Выбор редакции
Топ-300 лучших полнометражных.
Топ-20 фильмов про быстрое.
Топ-20 лучших сериалов про.
Как кодируется информация в компьютере: отличия двоичной системы исчисления от шестнадцатеричной

Все мы привыкли к десятеричной системе исчисления, и многие люди даже не догадываются, что для цифровых устройств такая система неприменима. Ваш компьютер оперирует числами так же, как и человек, однако систему исчисления использует двоичную. Что это значит и зачем такие сложности?
Во всем мире люди используют так называемую «позиционную» систему: значение цифры в составе числа зависит от ее позиции. Это значит, что стоящие вместе цифры 1, 4 и 2 вместе будут составлять число сто сорок два, но если поменять эти цифры местами, мы получим совершенно другое число. Каждое из знаков в составе числа имеет свой разряд, поэтому мы легко читаем написанное число и определяем его величину.
Но позиционная система построения чисел не всегда была такой, какой мы привыкли его видеть. Например, цифра ноль придумана уже после того, как был изобретен основной ряд чисел. А до тех пор числа складывались иначе.
Римские цифры использовали повторительные символы для записи нового числа. Например, число 10 выглядит как X, 30 – ХХХ, а 1123 в римской записи выглядит как MCXXIII.
Как считает компьютер?
В компьютере используется элементарная двоичная система исчисления: числа складываются только из двух знаков – нуля и единицы. Это связано в первую очередь с внутренним строением компьютера. Внутри процессора находятся миллионы транзисторов, которые по своим техническим особенностям имеют два состояния: включен (ток свободно протекает) или выключен (ток не течет).
Различия между двоичной, десятичной и шестнадцатеричной системой
Двоичная система
Компьютеры не могут использовать обычную человеческую систему исчисления, так как один транзистор не может иметь десять различных состояний. Технически это не реализуемо, даже добиться третьего (полувключенного) и прочих промежуточных состояний от транзистора очень сложно. Для этого надо заставить транзистор работать на высоких частотах без сбоев.
С двоичной системой микроэлектроника справляется успешно. Компьютер оперирует только нулями и единицами. Каждая переключаемая ячейка (транзистор) именуется битом. Современные компьютеры имеют стандартный кластер в 1 байт, что равняется восьми битам (2 в степени 8), его максимальное значение равняется 256 знакам вместе с нулем:
1 бит – это минимальная единица для цифровых устройств.
Компьютер считывает число в двоичной форме, а потом преобразует его в удобный для человека вид. На картинке ниже представлено число «142» в двоичной системе.
 Фотография Бинарная система исчиления
Фотография Бинарная система исчиления
Шестнадцатеричная система
Эта система отличается от привычной десятичной и двоичной количеством знаков в разряде. Тут используется числовой ряд от 0 до 15, где в диапазоне от десяти до пятнадцати в роли чисел выступают латинские буквы.
 Фотография Шестнадцатеричная система исчисления
Фотография Шестнадцатеричная система исчисления
Этот формат используется в программировании для простой записи одного байта информации, а также в веб-дизайне, например, для кодирования палитры цветов. Вместо длинной двоичной записи в восемь знаков используются всего лишь два разряда. Максимальное двухразрядное значение этой системы можно представить в виде FF, что равняется 1111 1111 в двоичном или 255 в десятичном виде.
 Фотография Различия систем исчисления
Фотография Различия систем исчисления
Иногда перед значением можно увидеть префикс 0х, означающий, что следующее число следует интерпретировать, как шестнадцатеричное: 0х8E – число 142 в десятичной форме.
