NUMA и что про него знает vSphere?
Я думаю, многие уже успели заглянуть и прочитать эту статью на английском в моем блоге, но для тех кому все таки комфортней читать на родном языке, нежели иностранном (как сказали бы на dirty.ru – на анти-монгольском), я перевожу очередную свою статью.
Вы уже наверняка знаете, что NUMA это неравномерный доступ к памяти. В настоящий момент эта технология представлена в процессорах Intel Nehalem и AMD Opteron. Честно говоря, я, как практикующий по большей части сетевик, всегда был уверен, что все процессоры равномерно борются за доступ к памяти между собой, однако в случае с NUMA процессорами мое представление сильно устарело.

Приблизительно так это выглядело до появления нового поколения процессеров.
В новой же архитектуре каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти и образует NUMA узел. То есть при 4 процессорах и 64 Гбайт памяти у вас будет 4 NUMA узла, каждый с 16 Гбайт памяти.
Насколько я понял, новый подход к распределению доступа к памяти был изобретен в силу того, что современные » target=»_blank»>сервера настолько напичканы процессорами и памятью, что становится технологически и экономически невыгодно обеспечивать доступ к памяти через единственную общую шину. Что в свою очередь может вести к соперничеству за полосу пропускания между процессорами, ну и к более низкой масштабируемости производительности самих » target=»_blank»>серверов. Новый подход привносит 2 новых понятия – Локальная память и Удаленная память. В то время как к локальной памяти процессор обращается напрямую, то к Удаленной памяти ему приходится обращаться старым дедовским методом, через общую шину, что означает более высокую задержку. Это также означает, что для эффективного использования новой архитектуры наша ОС понимать, что она работает на NUMA узле и правильно управлять своими проложениями/процессами, иначе ОС просто рискует оказаться в ситуации, когда приложение исполняется на процессоре одного узла, в то время как его (приложения) адресное пространство памяти располагается на другом узле. Быстрый поиск показал, что NUMA архитектура поддерживается Майкрософт начиная с Windows 2003 и Vmware – как минимум с ESX Server 2.
Не уверен, что в GUI как то можно увидеть данные NUMA узла, но определенно это можно посмотреть в esxtop.
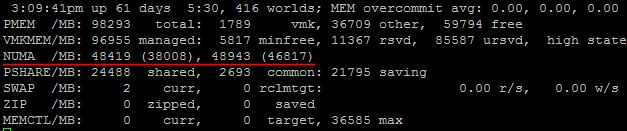
Итак, тут мы можем наблюдать, что в нашем » target=»_blank»>сервере 2 NUMA узла, и что в каждом их них 48 Гбайт памяти. Вот этот документ говорит, что первое значение означает количество локальной памяти в NUMA узле, а второе, в скобочках – количество свободной памяти. Однако, пару раз на своих продакшн » target=»_blank»>серверах я наблюдал второе значение выше, чем первое, и никакого объяснения этому найти не смог.
Итак, как только ESX » target=»_blank»>сервер обнаруживает, что он работает на » target=»_blank»>сервере с NUMA архитектурой, он незамедлительно включает NUMA планировщик, который в свою очередь заботится о виртуальных машинах и о том, чтобы все vCPU каждой машины находились в пределах одного NUMA узла. В предыдущих версиях ESX (до 4.1) для эффективной работы на NUMA системах максимальное количество vCPU виртуальной машины всегда ограничивалось количеством ядер на одном процессоре. Иначе NUMA планировщик просто игнорировал эту ВМ и vCPU равномерно распределялись поверх всех доступных ядер. Однако в ESX 4.1 была представлена новая технология, называемая Wide VM. Она позволяет нам назначать в ВМ большее количество vCPU, чем ядер на процессоре. Согласно Vmware документу планировщик разбивает нашу «широкую виртуальную машину» на несколько NUMA клиентов и затем уже каждый NUMA клиент обрабатывается по стандартной схеме, в пределах одного NUMA узла. Однако, память все таки будет разрозненной между выбранными NUMA узлами этой Wide VM, на которых работают vCPU виртуальной машины. Это происходит потому, что предсказать к какому участку памяти обратится тот или иной vCPU NUMA клиент практически невозможно. Несмотря на это, Wide VM все равно предоставляют существенно улучшенный механизм доступа к памяти по сравнению со стандартным «размазыванием» виртуальной машины поверх всех NUMA узлов.
