Урок №35. Символьный тип данных char
Обновл. 11 Сен 2021 |
Хоть тип char и относится к целочисленным типам данных (и, таким образом, следует всем их правилам), работа с char несколько отличается от работы с обычными целочисленными типами.
Тип данных char
Переменная типа char занимает 1 байт. Однако вместо конвертации значения типа char в целое число, оно интерпретируется как ASCII-символ.
ASCII (сокр. от «American Standard Code for Information Interchange») — это американский стандартный код для обмена информацией, который определяет способ представления символов английского языка (+ несколько других) в виде чисел от 0 до 127. Например: код буквы ‘а’ — 97, код буквы ‘b’ — 98. Символы всегда помещаются в одинарные кавычки.
Таблица ASCII-символов:
| Код | Символ | Код | Символ | Код | Символ | Код | Символ |
| 0 | NUL (null) | 32 | (space) | 64 | @ | 96 | ` |
| 1 | SOH (start of header) | 33 | ! | 65 | A | 97 | a |
| 2 | STX (start of text) | 34 | ” | 66 | B | 98 | b |
| 3 | ETX (end of text) | 35 | # | 67 | C | 99 | c |
| 4 | EOT (end of transmission) | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ (enquiry) | 37 | % | 69 | E | 101 | e |
| 6 | ACK (acknowledge) | 38 | & | 70 | F | 102 | f |
| 7 | BEL (bell) | 39 | ’ | 71 | G | 103 | g |
| 8 | BS (backspace) | 40 | ( | 72 | H | 104 | h |
| 9 | HT (horizontal tab) | 41 | ) | 73 | I | 105 | i |
| 10 | LF (line feed/new line) | 42 | * | 74 | J | 106 | j |
| 11 | VT (vertical tab) | 43 | + | 75 | K | 107 | k |
| 12 | FF (form feed / new page) | 44 | , | 76 | L | 108 | l |
| 13 | CR (carriage return) | 45 | — | 77 | M | 109 | m |
| 14 | SO (shift out) | 46 | . | 78 | N | 110 | n |
| 15 | SI (shift in) | 47 | / | 79 | O | 111 | o |
| 16 | DLE (data link escape) | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 (data control 1) | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 (data control 2) | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 (data control 3) | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 (data control 4) | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK (negative acknowledge) | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN (synchronous idle) | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB (end of transmission block) | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN (cancel) | 56 | 8 | 88 | X | 120 | x |
| 25 | EM (end of medium) | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB (substitute) | 58 | : | 90 | Z | 122 | z |
| 27 | ESC (escape) | 59 | ; | 91 | [ | 123 | < |
| 28 | FS (file separator) | 60 | 94 | ^ | 126 | ||
| 31 | US (unit separator) | 63 | ? | 95 | _ | 127 | DEL (delete) |
Символы от 0 до 31 в основном используются для форматирования вывода. Большинство из них уже устарели.
Символы от 32 до 127 используются для вывода. Это буквы, цифры, знаки препинания, которые большинство компьютеров использует для отображения текста (на английском языке).
Следующие два стейтмента выполняют одно и то же (присваивают переменным типа char целое число 97 ):
Будьте внимательны при использовании фактических чисел с числами, которые используются для представления символов (из ASCII-таблицы). Следующие два стейтмента выполняют не одно и то же:
Вывод символов
При выводе переменных типа char, объект cout выводит символы вместо цифр:
Также вы можете выводить литералы типа char напрямую:
Оператор static_cast
Если вы хотите вывести символы в виде цифр, а не в виде букв, то вам нужно сообщить cout выводить переменные типа char в виде целочисленных значений. Не очень хороший способ это сделать — присвоить переменной типа int переменную типа char и вывести её:
Лучшим способом является конвертация переменной из одного типа данных в другой с помощью оператора static_cast.
Синтаксис static_cast выглядит следующим образом:
Пример использования оператора static_cast для конвертации типа char в тип int:
Результат выполнения программы:
Также в static_cast нет никакой проверки по диапазону, так что если вы попытаетесь использовать числа, которые будут слишком большие или слишком маленькие для конвертируемого типа, то произойдет переполнение.
Более подробно о static_cast мы еще поговорим на соответствующем уроке.
Ввод символов
Следующая программа просит пользователя ввести символ. Затем она выводит этот символ и его ASCII-код:
Результат выполнения программы:
Input a keyboard character: q
q has ASCII code 113
Обратите внимание, даже если cin позволит вам ввести несколько символов, переменная ch будет хранить только первый символ (именно он и помещается в переменную). Остальная часть пользовательского ввода останется во входном буфере, который использует cin, и будет доступна для использования последующим вызовам cin.
Рассмотрим это всё на практике:
Результат выполнения программы:
Input a keyboard character: abcd
a has ASCII code 97
b has ASCII code 98
Размер, диапазон и знак типа сhar
В языке С++ для переменных типа char всегда выделяется 1 байт. По умолчанию, char может быть как signed, так и unsigned (хотя обычно signed). Если вы используете char для хранения ASCII-символов, то вам не нужно указывать знак переменной (поскольку signed и unsigned могут содержать значения от 0 до 127).
Управляющие символы
В языке C++ есть управляющие символы (или «escape-последовательности»). Они начинаются с бэкслеша ( \ ), а затем следует определенная буква или цифра.
First line
Second line
First part Second part
Таблица всех управляющих символов в языке C++:
| Название | Символ | Значение |
| Предупреждение (alert) | \a | Предупреждение (звуковой сигнал) |
| Backspace | \b | Перемещение курсора на одну позицию назад |
| formfeed | \f | Перемещение курсора к следующей логической странице |
| Символ новой строки (newline) | \n | Перемещение курсора на следующую строку |
