз и волос. От портретного Style Transfer пользователь, скорее всего, ожидает такого же локального переноса: чтобы кожа/глаза/губы на лице были нарисованы так же, как соответствующие им части на стилевом портрете. Однако, методы, про которые я рассказал, в большинстве случаев выдают совсем не то, что мы ожидаем:
Ожидание vs. Реальность
Так происходит, потому что в этих методах при стилизации не используется какой-либо априорной информации о соответствии различных семантических частей контентного и стилевого изображений, поэтому стиль, в котором нарисованы волосы, может перенестись не только на волосы, но и куда-то ещё (что, собственно, и произошло на примере выше).
Попытки установить такое соответствие по фичемапам нейросети (например, посчитав для каждой фичемапы 4D тензор корреляций) в большинстве случаев не приводят к желаемому эффекту. Одна из потенциальных причин кроется в том, что используемая нейросеть обучалась на задаче классификации, и поэтому она извлекает те признаки изображения, по которым его можно отнести к одному из классов. Кроме того, при обучении использовался датасет ImageNet, в котором нет ни человеческих лиц, ни тем более художественных портретов. Поэтому нет каких-либо гарантий, что извлекаемые нейросетью признаки будут содержать информацию о семантических частях лица, которая нам нужна для установления соответствия между контентным и стилевым лицами.
Может возникнуть резонный вопрос: а что будет, если мы обучим сетку для face segmentation/face recognition, возьмём её энкодер и заменим им VGG в гатисовском ST? На самом деле, этот вопрос открытый, я лично пока не видел ни одной работы, в которой это исследовали.
Существует несколько хороших статей на тему того, как заметно бустануть качество портретного ST, используя априорное знание о соответствии между лицом на фотографии и лицом на стилевом портрете. Далее я расскажу вам о тех методах, которые мы реализовали и протестировали, и о том, что в итоге из этого вышло.
Кодируем информацию о стиле в фичемапах контентного изображения
В статье авторы предлагают модифицировать гатисовский метод для работы с портретами. Их пайплайн выглядит так:
Пайплайн описанного метода [6]
Алгоритм состоит из двух этапов – генерация (Stage A) и опциональный пост-процессинг стилизованного изображения (Stage B).
Отличие от гатисовского ST заключается в следующем. В предложенном пайплайне фичи контентного изображения преобразуются так, чтобы в них помимо информации о контентном изображении также содержалась информация о локальном распределении цвета и текстур в стилевой картинке. С таким подходом Content Loss форсит не только сохранение контента, но и локальный перенос стиля:
Локальный перенос стиля на пальцах: мы хотим, чтобы правая часть лица девушки была нарисована в светлых тонах, а левая – в темных, так же как на стилевом портрете [6] Более подробное описание метода
Формально преобразование фичей контентного изображения можно записать так:
 ,
,
 ,
,
 ,
,
где  ,
,  – фичемапы контентного и стилевого изображений на L-ом слое,
– фичемапы контентного и стилевого изображений на L-ом слое,  – модифицированные фичемапы,
– модифицированные фичемапы,  – “gain map”, который показывает, как соотносятся активации стилевой и контентной фичемап.
– “gain map”, который показывает, как соотносятся активации стилевой и контентной фичемап.
Пример визуализации исходных и преобразованных фичемап, а также gain maps:
В описанном выше преобразовании фичемап предполагается, что лица на контентном и стилевом изображениях выровнены. Реальные же фотографии могут отличаться от стилевой картинки ракурсом и углом поворота головы, поэтому до начала процесса стилизации стилевое и контентное изображения выравниваются – текстура лица на стилевом изображении “натягивается” на лицо c контентного изображения. Авторы предлагают делать выравнивание по 68 лендмаркам лица комбинацией методов Image Morphing и SIFT-Flow.
Инсайд про более простой и быстрый подход к выравниванию
В своей реализации мы использовали альтернативный, более быстрый подход:
Считаем векторы смещений между соответствующими лендмарками стилевого и контентного изображений;
Значения сдвигов для остальных точек сетки находим путём интерполяции, получаем flow field F, в котором F(x, y) – вектор, показывающий откуда взять пиксель (x, y) в стилевом изображении;
Делаем warping стилевого изображения по F.