Еще одна замечательная особенность NUMA планировщика это то, что он не только решает где расположить виртуальную машину при ее запуске, но и постоянно следит за ее соотношением локальной и удаленной памяти. И если это значение уходит ниже порога (по неподтвержденной инфо – 80%), то планировщик начинает мигрировать ВМ в другой NUMA узел. Более того ESX будет контролировать скорость миграции чтобы избежать излишней загруженности общей шины, через которую общаются все NUMA узлы.
Стоит также отметить, что при установке в памяти » target=»_blank»>сервер вы должны уставновить память в правильные слоты, т.к. за распределение памяти между NUMA узлами отвечает не NUMA планировщик, а именно физическая архитектура » target=»_blank»>сервера.
Ну и напоследок, немного полезной информации, которую вы можете подчерпнуть из esxtop.

Краткое описание значений:
NHN Номер NUMA узла
NMIG Количество миграций виртуальной машины между NUMA узлами
NMREM Количество удаленной памяти, используемой ВМ
NLMEM Количество локальной памяти, используемой ВМ
N&L Процентное соотношение между локальной и удаленной памятью
GST_ND(X) Количество выделенной памяти для ВМ на узле X
OVD_ND(X) Количество памяти потраченной на накладные расходы на узле X
Хотелось бы отметить, что как обычно вся эта статья всего лишь компиляция того, что мне показалось интересным из прочитанного за последнее время в блогах таких товарищей как Frank Denneman и Duncan Epping, а также официальных документов Vmware.
Записки виртуального админа
Новости, обзоры и заметки о виртуальных машинах и платформах виртуализации.
четверг, 27 мая 2010 г.
Сайзинг ВМ и NUMA системы
С появлением vSphere стало возможным создавать ВМ с 8 процессорами и 255 GB памяти. И хотя я не много видел машин с 32+GB, я получаю много вопросов о 8-процессорных ВМ. Из-за архитектуры современных процессоров ВМ с более чем 4-мя процессорами могут испытывать снижение скорости работы с памятью на NUMA системах. И хотя степень снижения сильно зависит от типа нагрузки, любой администратор должен избегать проблем с производительностью.
Большинство современных процессоров, таких как новенькие Intel Nehalem и закаленные в боях AMD Opteron, являются представителями архитектуры NUMA (Non-Uniform Memory Access). У каждого процессора есть своя собственная «локальная» память, а процессор и память вместе объединяются в узел NUMA. ОС будет пытаться использовать локальную память процессора, но при необходимости может обращаться и к «удаленной» памяти, принадлежащей другому NUMA узлу. Время доступа к памяти может варьироваться, в зависимости от расположения памяти относительно процессора, потому что обращение к собственной локальной памяти происходит быстрее, чем к удаленной.

Рисунок 1: Доступ к локальной и удаленной памяти
При обращении к удаленной памяти увеличивается задержка, соотв. нужно избегать этого до последнего. Но как можно гарантировать, что большинство обращений будут локальными?
Западня номер 1 при сайзинге ВМ: сайзинг vCPU и первичное размещение
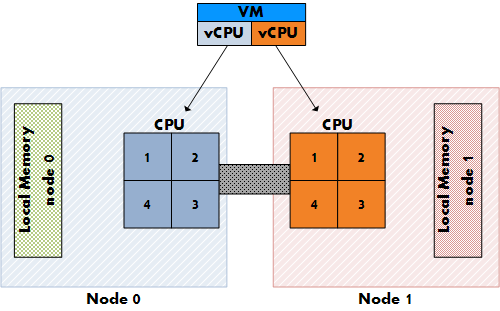
Рисунок 2: Размещение vCPU на не-NUMA системе
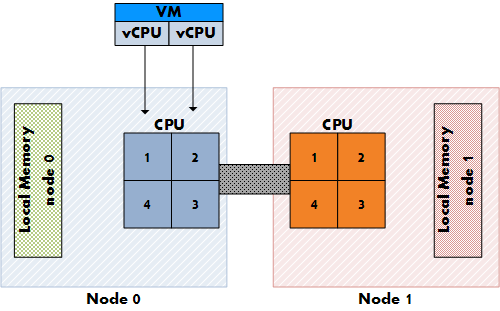
Рисунок 3: Размещение vCPU на NUMA системе
В настоящий момент AMD и Intel предлагают 4-ядерные процессоры, но если пользователь захочет создать 8-процессорную ВМ? Если ВМ не умещается внутри одного NUMA узла, то vCPU распределются традиционным образом, по всей системе. ВМ не получит ничего от оптимизации доступа к памяти, и соотв. при доступе процесса к удаленной памяти будет появляться дополнительная задержка.