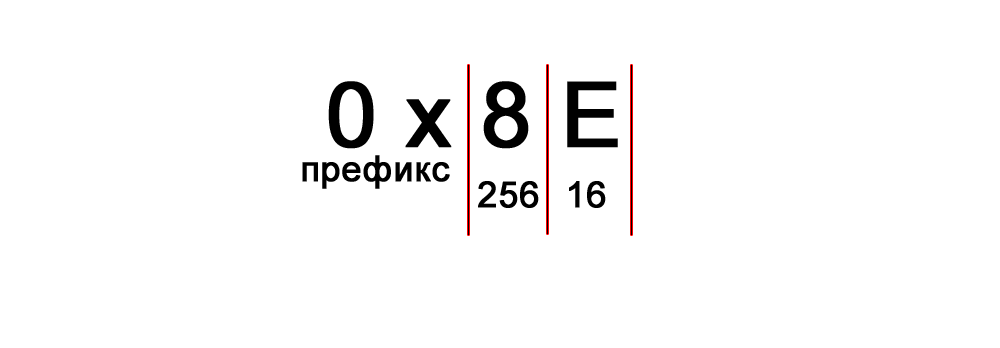 Фотография Префикс
Фотография Префикс
Так все-таки зачем такие сложности?
Конечно, для любого человека предпочтительнее использовать одну систему исчисления в различных сферах. Но увы, в цифровом мире это неприменимо: привычная десятичная система проста, но компьютер аппаратно ее не понимает, а двоичную систему читать невозможно. Шестнадцатеричная система делает код несколько более читаемым, но только для просвещенных, умеющих использовать HEX-редакторы.
Поэтому шестнадцатеричная система является неким переходным состоянием между машинным кодом и удобочитаемым кодом для человека.
 Фотография Декодированный бинарный код
Фотография Декодированный бинарный код
Кодирование для чайников, ч.1