Результат выравнивания выглядит немного крипово:
 Результат выравнивания стилевого изображения по контентному
Результат выравнивания стилевого изображения по контентному
Вот так выглядят фотографии, стилизованные нашей реализацией этого метода:
 Наши результаты
Наши результаты
При сравнении полученных стилизаций с результатами гатисовского ST становится особенно заметно, что рассматриваемый метод более “осознанно” и натурально переносит стиль в области лица (на первом и третьем стилях это видно невооружённым глазом):
 Сравнение портретного ST (первая строка) с гатисовским ST (вторая строка) на одном контентном изображении
Сравнение портретного ST (первая строка) с гатисовским ST (вторая строка) на одном контентном изображении
Теперь перейдем к недостаткам этого метода. Прежде всего, есть проблема с переносом высокочастотных стилевых деталей. Например, здесь алгоритм не смог перенести текстуру полотна:

В данном случае, конечно, эту проблему можно решить блендингом результата с похожей текстурой, но если у нас какой-нибудь карандашный стиль, это не поможет.
На фотографиях с сильно повёрнутыми лицами алгоритм выравнивания работает плохо, отчего появляются нежелательные артефакты:

Ещё одна проблема этого метода заключается в том, что на одних фотографиях он может выдавать хорошие результаты, а на других артефачить (при одинаковых гиперпараметрах):

Если есть сильные отличия по размеру лица, причёске и другим атрибутам между лицами на контентном и стилевом изображениях, возникает ghosting артефакт (когда часть стилевого изображения попадает на результат):
 Пример ghosting артефакта – в данном случае плечо и волосы со стилевого портрета попали на задний фон стилизованного [6] Последнюю проблему авторы предлагают фиксить пост-процессингом (Stage B):
Пример ghosting артефакта – в данном случае плечо и волосы со стилевого портрета попали на задний фон стилизованного [6] Последнюю проблему авторы предлагают фиксить пост-процессингом (Stage B):
Генерируем фоновое изображение
Вычисляем маску маттинга фигуры человека на контентном изображении
По найденной маске вставляем стилизованное изображение на сгенерированный фон
В целом, это решает проблему, но в этом случае мы полностью теряем фон, что может не понравиться нашим пользователям.
Ну и нельзя не отметить, что этот метод работает не быстрее гатисовского ST, плюс, перед каждым запуском процесса стилизации нужно выравнивать стиль по контенту.
Нейросети? Не, не слышали!
Наверняка у многих, кто дочитал до этих строк, сложилось впечатление, что придумать что-то лучше нейронок для задачи портретного ST нельзя. Поспешу вас в этом разубедить.
В 2001 году придумали метод Image Analogies, который с данной пары изображений “до/после применения фильтров” умеет переносить эффект наложенных фильтров (по аналогии с имеющимся примером “до/после” наложения фильтра) на любое другое изображение:
Визуализация концепта Image Analogies. A и A’ исходное изображение до и после наложения фильтра (в данном случае фильтр представляет собой эффект акварели), B – изображение, на которое будет перенесён эффект фильтра, B’ – результат переноса [7]
Image Analogies работает примерно так:
Строится NNF(A, B) (Nearest Neighbour Field) – маппинг  , который каждому пикселю q из B ставит в соответствие ближайший (в терминах некоторого функционала) пиксель p из A; так как между A и A’, B и B’ есть прямое соответствие, можно положить NNF(A’, B’) = NNF(A, B);
, который каждому пикселю q из B ставит в соответствие ближайший (в терминах некоторого функционала) пиксель p из A; так как между A и A’, B и B’ есть прямое соответствие, можно положить NNF(A’, B’) = NNF(A, B);
Для построения NNF нужно уметь сравнивать пиксели изображений A и B между собой. Для этого используются различные дескрипторы пикселей. В самом простом случае, дескриптором пикселя могут быть его RGB значения, но из-за своей “низкоуровневости” такой дескриптор малоинформативен и чаще всего его использование приводит к плохому NNF. Поэтому авторы предложили помимо RGB значений использовать результаты применения steerable фильтров к изображениям A и B. По извлеченным дескрипторам близость двух пикселей из A и B (а, следовательно, и из A’ и B’) оценивается как L2 норма разницы соответствующих дескрипторов. Чтобы ускорить поиск ближайшего соседа для каждого пикселя, можно использовать приближенные методы поиска ближайших соседей.
Более подробное описание алгоритма Image Analogies
На вход алгоритму даются дескрипторы двух изображений A и B, а также стилизованная версия первого изображения, A’. Дескрипторы представляют из себя трёхмерные тензоры размерности H x W x C, где H, W – высота и ширина изображения, а C – размерность дескриптора. Таким образом, любой пиксель с координатой u изображения I будет описываться вектором I'[u] размерности C, а патч радиуса r с центром в u – сконкатенированными дескрипторами соседей u в радиусе r.