Западня номер 2: сайзинг памяти ВМ и размер локальной памяти

Рисунок 4: общая статистика памяти в esxtop
Рисунок 5: Изменяем статистику
На рисунке 6 можно увидеть NUMA статистику для уже упомянутого ESX » target=»_blank»>сервервера с полностью загруженным NUMA узлом. Поле N%L показывает процент памяти, размещенной локально (локальность памяти) для ВМ.
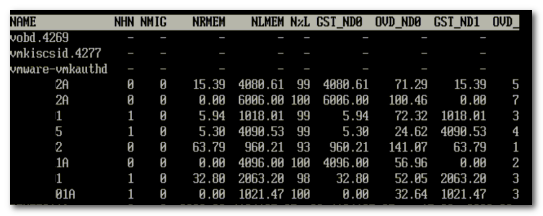
Рисунок 6: Статистика NUMA
Как мы видим, немногие машины работают с удаленной памятью. Man страница для esxtop поясняет значение всех параметров:
| Metric | Explanation |
|---|---|
| NHN | Current Home Node for virtual machine |
| NMIG | Number of NUMA migrations between two snapshots. It includes balance migration, inter-mode VM swaps performed for locality balancing and load balancing |
| NRMEM (MB) | Current amount of remote memory being accessed by VM |
| NLMEM (MB) | Current amount of local memory being accessed by VM |
| N%L | Current percentage memory being accessed by VM that is local |
| GST_NDx (MB) | The guest memory being allocated for VM on NUMA node x. “x” is the node number |
| OVD_NDx (MB) | The VMM overhead memory being allocated for VM on NUMA node x |
Transparent page sharing and локальность памяти.
Так что будет с transparent page sharing (TPS)? Ведь работа TPS может увеличить задержку, если ВМ с узла 0 будет разделять страницу памяти с ВМ с узла 1. К счастью, инженеры VMware подумали об этом, и по умолчанию TPS между узлами отключена с целью повышения локальности памяти. TPS все еще работает, но будет разделять доступ к страницам памяти только внутри узла. Задержки при доступе к удаленной памяти перевешивают положительный эффект экономии памяти на уровне всей системы.
День из работы техотдела или что такое NUMA
NUMA — это короткое слово, которое периодически замечаешь то там, то тут. В настройках BIOS, в логах операционной системы и т.д. Понимаешь, что оно как-то связанно с многопроцессорными системами, но на что именно влияет и зачем нужно, — эти вопросы практически всегда остаются без ответа. В большинстве случаев, не бывает особой нужды детально разбираться в этих тонкостях работы компьютера. Как известно, человек — создание ленивое, а следовательно: без нужды ничего делать не будет. Работает — значит не трогай… пусть дальше работает. Это девиз многих системных администраторов, и до недавнего времени мы тоже этим от многих других не отличались. Естественно, мы старались что-то оптимизировать, более корректно настраивать многие компоненты операционной системы и » target=»_blank»>серверов. Но мы не пытались оптимизировать абсолютно все. Не факт, что усилия, потраченные на оптимизацию, хоть как-то окупятся.