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
1.2 Чередующиеся сигналы
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы «включено/выключено». Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.

1.3 Контекст
2. Кодирование текста
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза «ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП».
2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Что такое кодировки?
Компьютеры постоянно работают с текстами: это ленты новостных сайтов, фондовые биржи, сообщения в социальных сетях и мессенджерах, банковские приложения и многое другое. Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок. Кодировки прошли большой путь от таблиц символов, созданных отдельно для каждого компьютера, до единой кодировки, принятой во всём мире.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
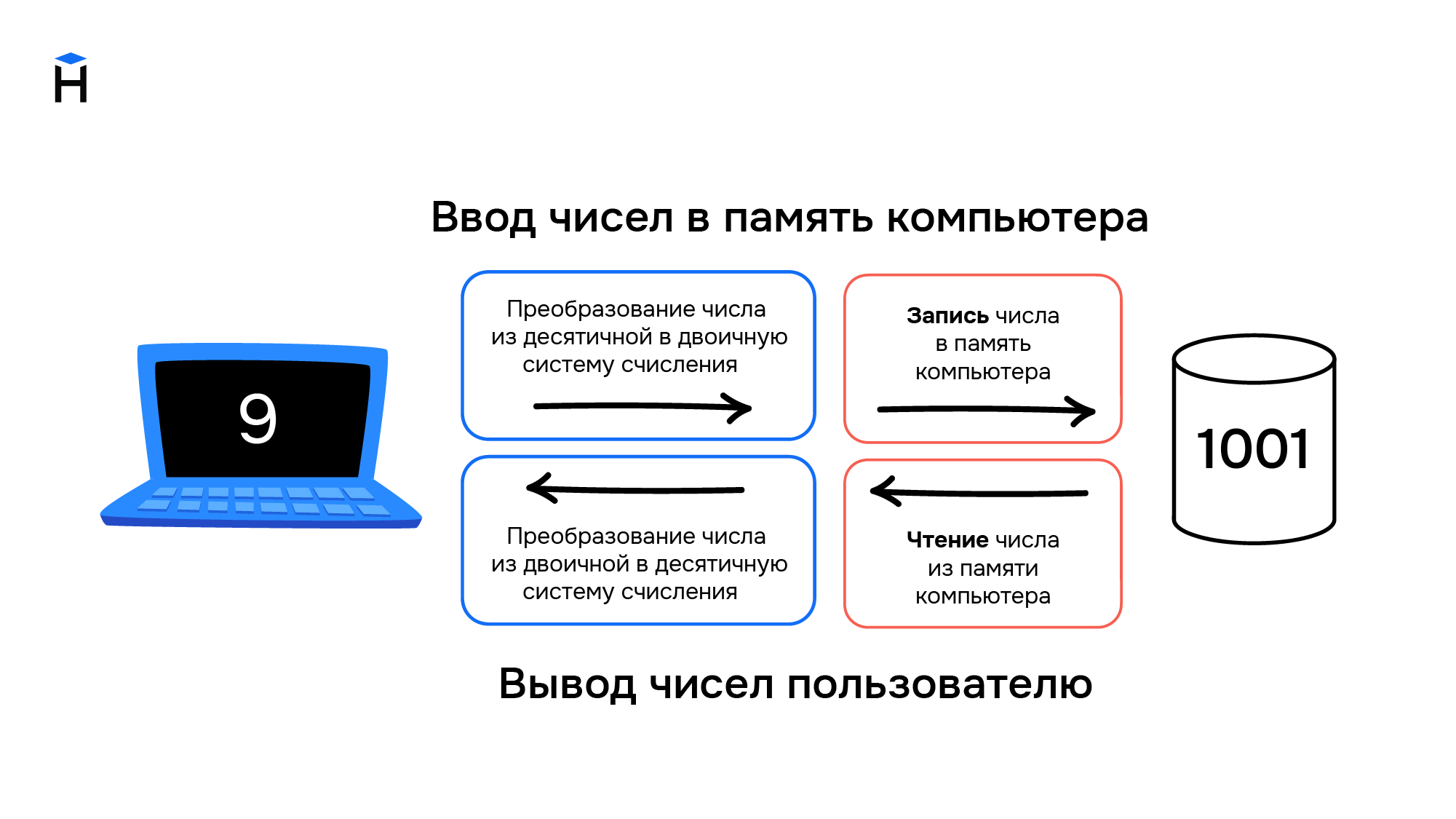
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
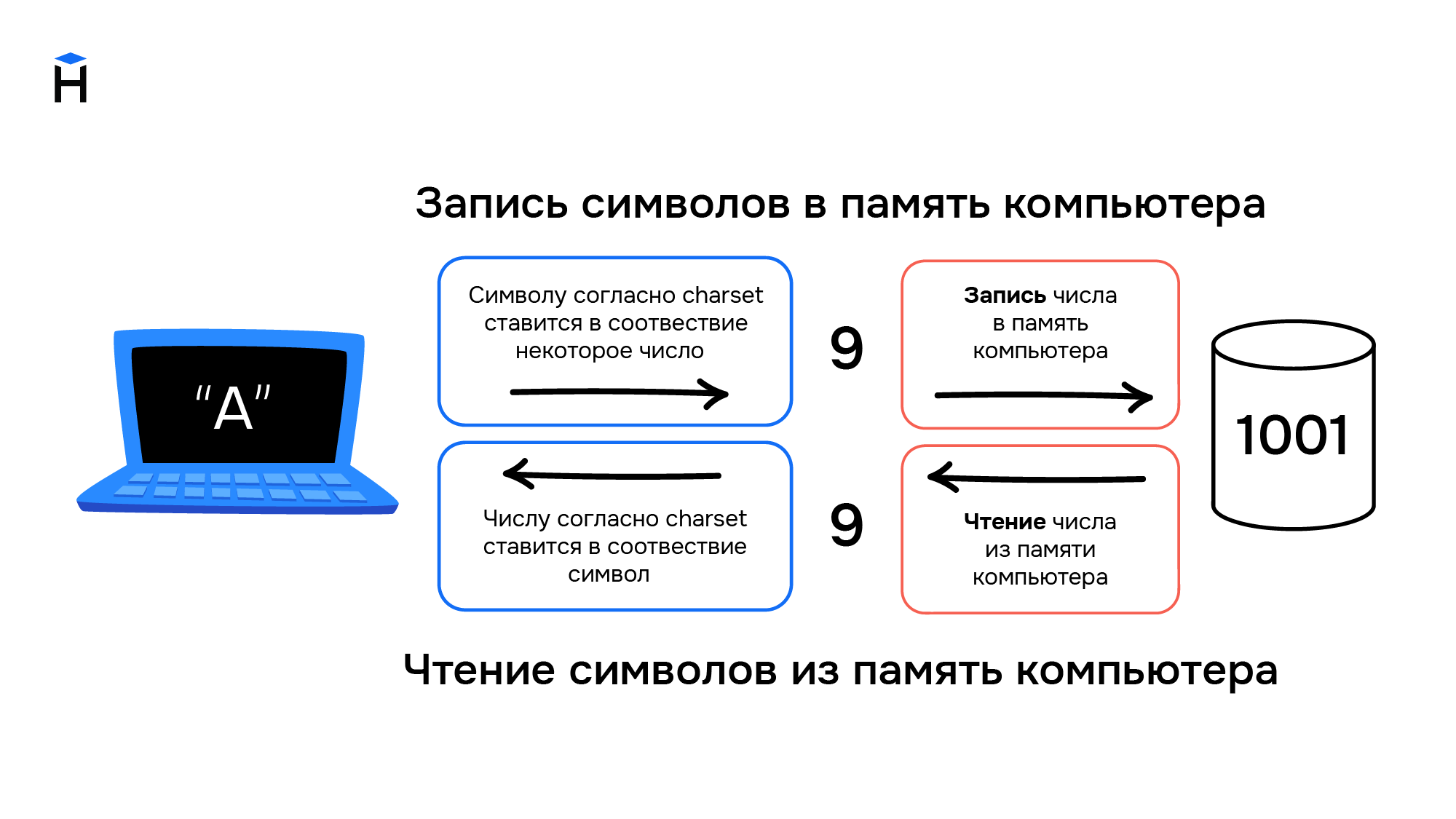
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
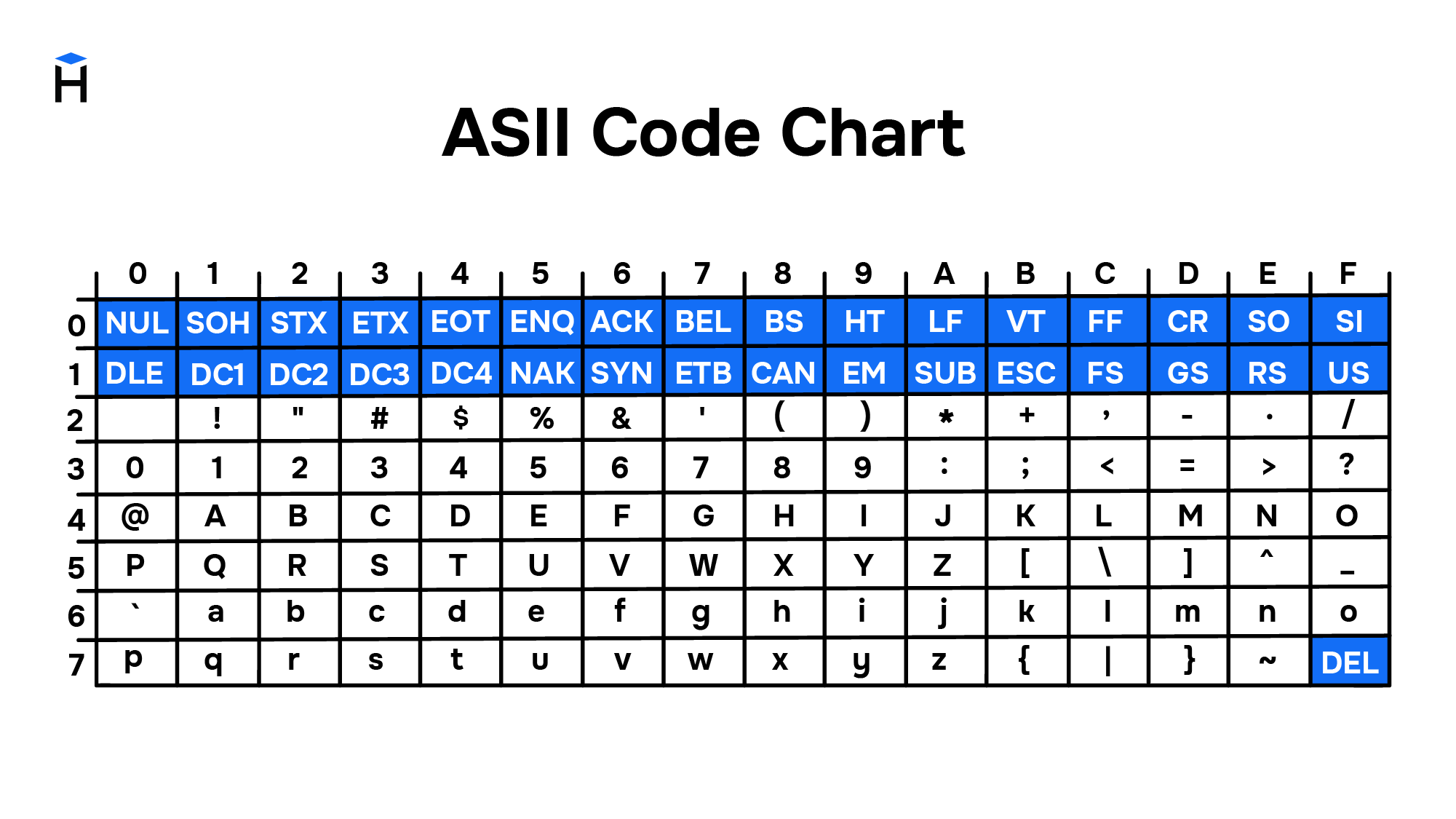
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
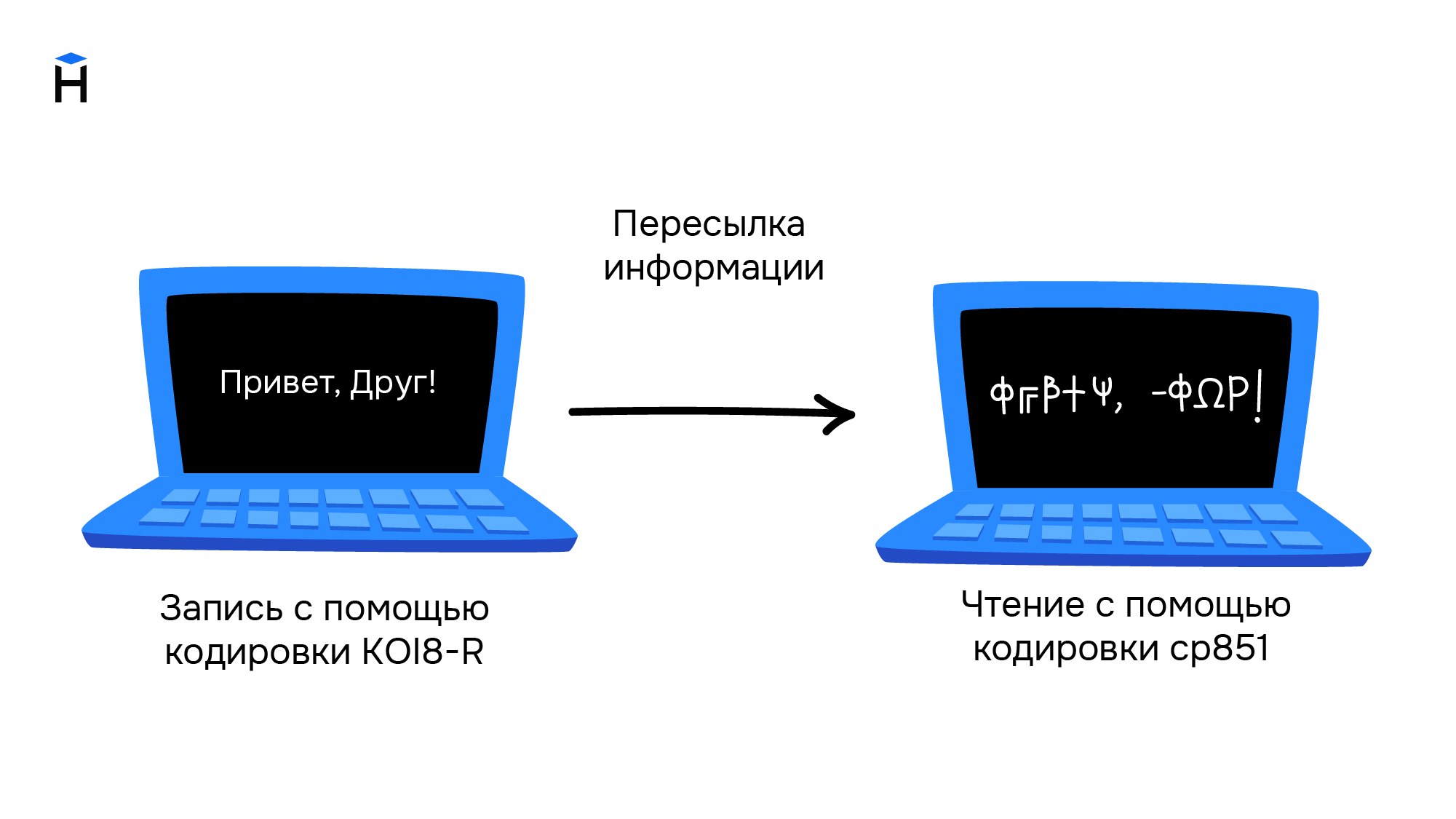
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Тест по информатике «Принципы устройства компьютера»
![]()
Принципы устройства компьютеров
1. Какое кодирование данных используется в современных компьютерах?
2. Отметьте все верные утверждения о компьютерной памяти с произвольным доступом.
процессор может обращаться к отдельному биту памяти