Для каждого дескриптора обоих изображений вычисляется Гауссовская пирамида.
Стилизация начинается с самого высокого уровня Гауссовской пирамиды. На уровне L дескрипторами пикселя u выступают дескрипторы соответствующего патча размером 5х5, а также дескрипторы патча u размера 3х3 с предыдущего уровня L-1. Последующие шаги описаны для одного уровня.
Для каждого пикселя q в B’ ищется ближайший ему пиксель p в A’. В качестве меры близости патчей p и q используется следующий функционал:

где  – составляющая, которая минимизируется на более согласованных патчах p и q (то есть когда у патчей близкие RGB значения), а
– составляющая, которая минимизируется на более согласованных патчах p и q (то есть когда у патчей близкие RGB значения), а  – составляющая, которая минимизируется на пикселях с похожими дескрипторами. Стоит отметить, что
– составляющая, которая минимизируется на пикселях с похожими дескрипторами. Стоит отметить, что  на уровне L рассчитывается только по уже сгенерированным пикселям B’.
на уровне L рассчитывается только по уже сгенерированным пикселям B’.
Таким образом, ближайший сосед пикселя q из B’, p* находится как:

Шаг 4 повторяется до тех пор, пока для всех пикселей в B’ не будут найдены соседи. В конце этого шага получаем NNF.
По полученному NNF восстанавливается B’.
Шаги 3-6 повторяются на следующем скейле.
Пример кода на Python :
В последующие годы появилось много работ, в которых предлагались различные варианты улучшения дескрипторов и методов построения NNF. Из них хотелось бы выделить работу StyLit, в которой авторы применяют Image Analogies для стилизации трёхмерных моделей. В качестве дескрипторов предлагается использовать RGB и LPE (Light Paths Expressions) тензоры. LPE описывают распространение света в данной 3D сцене и за счёт этого позволяют получить более реалистичную стилизацию, которая больше похожа на рисунок от руки художника.
Вот так выглядит StyLit в терминах Image Analogies [8] Также в этой работе предложили улучшение алгоритма расчёта NNF, использовавшегося в Image Analogies
В Image Analogies используется жадный алгоритм, который плохо справляется со стилизацией высокоуровневых структур. Поэтому в StyLit предложили минимизировать  , делая несколько итераций EM алгоритма:
, делая несколько итераций EM алгоритма:
Псевдокод одной итерации EM алгоритма [8]
В первом цикле создается NNF для стилизованного изображения B’ с предыдущей итерации. Далее по полученному NNF рассчитываются значения пикселей стилевого изображения B’ путем усреднения значений соответствующих пикселей в соседних патчах.
Авторы также отмечают, что использование этого алгоритма в его исходном виде, приводит к размытым результатам. Они объясняют эту проблему тем, что в этом алгоритме никак не форсится равномерное использование патчей стилевого изображения. В своей статье они также описывают механизм, позволяющий решить эту проблему.
В 2017 StyLit был адаптирован для задачи портретного ST и переименован в FaceStyle. В FaceStyle предложили использовать специфичные для лиц дескрипторы:
Дескрипторы FaceStyle [9]
Расскажу о них подробнее. Gseg (segmentation guidance) задает соответствие между семантическими участками лиц на контентном и стилевом изображениях. Иными словами, не даёт алгоритму стилизации копировать патчи с бровей стилевого лица и вставлять их на лоб контентного лица. Для получения маски лица и волос авторы используют аналитический маттинг со своими модификациями (подробности в статье). Маски бровей, глаз, носа, губ и рта рисуют по 68 лендмаркам лица. Дескриптор Gseg представляет из себя RGB картинку, в котором каждая семантическая часть лица закодирована своим цветом.
На первый взгляд может показаться, что одного Gseg может быть вполне достаточно, чтобы получить хорошую стилизацию, но это не так. Например, по Gseg нельзя отличить правую часть лица от левой, а иногда это может быть полезным. Для того чтобы локализовать перенос, авторы предлагают использовать Gpos (positional guidance) – для контентного изображения это по сути грубый NNF, построенный по лицевым лендмаркам, для стилевого – identity NNF (в каждом пикселе закодированы координаты этого пикселя). Для расчёта Gpos авторы используют метод Moving Least Squares Deformation, натравленный на лендмарки. Мы в своей реализации для получения этого дескриптора использовали подход к выравниванию лиц, описанный в предыдущей главе.