 vps.ua/blog/wp-content/uploads/2013/12/66-numa.jpg»/>
vps.ua/blog/wp-content/uploads/2013/12/66-numa.jpg»/>
Это продолжалось до тех пор, пока мы не столкнулись со странным поведением » target=»_blank»>сервера, которое было крайне сложно объяснить. У » target=»_blank»>сервера периодически переставала работать дисковая подсистема, из системы просто исчезал RAID контроллер. Это делало » target=»_blank»>сервер неработоспособным. После перезагрузки нормальная работа системы восстанавливалась. RAID контроллер снова появлялся и работал исправно, как будто ничего и не происходило. Замена RAID контроллера, установка его в другой слот PCI-X, а также замена материнской платы, процессоров, блоков питания, — ничего не давало результатов. Сервер продолжал работать нестабильно. Что мы только не делали — » target=»_blank»>сервер продолжал падать с завидной регулярностью. От одного раза в день до нескольких раз за час. Спрогнозировать дату падения и объяснить, с чем оно связано, было крайне сложно. Наблюдая за графиками загрузки » target=»_blank»>сервера, мы не понимали, в чем проблема. Проблемы появлялись и при маленькой нагрузке на процессор, и при большой. Ответ был найден случайно, в процессе перебора всего подряд. Причиной сбоев оказалось некорректное распределение оперативной памяти между процессорами. Я случайно, собирая информацию о системе, посмотрел на топологию NUMA. Оказалось, что основная масса процессов в системе выполняет дальний доступ к памяти. Это заставило меня обратить внимание на то, что поставщик, из расчета на апгрейд (модернизацию), вместо установки 6-и планок памяти, установил 3, но вдвое большего объема. Как следствие, планки были установлены только в слоты одного процессора. И, по воле случая, первый процессор в системе остался без планок памяти. Так случайный взгляд, брошенный на вещи, на которые мы никогда не обращали внимание, помог выявить проблему.
Так что же такое NUMA? Non-Uniform Memory Access — это «неравномерный доступ к памяти». Так гласит Википедия. Простым языком: это способ взаимодействия одного процессора с блоками памяти второго процессора. Это умное распределение памяти между процессами (условно — программами) в ОС. NUMA помогает распределить процессы в системе так, чтобы они получали области оперативной памяти, расположенные максимально близко к процессорам, на которых они работают. В такой ситуации, как у нас, программы (процессы), запущенные на процессоре без оперативной памяти, использовали так называемый “дальний доступ”. Другими словами: доступ осуществлялся через контроллер на другом процессоре. Все бы ничего и система linux давно умеет решать подобные проблемы. Априори программы (процессы) размещаются на процессоре с оперативной памятью. Но мы не учли одного фактора. А именно: систему виртуализации XEN. Она самостоятельно назначает соответствие виртуального процессора для виртуальной машины физическому (реальному) процессору в системе. Усугубляет ситуацию тот факт, что хост-система (управляющая) является такой же виртуальной машиной, как и другие. И только к ней подключены устройства, такие как: контроллер дисков, сетевая карта и т.д. По-умолчанию, любой виртуальный процессор может оказаться на любом физическом. Зачастую, в хост-системе первый виртуальный процессор соответствуют первому физическому процессору. И, поскольку на виртуальной машине с точки зрения NUMA все процессоры и вся память локальны, хост-система размещает на первом процессоре все прерывания и процессы для работы с устройствами. А если этот процессор не имеет подключенной оперативной памяти, то это не только снижает производительность системы, но и позволяет возникнуть аварийной ситуации. Плюс ко всему, этому первому физическому процессору могут быть назначены несколько виртуальных. А следовательно, за время (ресурсы) первого процессора будут конкурировать несколько виртуальных машин. Установка приоритета доступа к процессорному времени для хост-системы несколько улучшает ситуацию, но не решает проблему полностью. В процессе работы ввиду нехватки процессорного времени для хост-системы происходят сбои и шина pci переинициализируется. В какой-то момент превышается предел ожидания ответа, заложенный в драйвер RAID контроллера, и система констатирует факт его потери. Изюминкой ситуации является тот факт, что проблема появляется только при определенной нагрузке. Как только мы убираем все виртуальные машины с этого » target=»_blank»>сервера, он начинает стабильно работать.
Решением оказалось принудительное перераспределение процессоров между виртуальными машинами. Так, чтобы первый виртуальный процессор на хост-системе был на физическом процессоре, к которому подключена оперативная память. К тому же мы выделили одно физическое ядро процессора с памятью эксклюзивно для хост-системы. Это позволило избежать конкуренции с другими виртуальными машинами. И вуаля! Система уже более месяца работает стабильно. Но это не все! Также существенно увеличилась скорость работы с дисковой подсистемой. Это решение не ново и часто описывается на многих специализированных ресурсах, но в программных продуктах, используемых для автоматизации VPS-» target=»_blank»>сервер, » target=»_blank»>хостинга, оно почему-то не учитывается в принципе. На данный момент мы более не покупаем системы без минимального набора оперативной памяти для всех процессоров. Также мы провели эксперимент с системой, у которой был полный комплект памяти. Выделили одно ядро физического процессора для хост-системы и получили прирост скорости работы дисковой подсистемы. Теперь мы работаем над тем, чтобы автоматизировать подобные настройки на всех наших » target=»_blank»>серверах. Это позволит, не меняя аппаратного обеспечения, повысить производительность дисковой подсистемы на наших » target=»_blank»>серверах.
