Файл формата SQLITE открывается специальными программами. Чтобы открыть данный формат, скачайте одну из предложенных программ.
Чем открыть файл в формате SQLITE
Расширение SQLITE (полн. SQLite Database File) представляет собой базу данных, являющуюся результатом генерации SQLite. SQLite – самостоятельная, интегрированная система управления базами данных (СУБД), функционирование которой обеспечивается в автономном режиме.
По своей сути, SQLITE формат – это структурированный набор данных в виде электронных таблиц с определенными записями, полями и типами данных. Доступ, контроль и управление СУБД реализованы посредством встроенных команд SQL, доступных в любой системе, поддерживающей SQLite.
Библиотека SQLite находится в свободном доступе и может быть адаптирована под многообразные программные приложения и языки программирования.
SQLITE формат распознают большинство автоматизированных комплексов Autodesk, а также геопространственный софт.
Программы для открытия SQLITE файлов
SQLITE расширение не прихотливо к платформе конкретной операционной системы и одинаково успешно может функционировать на базе ОС Windows, Mac и Linux.
Чтобы открыть SQLITE файл в ОС Windows принято использовать:
На базе ОС Mac SQLITE будет доступен с применением все тех же программных плагинов SQLite, Sqliteman и SQLite Database Browser.
Для того, чтобы воспроизвести расширение в ОС Linux необходимо использовать MapGuide Open Source, SQLite и Sqliteman.
В случае если при воспроизведении формата возникает ошибка: либо поврежден или заражен исходный файл, либо осуществляется открытие SQLITE файла с применением некорректной программной утилиты.
Конвертация SQLITE в другие форматы
Уникальная структура и область применения SQLITE для каждого конкретного случая не предоставляют возможностей для конвертации данного формата в другие расширения. Попытки конвертации расширения в другой формат могут не только не дать никаких практических результатов, но и повредить исходный файл. В этой связи трансляция данного формата не практикуется.
Почему именно SQLITE и в чем его достоинства?
Приходится констатировать, что SQLITE расширение не является столь популярным и востребованным форматом среди обычных пользователей. Однако без его наличия трудно представить корректную организацию систем управления базами данных (СУБД) на базе SQLite, а также хранение записей в виде электронных таблиц.
База данных, создающаяся с помощью SQLite — автономной встроенной системы управления базами данных (DBMS). Хранит данные в таблицах, каждая из которых может содержать различные поля и типы данных. Доступ к ней можно получить с помощью команд SQL при помощи любой системы, поддерживающей SQLite.
Библиотека SQLite доступна в бесплатном формате и поддерживается различными программами и языками программирования. Файлы SQLITE распознаются инфраструктурой Autodesk и геопространственными продуктами.
Чем открыть файл в формате SQLITE (SQLite Database File)
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
SQLite
SQLite — это встраиваемая кроссплатформенная БД, которая поддерживает достаточно полный набор команд SQL и доступна в исходных кодах (на языке C).
Содержание
Общее
SQLite – это встраиваемая библиотека в которой реализовано многое из стандарта SQL 92. Её притязанием на известность является как собственно сам движок базы, так и её интерфейс (точнее его движок) в пределах одной библиотеки, а также возможность хранить все данные в одном файле. Позиция функциональности SQLite где-то между MySQL и PostgreSQL. Однако, на практике, SQLite нередко оказывается в 2-3 раза (и даже больше) быстрее. Такое возможно благодаря высокоупорядоченной внутренней архитектуре и устранению необходимости в соединениях типа «» target=»_blank»>сервер-клиент» и «клиент-» target=»_blank»>сервер».
Всё это, собранное в один пакет, лишь немногим больше по размеру клиентской части библиотеки MySQL, является впечатляющим достижением для полноценной базы данных. Используя высоко эффективную инфраструктуру, SQLite может работать в крошечном объёме выделяемой для неё памяти, гораздо меньшем, чем в любых других системах БД. Это делает SQLite очень удобным инструментом с возможностью использования практически в любых задачах возлагаемых на базу данных.
Преимущества
Недостатки
SQLite поддерживает динамическое типизирование данных.
Возможные типы полей
Архитектура
Движок БД представляет библиотеку, с которой программа компонуется и SQLite становится составной частью программы. Вся БД хранится в единственном стандартном файле на машине, на которой исполняется программа.