| Возврат каретки (carriage return) | \r | Перемещение курсора в начало строки |
| Горизонтальный таб (horizontal tab) | \t | Вставка горизонтального TAB |
| Вертикальный таб (vertical tab) | \v | Вставка вертикального TAB |
| Одинарная кавычка | \’ | Вставка одинарной кавычки (или апострофа) |
| Двойная кавычка | \” | Вставка двойной кавычки |
| Бэкслеш | \\ | Вставка обратной косой черты (бэкслеша) |
| Вопросительный знак | \? | Вставка знака вопроса |
| Восьмеричное число | \(number) | Перевод числа из восьмеричной системы счисления в тип char |
| Шестнадцатеричное число | \x(number) | Перевод числа из шестнадцатеричной системы счисления в тип char |
Рассмотрим пример в коде:
Результат выполнения программы:
«This is quoted text»
This string contains a single backslash \
6F in hex is char ‘o’
Что использовать: ‘\n’ или std::endl?
При использовании std::cout, данные для вывода могут помещаться в буфер, т.е. std::cout может не отправлять данные сразу же на вывод. Вместо этого он может оставить их при себе на некоторое время (в целях улучшения производительности).
Используйте \n во всех остальных случаях.
Другие символьные типы: wchar_t, char16_t и char32_t
Тип wchar_t следует избегать практически во всех случаях (кроме тех, когда происходит взаимодействие с Windows API).
Так же, как и стандарт ASCII использует целые числа для представления символов английского языка, так и другие кодировки используют целые числа для представления символов других языков. Наиболее известный стандарт (после ASCII) — Unicode, который имеет в запасе более 110 000 целых чисел для представления символов из разных языков.
Существуют следующие кодировки Unicode:
UTF-32 — требует 32 бита для представления символа.
UTF-16 — требует 16 бит для представления символа.
UTF-8 — требует 8 бит для представления символа.
Типы char16_t и char32_t были добавлены в C++11 для поддержки 16-битных и 32-битных символов Unicode (8-битные символы и так поддерживаются типом char).
В чём разница между одинарными и двойными кавычками при использовании с символами?
Текст, который находится в двойных кавычках, называется строкой (например, «Hello, world!» ). Строка (тип string) — это набор последовательных символов.
Вы можете использовать литералы типа string в коде:
Более подробно о типе string мы поговорим на соответствующем уроке.
Поделиться в социальных сетях:
Урок №34. Логический тип данных bool
Комментариев: 12
>>Тип wchar_t следует избегать практически во всех случаях
Вот за такой совет автора оригинала… Это одна из причин, почему софт сделанный на одном языке крашится на ОС с другим языком — например японская игра на американской винде.. Да и собственно некоторый английский софт на русской винде.
Потому что либо они думают что кроме английского никаких языков нет и юзают char, либо пытаются втулить все в char8_t
В главе №30 «Размер типов данных» было написано «Интересно то, что sizeof — это один из 3-х операторов в языке C++, который является словом, а не символом (еще есть new и delete)». А в этой главе оказывается что есть ещё static_cast
странно, но в с++ sizeof(‘a’) == sizeof(char), в то время как в си — sizeof(‘a’) == sizeof(int). неожиданно …
В Си подобная конструкция sizeof(‘a’) == sizeof(int) имеет место из-за его особенностей. Аргумент первого sizeof скорее всего рассматривается как выражение (expression). А во всех выражениях в Си имеет место приведение к типу int, если используется меньший по размеру тип. Что и имеет место в данном случае. На деле же (насколько я знаю) в Си символы тоже размером в один байт. Вроде бы тип char так и вводился, чтобы быть равным одному байту.
Привет!
Вот с этим не понятно ничего:
Pro Java
Страницы
13 апр. 2015 г.
Особенности типа char мы рассмотрели в предыдущей статье. Здесь же мы рассмотрим все целочисленные примитивные типы Java оптом, так как они отличаются друг от друга только размером, а следовательно, только максимальным и минимальным значениями, которые могут содержать. Все типы за исключением char являются знаковыми, char, как уже объяснялось без знаковый. Повторим таблицу размеров и значений для этих типов тут еще раз:
Целочисленные литералы
Значения целочисленным переменным и константам задаются при помощи следующих литералов:
108 – десятичный литерал
0154 – восьмеричный литерал (в начале стоит ноль)
0x6c – шестнадцатеричный литерал
0b01101100 – двоичный литерал (с Java 7)
Так же в числовых литералах можно использовать символ подчеркивания _ для разграничения разрядов, это сделано только для удобства написания и понимания и ни как не влияет на значение (с Java 7). Например:
0110_1100, 0x7fff_ffff, 0177_7777_7777
Для обозначения литерала типа long можно использовать суффикс L (можно использовать и маленькую l, но ее легко попутать с единицей 1). Например:
3_000_000_000L
В связи с этим есть один интересный момент, что переменной типа long не возможно задать значения больше 2147483647 следующим оператором присваивания:
long iLong = 2147483648 ;
Хотя значение 2147483648 является допустимым для типа long, но компилятор считает это число 2147483648 литералом типа int, поскольку у него нет суффикса L, а для типа int число 2147483648 является не допустимым значением и поэтому компилятор выдаст ошибку. Чтобы этого не было надо использовать суффикс L. Например:
long iLong = 2147483648L ;
Такое выражение компилятор уже примет как правильное.
Над целочисленными типами можно совершать различные операции при помощи операторов сравнения, математических операторов и операторов побитового сдвига.
Операции сравнения для примитивных типов вообще и для целочисленных в частности сравнивают их значения. Операторы сравнения мы уже рассматривали при изучении типа boolean. Результатом этих операций может быть только значение типа boolean.
Арифметические операции