.ua/blog/66-about-numa/»>Источник
Архитектура Soft-NUMA (SQL Server)
Современные процессоры имеют несколько ядер на одном сокете. Каждый сокет обычно представлен одним узлом NUMA. Ядро базы данных SQL Server секционирует разные внутренние структуры и потоки служб в узлы NUMA. Если используются процессоры с 10 и более ядрами на сокет, распределение нагрузки между аппаратными узлами NUMA с помощью программной архитектуры NUMA зачастую позволяет повысить масштабируемость и производительность системы. До SQL Server 2014 (12.x) с пакетом обновления 2 (SP2) для использования программной архитектуры NUMA (Soft-NUMA) нужно было редактировать реестр, чтобы добавить маску сходства для настройки узла. Такая настройка выполнялась на уровне узла, а не для экземпляра. Начиная с SQL Server 2014 (12.x) с пакетом обновления 2 (SP2) и SQL Server 2016 (13.x); архитектура Soft-NUMA настраивается автоматически на уровне экземпляра базы данных при запуске службы Компонент SQL Server Database Engine.
Архитектура Soft-NUMA не поддерживает процессоры с «горячей» заменой.
Автоматическое создание архитектуры Soft-NUMA
По умолчанию в SQL Server 2016 (13.x);Компонент SQL Server Database Engine автоматически создает узлы архитектуры Soft-NUMA, если во время запуска обнаруживает более восьми физических ядер на один сокет или узел NUMA. Процессорные ядра с технологией Hyper-Threading не различаются при подсчете физических ядер на узле. Если обнаружено больше восьми физических ядер на один сокет, Компонент SQL Server Database Engine создает узлы архитектуры Soft-NUMA. В идеале узлы содержат по восемь ядер, но поддерживают и другое количество: от пяти до девяти логических ядер на один узел. Размер аппаратного узла может быть ограничен маской сходства ЦП. Количество узлов NUMA не может превышать максимальное количество поддерживаемых узлов NUMA.
На рисунке ниже показан пример сведений об архитектуре Soft-NUMA, которые вы увидите в журнале ошибок SQL Server, если SQL Server обнаружит аппаратные узлы NUMA с более чем восемью физическими ядрами на каждый узел или сокет.
Начиная с SQL Server 2014 (12.x) SP2 используйте флаг трассировки 8079, чтобы разрешить SQL Server использовать автоматическую программную архитектуру NUMA. Начиная с версии SQL Server 2016 (13.x); эта реакция управляется подсистемой, и флаг трассировки 8079 не оказывает влияния. Дополнительные сведения см. в разделе DBCC TRACEON — флаги трассировки.
Создание архитектуры Soft-NUMA вручную
Чтобы вручную настроить SQL Server для использования архитектуры Soft-NUMA, отключите автоматическую настройку архитектуры Soft-NUMA и добавьте в реестре маску сходства для настройки узла. Маска архитектуры Soft-NUMA в этом случае указывается как запись реестра с двоичным типом данных, типом данных DWORD (шестнадцатеричным или десятичным) или QWORD (шестнадцатеричным или десятичным). Чтобы настроить большее количество процессоров (больше чем первые 32), используйте значения реестра QWORD или BINARY. (Значения QWORD нельзя использовать до SQL Server 2012 (11.x)). Отредактировав реестр, перезапустите Компонент Database Engine, чтобы конфигурация архитектуры Soft-NUMA вступила в силу.
Нумерация процессоров начинается с 0.
Неправильное изменение реестра может вызвать серьезные проблемы. Перед внесением изменений в реестр рекомендуется создать резервную копию всех важных данных.
Рассмотрим пример компьютера с восемью ЦП, который не имеет оборудования NUMA. Настраиваются три узла программной архитектуры NUMA.