Несколько процессов или потоков могут одновременно без каких-либо проблем читать данные из одной базы. Запись в базу можно осуществить только в том случае, если никаких других запросов в данный момент не обслуживается; в противном случае попытка записи оканчивается неудачей, и в программу возвращается код ошибки. Другим вариантом развития событий является автоматическое повторение попыток записи в течение заданного интервала времени.
Особенности
Эта часть является собранием всевозможных особенностей SQLite, без понимания которых невозможно постичь SQLite.
Использование SQLite в многопоточных приложениях
SQLite может быть собран в однопоточном варианте (параметр компиляции SQLITE_THREADSAFE = 0 ). В этом варианте его нельзя одновременно использовать из нескольких потоков, поскольку полностью отсутствует код синхронизации. Проверить, есть ли многопоточность можно через вызов sqlite3_threadsafe(): если вернула 0, то это однопоточный SQLite. По умолчанию, SQLite собран с поддержкой потоков (sqlite3.dll). Есть два способа использования многопоточного SQLite: serialized и multi-thread.
Serialized (надо указать флаг SQLITE_OPEN_FULLMUTEX при открытии соединения). В этом режиме потоки могут как угодно дергать вызовы SQLite, никаких ограничений. Но все вызовы блокируют друг друга и обрабатываются строго последовательно.
Multi-thread ( SQLITE_OPEN_NOMUTEX ). В этом режиме нельзя использовать одно и то же соединение одновременно из нескольких потоков (но допускается одновременное использование разных соединений разными потоками). Обычно используется именно этот режим.
Формат данных
База данных SQLite может хранить (текстовые) данные в UTF-8 или UTF-16. Набор вызовов API состоит из вызовов, которые получают UTF-8 (sqlite3_XXX) и вызовов, которые получают UTF-16 (sqlite3_XXX16). Если тип данных интерфейса и соединения не совпадает, то выполняется конвертация «на лету».
Поддержка UNICODE
Немного про работу ICU и SQLite.
Порядок сортировки значений разных типов:
SQLite выполняет неявные преобразования типов «на лету» в нескольких местах:
Значения BLOB и NULL всегда заносятся в любой столбец «как есть».
При сравнении значений разного типа между собой может выполняться дополнительное преобразование типов.
При сравнении числа со строкой, если строка может быть преобразована в число «без потерь», она становится числом.
В SQLite в уникальном индексе может быть сколько угодно NULL значений (с этим согласен Oracle и не согласен MS SQL).
Если в вызове sqlite3_open() передать имя файла как «:memory:», то SQLite создаст соединение к новой (чистой) БД в памяти. Это соединение абсолютно неотличимо от соединения к БД в файле по логике использования: доступен тот же набор SQL команд. Сейчас это исправлено и можно открыть два соединения к одной БД в памяти.
Теперь все таблицы БД в файле db1.sqlite3 стали прозрачно доступны в нашем соединении. Для разрешения конфликтов имен следует использовать имя присоединения (основная база называется «main»):
Ничего не мешает присоединить к БД новую базу в памяти и использовать ее для кэширования и пр.
Передайте пустую строку вместо имени файла в sqlite3_open() и будет создана временная БД в файле на диске. Причем, после закрытия соединения к БД, она будет удалена с диска.
SQL команда PRAGMA служит для задания всевозможных настроек у соединения или у самой БД:
Настройку соединения (очевидно) следует проводить сразу после открытия и до его использования.
Журнал и фиксация транзакций
50 в секунду. Именно поэтому, не получается вставлять записи быстро, используя неявную транзакцию.
При настройках по умолчанию SQLite гарантирует целостность БД даже при отключении питания в процессе работы. Достигается подобное изумительное поведение ведением журнала (специального файла) и хитроумным механизмом синхронизации изменений на диске. Обновление данных в БД работает так:
— до любой модификации БД SQLite сохраняет изменяемые страницы из БД в отдельном файле (журнале), то есть просто копирует их туда; — убедившись, что копия страниц создана, SQLite начинает менять БД; — убедившись, что все изменения в БД «дошли до диска» и БД стала целостной, SQLite стирает журнал.