Ни Gseg, ни Gpos никак не форсят сохранение контента на стилизованной фотографии, поэтому нужен ещё один дескриптор – Gapp (appearence guidance). Gapp стиля – это просто стилевое изображение, преобразованное в grayscale. Сделать то же самое для контентного изображения нельзя, потому что, если на нем будет присутствовать тень/блик, это обязательно проявится в виде артефакта на стилизованном изображении. Поэтому авторы сначала выравнивают локальный контраст и интенсивность контентного и стилевого изображений, используя метод переноса стиля с одного портретного фото на другое – ST for Headshot Portraits, а уже затем используют полученное контентное изображение с выровненным контрастом в качестве дескриптора. Существует и более быстрый способ получения этого дескриптора:
посчитать первый уровень Laplacian Pyramid (LP) для контента и стиля;
выровнять гистограмму полученного LP контента по LP стиля;
полученные LP использовать в качестве Gapp.
Если визулизировать FaceStyle в концепции Image Analogies, получится что-то такое:
 Визуализация FaceStyle как разновидности метода Image Analogies. Здесь A и B – извлечённые дескрипторы (Gapp, Gseg, Gpos) со стилевого (source) и контентного (target) изображений
Визуализация FaceStyle как разновидности метода Image Analogies. Здесь A и B – извлечённые дескрипторы (Gapp, Gseg, Gpos) со стилевого (source) и контентного (target) изображений
Стилизации, которые мы получили, этим методом, лишены недостатков предыдущего метода портретного ST и выглядят без преувеличения очень круто:
 Результаты FaceStyle
Результаты FaceStyle
 Фейл кейсы FaceStyle
Фейл кейсы FaceStyle
Также можно заметить, что FaceStyle не использует дескрипторы для чего-то кроме лица. Соответственно, всё, что находится вне маски лица, стилизуется не так, как мы ожидаем. Мы решили расширить дескриптор Gseg, путем добавления маски шеи и тела, при этом нам на сдачу добавилась маска бэкграунда. Но это не всегда даёт хорошие результаты (примеры в первых двух столбцах на картинке выше). Придумать тут что-то более умное довольно-таки трудно, хотя попытки предпринимались.
Ещё одна слабая сторона FaceStyle – это длительность стилизации. При условии, что все дескрипторы предпосчитаны, стилизация одного изображения в разрешении 1024х1024 у нас занимает около 25с на Intel(R) Xeon(R) CPU E5-2620. На смартфоне, соответственно, будет ещё дольше (помним, что нам нужно будет также считать дескрипторы).
Distillation is my profession
Все рассмотренные выше методы ST для портретов итеративные и далеки от real-time даже на современных десктопных CPU/GPU. Как же ускорить медленный итеративный алгоритм, который умеет генерировать пары source-stylized images хорошего качества? Правильно, дистиллировать его нейросетями!
Генерируем датасет пар изображений в выбранном стиле;
Учим на полученном датасете image-to-image сетку;
Сейчас этот подход довольно-таки популярный, особенно среди любителей StyleGAN (вот, например, статья с ECCV 2020). Есть даже работа, в которой авторы дистиллировали FaceStyle. Далее расскажу вкратце про основные идеи из неё.
В качестве генератора использовали нейросеть архитектуры энкодер-декодер из работы Real-time Style Transfer, модифицировав её следующим образом:
добавили skip connections с выходов слоёв энкодера к соответствующим слоям декодера;
увеличили количество residual блоков;
добавили дополнительный свёрточный слой на выходе декодера.
Архитектура генератора для дистилляции FaceStyle (слева – исходная архитектура, справа – после модификаций) [12]
В качестве лосса использовали взвешенную сумму:
adversarial лосса на основе PatchGAN
попиксельного L1 лосса между выходом сети и ground truth
На Nvidia RTX 2080 Ti такой генератор работает под 15 FPS на изображениях 512х512, что вполне можно считать real-time. Помимо прироста в скорости, на сдачу сетка ещё и бустанула качество стилизаций на сложных кейсах – генератор неплохо справляется там, где косячил FaceStyle:
 Примеры кейсов, на которых дистилляция фиксит проблемы FaceStyle [12]
Примеры кейсов, на которых дистилляция фиксит проблемы FaceStyle [12]
Скорее всего, магия происходит потому, что в обучающем сете большая часть изображений стилизована без артефактов и, благодаря этому, нейросеть хорошо выучивает какую-то “среднюю” стилизацию, которая на большинстве сэмплов работает адекватно.