Экземпляр А компонента Компонент Database Engine настраивается для использования процессоров в количестве от 0 до 3. Второй экземпляр компонента Компонент Database Engine установлен и настроен для использования процессоров с 4 до 7. Визуально пример может быть представлен следующим образом.
CPUs 0 1 2 3 4 5 6 7
Экземпляр А, испытывающий значительную нагрузку ввода-вывода, теперь имеет два потока ввода-вывода и один поток модуля отложенной записи. Экземпляр В, выполняющий операции с интенсивным использованием процессора, имеет только один поток ввода-вывода и один поток модуля отложенной записи. Экземплярам может быть выделено различное количество памяти, но в отличие от оборудования NUMA, они оба получают память из одного блока памяти операционной системы, и здесь нет соответствия памяти и процессора.
Поток модуля отложенной записи связан с представлением физических узлов памяти NUMA в SQLOS. Поэтому любое число физических узлов NUMA, представленное оборудованием, будет равно числу создаваемых потоков модуля отложенной записи. Дополнительные сведения см. в разделе Как это работает: программная архитектура NUMA, поток завершения ввода-вывода, рабочие потоки модуля отложенной записи и узлы памяти.
Разделы реестра Soft-NUMA не копируются при обновлении экземпляра SQL Server.
Установка маски схожести ЦП
Выполните следующую инструкцию в экземпляре А, чтобы настроить его для использования процессоров 0, 1, 2 и 3 путем задания маски схожести ЦП.
Выполните следующую инструкцию в экземпляре В, чтобы настроить его для использования процессоров 4, 5, 6 и 7 путем задания маски схожести ЦП.
Установка соответствия программной архитектуры NUMA нескольким процессорам
С помощью программы «Редактор реестра» (regedit.exe) добавьте приведенные ниже разделы реестра, чтобы установить соответствие между узлом 0 программной архитектуры NUMA и ЦП 0 и 1, узлом 1 программной архитектуры NUMA и ЦП 2 и 3, а также узлом 2 и ЦП 4, 5, 6 и 7.
Чтобы указать процессоры с 60 по 63, используйте значение QWORD F000000000000000 или значение BINARY 1111000000000000000000000000000000000000000000000000000000000000.
В приведенном ниже примере предположим, что имеется » target=»_blank»>сервер DL580 G9 с 18 ядрами на сокет (в четырех сокетах) и каждый сокет находится в собственной K-группе. Создаваемая конфигурация программной архитектуры NUMA может быть следующей: шесть ядер на узел, три узла на группу, четыре группы.
| Пример для » target=»_blank»>сервера SQL Server 2016 (13.x); с несколькими K-группами | Тип | Имя значения | Данные |
|---|---|---|---|
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node0 | DWORD | CPUMask | 0x3F |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node0 | DWORD | Группа | 0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node1 | DWORD | CPUMask | 0x0fc0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node1 | DWORD | Группа | 0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node2 | DWORD | CPUMask | 0x3f000 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node2 | DWORD | Группа | 0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node3 | DWORD | CPUMask | 0x3F |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node3 | DWORD | Группа | 1 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node4 | DWORD | CPUMask | 0x0fc0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node4 | DWORD | Группа | 1 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node5 | DWORD | CPUMask | 0x3f000 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node5 | DWORD | Группа | 1 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node6 | DWORD | CPUMask | 0x3F |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node6 | DWORD | Группа | 2 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node7 | DWORD | CPUMask | 0x0fc0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node7 | DWORD | Группа | 2 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node8 | DWORD | CPUMask | 0x3f000 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node8 | DWORD | Группа | 2 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node9 | DWORD | CPUMask | 0x3F |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node9 | DWORD | Группа | 3 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node10 | DWORD | CPUMask | 0x0fc0 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node10 | DWORD | Группа | 3 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node11 | DWORD | CPUMask | 0x3f000 |
| HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\130\NodeConfiguration\Node11 | DWORD | Группа | 3 |
Метаданные
Для просмотра текущего состояния и конфигурации архитектуры Soft-NUMA можно использовать указанные ниже динамические административные представления.
sp_configure (Transact-SQL): отображает текущее значение (0 или 1) параметра SOFTNUMA.
sys.dm_os_sys_info (Transact-SQL): в столбцах softnuma_configuration и softnuma_configuration_desc показаны текущие значения конфигурации.