PRAGMA journal_mode = DELETE
Это означает, что файл журнала удаляется после завершения транзакции. Сам факт наличия файла с журналом в этом режиме означает для SQLite, что транзакция не была завершена, база нуждается в восстановлении. Файл журнала имеет имя файла БД, к которому добавлено «-journal».
В режиме TRUNCATE файл журнала обрезается до нуля (на некоторых системах это работает быстрее, чем удаление файла).
В режиме PERSIST начало файла журнала забивается нулями (при этом его размер не меняется и он может занимать кучу места).
В режиме MEMORY файл журнала ведется в памяти и это работает быстро, но не гарантирует восстановление базы при сбоях (копии данных-то нету на диске).
Мы знаем, что современные системы используют хитроумное кэширование для повышения производительности и могут откладывать запись на диск. Допустим, SQLite завершил запись в БД и хочет стереть файл журнала, чтобы отметить факт фиксации транзакции. Если в этот промежуток времени отключится питание, то журнала уже не будет, а БД еще не будет целостной — потеря данных!
PRAGMA synchronous задает степень «паранойи» SQLite на это счет.
Режим OFF (или 0) означает: SQLite считает, что данные фиксированы на диске сразу после того как он передал их ОС (то есть сразу после вызова соот-го API ОС). Это означает, что целостность гарантирована при аварии приложения (поскольку ОС продолжает работать), но не при аварии ОС или отключении питания.
Режим синхронизации NORMAL (или 1) гарантирует целостность при авариях ОС и почти при всех отключениях питания. Существует ненулевой шанс, что при потере питания в самый неподходящий момент база испортится. Это некий средний, компромисный режим по производительности и надежности.
Режим FULL гарантирует целостность всегда и везде и при любых авариях. Но работает, разумеется, медленнее, поскольку в определенных местах делаются паузы ожидания. И это режим по умолчанию.
Режим журнала WAL
Режим журнала WAL работает иначе — он «постоянный». Как только мы перевели базу в режим WAL, она останется в этом режиме, пока ей явно не поменяют режим журнала на другой.
Изначально SQLite проектировалась как встроенная БД. Архитектура разделения одновременного доступа к данным была устроена примитивно: одновременно несколько соединений могут читать БД, а вот записывать в данный момент времени может только одно соединение. Это, как минимум, означает, что пишущее соединение ждет «освобождения» БД от читающих. При попытке записать в «занятую» БД приложение получает ошибку SQLITE_BUSY (не путать с SQLITE_LOCKED!). Достигается этот механизм разделения доступа через API блокировки файлов (которые плохо работают на сетевых дисках, поэтому там не рекомендуется использовать SQLite; узнать больше )
В режиме WAL (Write-Ahead Logging) «читатели» БД и «писатели» в БД уже не мешают друг другу, то есть допускается модификация данных при одновременном чтении. Короче говоря, это шаг в сторону больших и серьезных СУБД, в которых все так и есть. Утверждается также, что SQLite в WAL работает быстрее.
Но есть и недостатки: — требуется некоторые дополнительные ништяки от ОС (unix и Windows имеют эти ништяки); — БД занимает несколько файлов (файлы «XXX-wal» и «XXX-shm»); — плохо работает на больших транзакциях (условно, если транзакция больше 50 Мбайт); — нельзя открыть такую БД в режиме «только чтение»; — возникает дополнительная операция checkpoint.
Фактически, в режиме WAL данные БД разделяются между БД и файлом журнала. Операция checkpoint переносит данные в БД. По умолчанию, это делается автоматически, если журнал занял 1000 страниц БД. То есть, идут быстрые COMMIT-ы и вдруг какой-то COMMIT задумался и начал делать checkpoint. Если такое поведение нежелательно, можно делать checkpoint вручную (когда все спокойно), можно это делать и в отдельном процессе.
Пределы
Несмотря на миниатюрность, SQLite в реальности не накладывает серьезных ограничений на размеры полей, таблиц или БД.
По умолчанию, BLOB или строкое значение могут занимать 1 Гбайт и это же ограничение размера одной записи (можно поднять до 2^31 — 1, параметр SQLITE_MAX_LENGTH ).
Количество столбцов: 2000 (можно поднять до 32767, SQLITE_MAX_COLUMN ).
Размер SQL оператора: 1 МБайт (1073741824 байт, SQLITE_MAX_SQL_LENGTH ).
Одновременный join: 64 таблицы.