процессор может обращаться только к ячейке памяти
ячейки памяти всегда имели размер 8 битов
3. Какое английское сокращение используется для обозначения памяти с произвольным доступом?
можно сразу обратиться к ячейке с заданным адресом
можно как читать, так и записывать данные
данные доступны из любой программы
можно хранить произвольные данные
запрещено изменение данных
5. Отметьте все виды памяти с произвольным доступом.
оперативная память (ОЗУ)
постоянная память (ПЗУ)
память на магнитной ленте
память на флэш-дисках
6. В чем заключается принцип однородности памяти?
программы и данные расположены в одной области памяти
программы и данные расположены в разных областях памяти
память состоит из одинаковых ячеек
7. Что хранится в счётчике адреса команд?
адрес следующей команды
адрес только что выполненной команды
адрес команды, которая сейчас выполняется
данные для выполнения команды
возможны разные варианты
8. Как называется ячейка быстродействующей памяти, расположенная внутри процессора?
9. Где находится программа, которая первой начинает выполняться при включении компьютера?
в постоянной памяти (ПЗУ)
в оперативной памяти (ОЗУ)
10. Отметьте все вопросы, которые относятся к понятию «архитектура компьютера».
форматы данных и особенности их кодирования
Краткое объяснение кодирования текстовой информации. Информатика
Содержание:
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Кодирование текстовой информации и компьютеры
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.