Тут впрочем все просто. На что только надо обратить внимание это то, что деление над целочисленными типами тоже целочисленное и в результате этих операций можно получить как целое число или целую или дробную часть от операции совершенной соответствующими операторами. Инкремент и декремент (увеличение или уменьшение на единицу) может быть как префиксным, так и постфиксным. При использовании префиксного оператора сперва происходит инкремент иди декремент переменной, а затем используется ее значение, при постфиксной наоборот – сперва используется текущее значение переменной, а затем происходит ее декремент или инкремент.

Все это мы подробно рассмотрим на практических примерах.
Операция деление по модулю (или остаток) определяется так:
a % b = a — (a / b) * b
То есть 5%3=2, потому что 5-(5/3)*3=2, имейте в виду что 5/3 в данном случае это целочисленное деление и результат этой операции равен 1.
Все операции кроме инкремента и декремента имеют короткую форму записи, представленную в левой колонке. С подобным мы уже сталкивались в типе boolean.
 Ну а теперь, чтобы не было скучно, простенький пример на пройденную тему.
Ну а теперь, чтобы не было скучно, простенький пример на пройденную тему.
Программа очень простая, единственное что может потребовать объяснение это пример переполнения, хотя в полном смысле этого слова, это нельзя назвать переполнением, так как значение не вышло за пределы байта, а просто произошло инвертирование числа в отрицательное значение. Можно было бы создать цикл чтобы догнать значение до реального переполнения, но во первых циклы мы еще не проходили, а во вторых и так понятно, даже на этом примере что происходит.
Если не понятно то в двух словах объясню. Максимальное положительное значение переменной типа byte равно 127. Что мы и задали в строке 32. Затем чтобы обмануть компилятор мы два раза сделали инкремент этого значения, то есть по идее должны были получить число 129. Если бы мы просто попытались сделать c=c+2, то компилятор и IDE показали бы нам ошибку приведения типов (можете попробовать и убедиться). Далее мы вывели получившиеся значение, которое стало равно –127. Это произошло потому, что в старший разряд (первый слева) была помещена единица. Числу 129 соответствует двоичное значение 1000 0001.
Но для типа byte, максимальным положительным значением является 127, что соответствует двоичному числу 0111 1111. Когда в старший разряд помещается единица, то это число начинает интерпретироваться как отрицательное. То есть если двоичное число 1000 0001 интерпретировать как отрицательное, то его десятичное значение будет равно –127. Почему так?
Теперь приведу вывод этой программы:

Если вдруг не понятно с двоичными числами, то очень рекомендую подтянуть информатику, так как далее будем обсуждать побитовые операции, а там без этого ни куда просто.
Побитовые операции в ряде случаев вещь чрезвычайно полезная и нужная.
В данном примере я рассмотрел из совмещенных операций только операции совмещенного сложения и присвоения, а так же вычитания и присвоения (строки 28 и 30), умножение, деление и деление по модулю уже не стал кодить, так как там все аналогично.
Про операцию деления по модулю еще стоит отметить одно правило:
a == (a / b) * b + (a % b)
Это так на заметку. Ну и поперли дальше!
Побитовые операции


Арифметический сдвиг вправо это сдвиг с сохранением знака числа, то есть все освободившиеся старшие биты заполняются единицами. В логическом сдвиге вправо все немного сложнее.
Арифметический сдвиг влево бывает только один, так как там только один вариант чем заполнять младшие освободившиеся биты – это ноль.

Особенно осторожным надо быть с логическим сдвигом вправо >>>.
Теперь рассмотрим все эти операторы более подробно.
Побитовое НЕ (
является оператором побитового отрицания, или побитового НЕ. Он инвертирует каждый бит своего единственного операнда, преобразовывая единицы в нули и нули в единицы. Например:

Побитовое И (&)
Этот оператор объединяет два целых операнда посредством логической операции И с их отдельными битами. В результате биты устанавливаются в единицу только там, где соответствующие биты установлены в единицу в обоих операндах. Например:
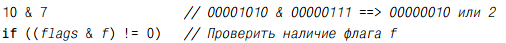
Побитовое ИЛИ (|)
Этот оператор объединяет два целых операнда посредством логической операции ИЛИ с их отдельными битами. В результате биты устанавливаются в единицу только там, где соответствующие биты установлены в единицу в одном или обоих операндах. Если оба соответствующих бита в операндах равны нулю, то результат содержит нулевой бит. Например:

Побитовое исключающее ИЛИ (^)
Этот оператор объединяет два целых операнда посредством логической операции
исключающего ИЛИ с их отдельными битами. В результате биты установлены в единицу только там, где соответствующие биты в двух операндах различны. Если оба бита – нули или единицы, то результат будет содержать нулевой бит. Например:


Если левый операнд представляет тип long, то значение правого операнда должно находиться в диапазоне между 0 и 63. В противном случае левый операнд считается int, а значение правого операнда должно располагаться между 0 и 31.
Побитовый арифметический сдвиг вправо со знаком (>>)

Побитовый логический сдвиг вправо без знака (>>>)
Этот оператор аналогичен оператору >>, но он всегда заполняет нулями старшие биты, каким бы ни был знак левого операнда. Данный прием называется дополнением нулями. Его применяют, если левый операнд интерпретируется как значение без знака (несмотря на то что в Java все типы со знаком). Например:

Как я уже говорил, с этим оператором надо быть очень осторожным, так как надо учитывать, что его операнды автоматически приводятся к типу int (или long), то есть их разрядность увеличивается. Приведенный пример справедлив для типа данных int, а вот для byte и short, он уже может подглючить. Поэтому пример с логическим сдвигом вправо мы рассмотрим более подробно, отдельно от остальных.
И еще несколько небольших замечаний:
Ну а теперь немножко практики.
В библиотеку ProJava.jar я добавил еще парочку статических методов printlnByte и printByte для вывода значений типа byte в двоичном виде как строку.
И далее то что это программа выводит

Тут все более или менее просто и понятно. Далее будем разбираться с оператором логического сдвига вправо.
Теперь посмотрим на вывод этой программы:
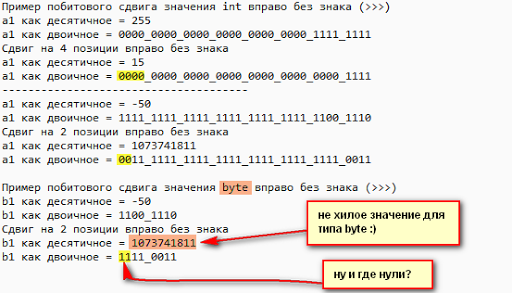
39 строка, которая выводит двоичное значение переменной типа byte b1 тоже преподнесла нам сюрприз. По идее в двух старших битах должны быть два нуля, но мы их там не наблюдаем. Там пара единиц. Это опять же произошло все по той же причине автоматического расширение byte и short до int или long, если long присутствует в выражении.
Приведение типов, явное и неявное мы рассмотрим чуток позже, а пока полезно знать о граблях неявного приведения типов.
И так в строке 39 мы просто получили обрубок значения int, старшие разряды которого были выкинуты, вместе с двумя нулями в начале (смотрите внимательно скриншот вывода).
Теперь поправим эту ситуацию, чтобы все работало правильно. Для этого надо применить маску 0xff, которая превратит все старшие 24 разряда типа int в нули.
и далее вывод программы (только новая часть):

Ну и напоследок приведу табличку побитовых операций (не сдвиговых, т.к. это не имеет смысла)

В принципе это тема весьма нужная и полезная и развлекаться с примерами здесь можно очень долго, но нам надо двигаться вперед.

А теперь, чтобы стало понятнее рассмотрим это на примере:

И вывод этой программы на консоль:

Как видим, там где мы сдвигали на 32 разряда, ни какого сдвига на самом деле не произошло по описанной выше причине.
Кроме того, при сдвиге на 48 позиций вправо, сдвиг на самом деле произошел на 16 позиций, по той же причине.
То есть можно заключить, что двигать переменную на количество бит равное или большее ее ширине в битах просто не имеет смысла, так как в этом случае сдвига или вовсе не будет или же будет на количество бит равное делению по модулю количества сдвигаемых бит, на ширину сдвигаемого типа.