Присоединить баз к соединению: 10 (до 62, SQLITE_MAX_ATTACHED )
Максимальное количество страниц в БД: 1073741823 (до 2147483646, SQLITE_MAX_PAGE_COUNT ).
Если задать размер страницы 65636 байт, то максимальный размер БД будет примерно 14 Терабайт.
Максимальное число записей в таблице: 2^64 — 1, но на практике, конечно, ограничение размера вступит раньше.
Пример
Использование
Автоматическое резервирование
Пример скрипта, которые раз в день создает резервную копию бд.
Руководство по SQLite: настраиваем и учимся работать
Давно хотели познакомиться с SQLite? Мы сделали руководство по настройке и работе с инструментом, на основе статьи топового программиста.

SQLite — это автономная база данных без » target=»_blank»>сервера SQL. Ричард Хипп, создатель SQLite, впервые выпустил программное обеспечение 17 августа 2000 года. С тех пор оно стало вторым по популярности ПО в мире. Его используют даже в таких важных системах, как Airbus A350. Кстати, программа вместе со всеми библиотеками весит всего несколько мегабайт.
Установка SQLite 3 клиента
Для запуска SQLite 3, в командной строке нужно прописать следующее:
Настройка клиента
Вы можете изменить заданные по умолчанию настройки CLI SQLite 3, отредактировав файлы
/.sqliterc в директории. Это удобно для сохранения настроек, которые вы часто используете (рецептов). Вот пример:
Импорт CSV файлов
Если таблицы назначения еще не существует, первая строка CSV-файлов будет использоваться для именования каждого из столбцов. Если таблица существует, то все строки данных будут добавлены в существующую таблицу.
В качестве примера я собрал несколько аэропортов Уэльса в CSV-файл с разными кодировками.
Я запустил в клиенте SQLite 3 новую базу данных под названием airport.db. Этого файла базы данных еще не существовало, поэтому SQLite 3 автоматически создал его для меня.
Я переключил клиент в режим CSV, установил запятую разделителем, а затем импортировал файл airport.csv.
Теперь появляется возможность запустить команду schema в таблице новых аэропортов, видим два столбца с названиями на японском языке и ещё два — с использованием ASCII-символов.
Без проблем можно давать команды, смешивая кодировки.
Кроме того, можно сбросить базу данных на SQL с помощью лишь одной команды.
Создание базы данных в памяти
Локальность данных может быть значительно улучшена за счет хранения базы данных SQLite 3 в памяти, а не на диске. Ниже приведен пример, где я вычисляю 10 значений Фибоначчи и сохраняю их в базе данных SQLite 3, находящейся в памяти, с использованием Python 3.
Пользовательские функции
Вы можете создавать пользовательские функции в Python, которые будут выполняться с использованием данных, находящихся внутри БД SQLite 3. Ниже приведена небольшая база данных SQLite 3:
Затем я создал функцию на Python, которая извлекает имя хоста из URL-адреса и выполняет действия, ориентируясь на таблицу.
Вот что выводится при вызове функции fetchall:
Работа с несколькими базами данных
Клиент SQLite 3 способен работать с несколькими базами данных за один сеанс. Ниже я запустил клиент и подключил две базы данных.
В качестве префикса я использую имена таблиц в моих запросах с именем, которое я назначил базе данных.
Визуализация с помощью Jupyter Notebooks
Jupyter Notebooks — популярная программа для визуализации данных. Ниже можно посмотреть процесс настройки и несколько примеров визуализаций.
Для начала я установил ряд системных зависимостей.
Я обновил менеджер пакетов «pip» Python до версии 9.0.1 в этой виртуальной среде.
Затем я установил несколько популярных Python-библиотек.
Jupyter Notebooks откроет рабочую папку на Linux-машине через HTTP, поэтому мне нужно создать отдельную рабочую папку.
Затем я включил расширение gmaps и разрешил Jupyter использовать виджеты.
После этого я запустил » target=»_blank»>сервер Notebook. Вы увидите URL-адрес, содержащий параметр токена. Чтобы запустить Notebook (не ПК, конечно же), откройте ссылку в веб-браузере.