На простых кейсах стилизации FaceStyle выглядят более чётко по сравнению с результатами дистилляции – в первом случае стилизованное изображение “собирается” из патчей стилевого, что позволяет сохранить все художественные детали; нейросеть же – параметрическая модель, которая ввиду ограниченного количества параметров может лишь аппроксимировать маппинг между исходными изображениями и таргетами:
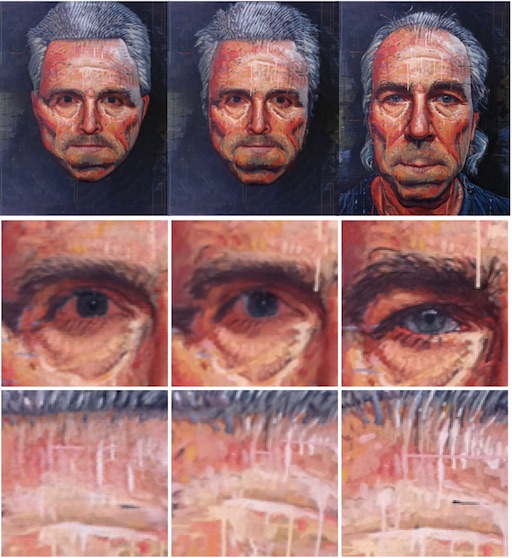 Сравнение качества детализации. Слева направо: результат дистилляции, результат FaceStyle, стилевое изображение [12]
Сравнение качества детализации. Слева направо: результат дистилляции, результат FaceStyle, стилевое изображение [12]
Но с этим недостатком можно смириться, потому что чаще всего косяки в детализации не так заметны.
Как мы затаскивали это всё на смартфон
Нам предстояло решить две задачи:
оптимизировать архитектуру генератора так, чтобы он отрабатывал на смартфонах за адекватное время;
увеличить разрешение до 1024х1024.
С одной стороны, нужно было сделать генератор более mobile-friendly, и при этом сохранить совместимость с фреймворками инференса нейросетей на смартфонах (CoreML, ONNX, TFLite); c другой – сохранить качество результатов на уровне большого генератора. Мы решили взять за основу архитектуру нейросети, которая раньше использовалась у нас в сегментации фона на портретных фотографиях:
Архитектура нейросети для сегментации бэкграунда на портретных фото
По сути, это всё тот же энкодер-декодер со skip-connections, что использовали авторы для дистилляции FaceStyle, но со следующими модификациями:
В residual блоках используются separable свёрточные слои вместо обычных – они выполняют практически ту же работу, что и обычные свёртки, только за меньшее количество операций и требуют меньше памяти.
В качестве basic блока используется не Conv + ReLU слой, а целый residual блок.
Вместо конкатенации выходов слоёв энкодера с выходами слоёв декодера используется поэлементное сложение – это ускоряет сходимость и улучшает качество результатов.
Мы адаптировали эту архитектуру под нашу задачу следующим образом:
Сделали энкодер более глубоким;
Увеличили разрешение входного изображения до 512х512;
Добавили Instance Normalization слои (без них сетка сильно артефачит);
Сделали энкодер и декодер симметричными (одинаковое количество residual блоков на соответствующих слоях);
Заменили Transposed Conv слои на Upsample + Conv (про мотивацию можно почитать тут).
При обучении мы так же использовали PatchGAN лосс, поэтому нужно было ещё и правильно подобрать дискриминатор к оптимизированному генератору. Для этого мы уменьшили количество фичемап в исходном дискриминаторе и добавили Spectral Normalization во все свёрточные слои.
С тяжелым генератором разобрались, осталось решить проблему с разрешением. Для этого мы использовали модифицированный ESRGAN, увеличивающий разрешение входного изображения в 2 раза. Учили его на кропах изображений, стилизованных обученной ST сеткой, в качестве ground truth использовались результаты FaceStyle.
В итоге весь пайплайн получился довольно-таки лёгким (  Portrait ST в нашем приложении
Portrait ST в нашем приложении
Сейчас у нас в проде есть четыре портретных ST фильтра: Leya, Aqua, Michael и Arturo, с которыми вы можете поиграться. На этом мы решили не останавливаться, поэтому в ближайшее время подъедет ещё больше фильтров. Следите за апдейтами;)