Перед открытием URL-адреса я создал базу данных SQLite 3 из CSV-файла. Здесь содержится около миллиона случайных записей о поездках на такси. Чтобы экспортировать эти записи из Hive, я сделал следующее:
В моём блоге есть краткие инструкции по импорту набора данных в Hive. Если использовать инструкции не на ОС Raspbian, а на других, то имена пакетов, например, для JDK, вероятно, будут отличаться.
Вот первые три строки этого CSV-файла. Обратите внимание: первая строка содержит имена столбцов.
Я распаковал GZIP-файл, запустил SQLite 3, добавил trip.db в качестве параметра.
Затем переключился в режим CSV, убедился в том, что разделителем является запятая, и что импортирует CSV-файл в таблицу маршрутов.
Настроили, что дальше?
С импортированными данными я открыл Notebook URL-адрес и создал Python 3 Notebook в интерфейсе Jupyter’а. Теперь необходимо вставить следующее в первую ячейку, одновременно зажать shift и кнопку выполнения.
Код выше будет импортировать Pandas, библиотеку Python для SQLite 3, Holoviews — библиотеку обработки данных, библиотеку визуализации, а затем инициализировать расширение Bokeh для Holoviews. Наконец, будет установлено соединение с базой данных SQLite 3 с информацией о поездках на такси.
В следующем примере я привел код, который создаст heatmap для разбивки поездок по дням и часам.
Ниже приводится линейная диаграмма, показывающая количество поездок такси.
Чтобы построилась гистограмма, сравнивающая данные по разным цветам автомобилей, необходимо ввести информацию в новую ячейку.
Ниже приводится круговая диаграмма, показывающая зависимость поездок от времени суток.
Чтобы создать диаграмму матрицы рассеивания, выполните действия как в коде ниже. Заметьте, что это может занять несколько минут. Сначала будет показан массив данных, а потом и сам график.
Я натолкнулся на два способа отображения географических точек на картах. Первый — с Matplotlib и Basemap, которые будут работать в автономном режиме, без необходимости использовать API-ключи. Ниже будут указаны точки сбора для маршрутов такси в наборе данных.
Да, это выглядит несколько примитивно.
Следующий код построит heatmap поверх Google Maps виджета. Недостатком является то, что вам нужно будет создать связанный с Google API-ключ и подключаться к Интернету, когда вы его используете.
Другая проблема заключается в том, что если географические данные о широте/долготе недействительны, вы получите сообщение об ошибке, а не просто пропустите их. Зачастую набор данных находится в неидеальном состоянии, а потому, возможно, придется потратить некоторое время на фильтрацию неверных значений.
Дампинг Pandas DataFrames для SQLite
Pandas DataFrames отлично подходят для создания производных наборов данных с минимальным количеством кода. Кроме того, сброс Pandas DataFrames обратно в SQLite 3 очень прост. В этом примере я заполнил DataFrame некоторыми CSV-данными, создал новую базу данных SQLite 3 и выгрузил DataFrame в этот файл.
Вывод
SQLite 3 — не игрушка, а мощное SQL-расширение. Поскольку скорость хранения и производительность одного ядра в процессорах увеличивают объем данных, SQLite 3 продолжает развиваться.
Я определенно считаю SQLite 3 одной из наиболее удобных баз данных, и я решаю значительное количество задач с его помощью.
Возможно вас заинтересует следующая статья
Файловое строение SQLite
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
Страницы
Заголовок
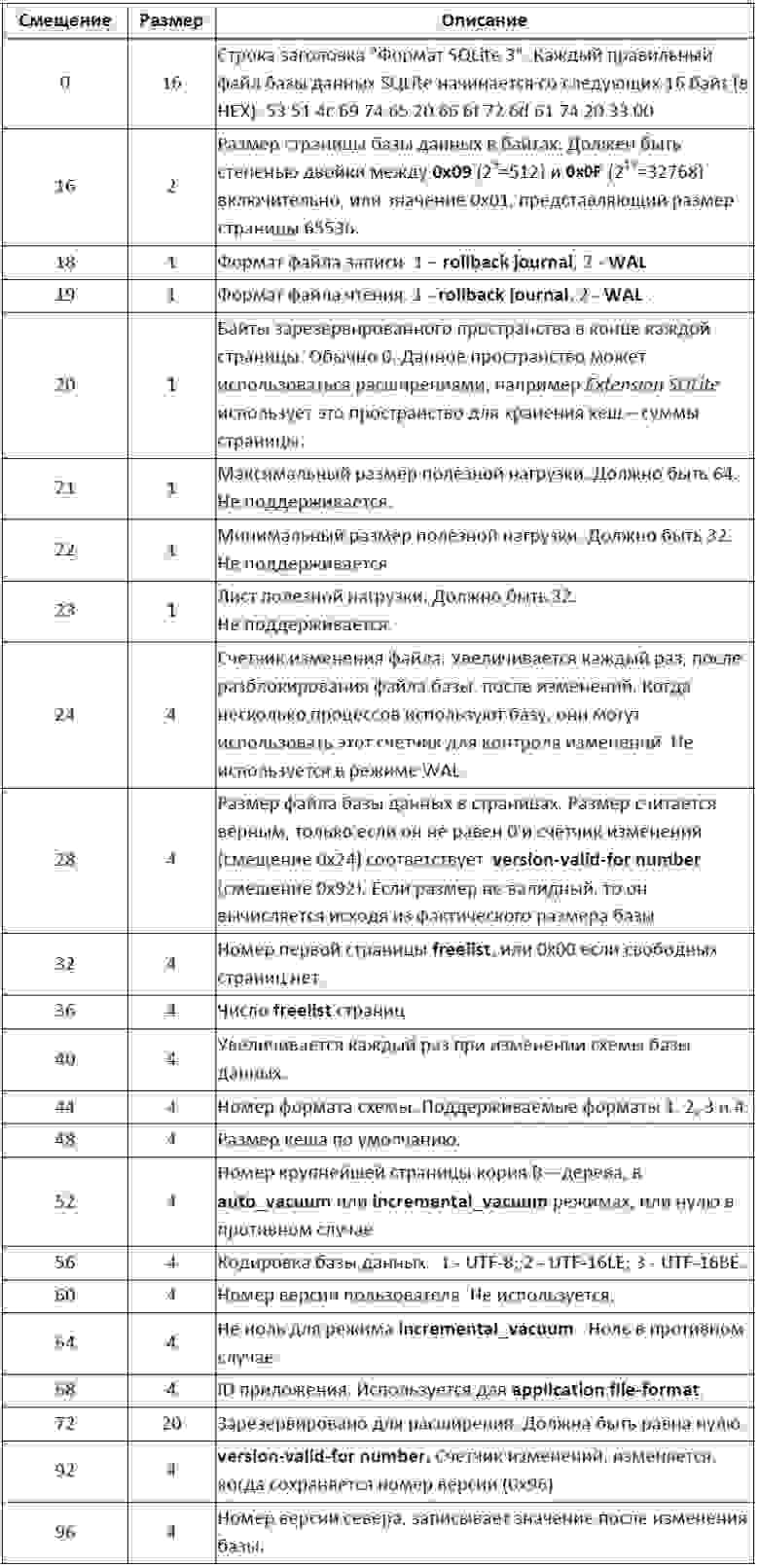
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Страница блокировки является одной страницей файла базы и находится между смещениями 0х1073741824 и 0х1073742335, если размер базы меньше, то она не имеет страницы блокировки. Данная страница нужна для реализации примитивов блокировки OS Interface’ом.
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
Страница B — tree
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.
Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
В данном разделе описана структура хранения данных в базе. Данные на листовых страницах table b — tree и ключи index b — tree, хранятся в качестве произвольной последовательности байт называемом record format (подробнее habrahabr.ru/post/223451).
TABLE
Каждая таблица (с ROWID) представляется в базе в виде table b — tree. Каждая запись в дереве, соответствует строке таблицы SQL. Одна строка SQL таблицы представляется в виде последовательности (той же что и указана при ее создании) столбцов таблицы в record format. Если таблица имеет INTEGER PRIMARY KEY, который является псевдонимом ROWID, то вместо его значения будет записано NULL. SQLite всегда будет использовать ключ table b — tree вместо значения NULL при обращении к INTEGER PRIMARY KEY. Если Affinity столбца (рекомендация приведения типа, подробнее habrahabr.ru/post/149635 в разделе «Типы данных и сравнение значений») является REAL и значение может быть преобразовано к INTEGER без потери данных, то значение будет хранится в виде целого числа. При извлечении данных из базы SQLite преобразует целое число к REAL.
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).



