Что такое feature toggle или как избавиться от мучительных мёржей и долгоживущих веток?
Проблема
Представьте, что циклы разработки вашей команды длятся по две недели, а реализация новой фичи потребует от команды 3 месяца разработки. На первый взгляд, есть две возможные схемы действий:
Использование feature switcher-ов для решения проблем
Такая проблема встречается в разработке довольно часто и есть изящное решение, позволяющее взять лучшее от описанных выше подходов — feature toggle или feature switcher.
По сути, feature switcher — это boolean флаг, который хранится в базе данных и содержит информацию о том, должна быть включена та или иная фича или нет. Значение этого флага может быть извлечено из базы данных по ключу. Удобство использования feature switcher-ов заключается в том, что они могут быть легко изменены бизнес-пользователем во время runtime через панель администратора без необходимости заново деплоить приложение.
Ниже приведен пример использования feature toggle на языке Java:
В примере выше configurationManager — это класс, позволяющий извлечь значение определенного feature switcher-а из базы данных по его ключу.
Также, при помощи feature switcher-ов, можно отображать/скрывать определенные элементы на фронтенде. Для этого придется положить значение флага в Model и передать его на View как это показано ниже:
После чего использовать переданное значение для рендеринга того или иного HTML кода:
Виды feature switcher-ов
Описанный концепт использования feature switcher-ов — это лишь один возможный случай использования и такие feature switcher-ы называются release toggles. Всего выделяют 3 разных вида feature switcher-ов:

Проблемы использования feature toggle-ов
Поскольку я работаю на проекте, где активно используются feature toggle-ы, то кроме очевидных достоинств их использования я начал замечать и проблемы, связанные с ними:
Решения некоторых из описанных проблем
Помочь решить вышеописанные проблемы могут следующие действия:
Итоги
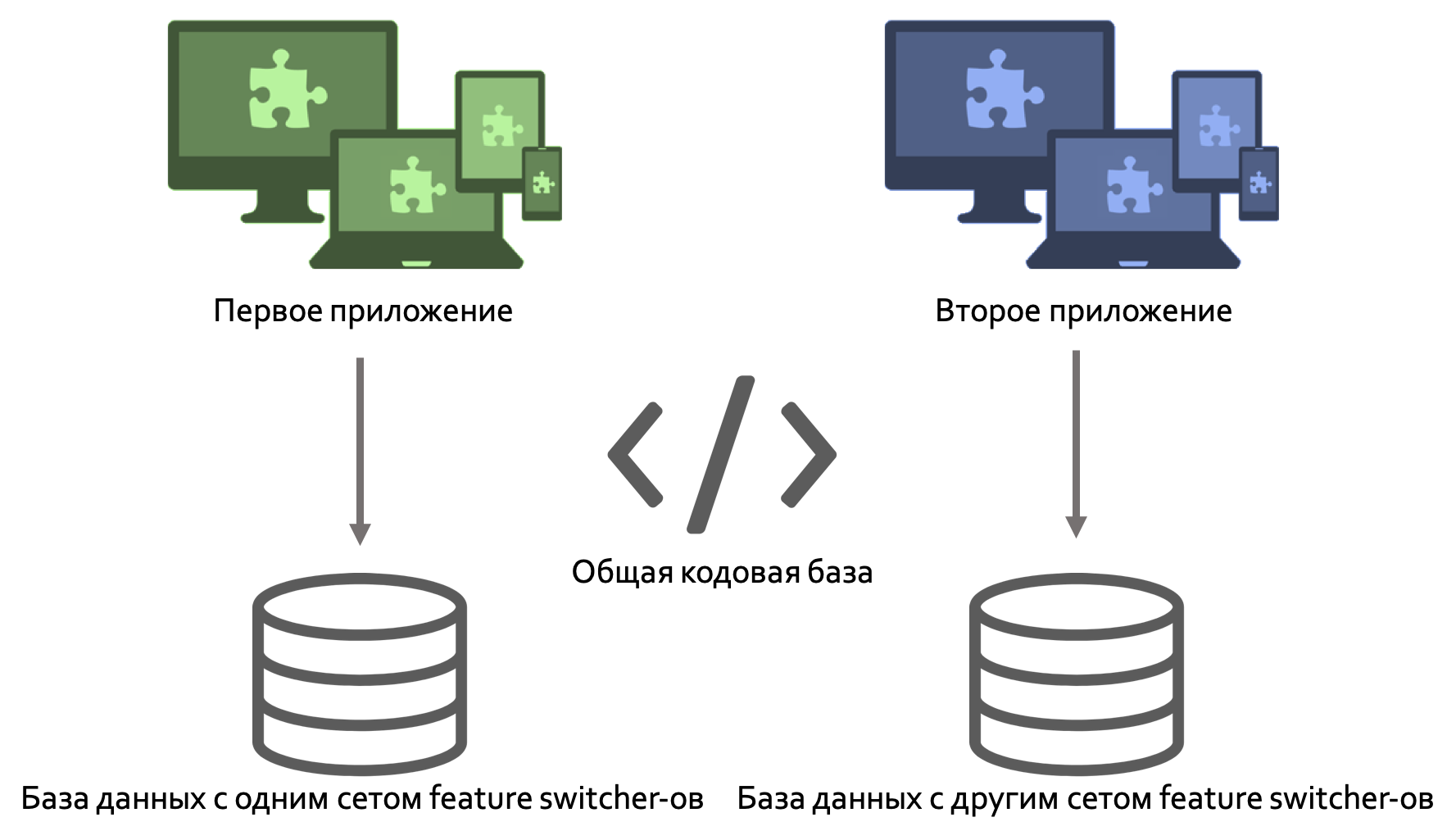
Feature switcher — очень простой и одновременно мощный механизм, позволяющий избегать монструозных коммитов, легко менять поведения приложения или собирать несколько разных приложений на одной кодовой базе, используя разную конфигурацию feature toggle-ов.
Однако, стоит также помнить, что этот паттерн разработки имеет некоторые недостатки, которые выливаются в трудночитаемый и трудно поддерживаемый код, поэтому следует избегать чрезмерного использования этого паттерна и периодически проводить документирование feature switcher-ов и их ревизию, чтобы удалять неиспользуемые и, как следствие, очищать проект от “мёртвого” кода.
Feature toggle

Подготовил репку с примерами, смотреть тут.
Предыстория
Мне нравится англоязычный подкаст по iOS-разработке iPhreaks, и в один прекрасный момент я набрел на соседний рубевый подкаст про feature toggles. Все началось с легкого наброса про то, что не стоит ребейсить, продолжилось про интереснейший подход к ведению веток TBD и закончилось feature toggles.
Само знакомство с последним подходом стало для меня некоторым откровением. Причина скорее всего в том, что самому приходилось удалять фичи, которые были реализованы несколько месяцев назад, причем это делалось с муками и болью, а тут мне предложили отключение фич по щелчку пальцев, да еще и наобещали A/B тестирования с удаленным управлением фичами.
На первый взгляд кажется, что инкапсулировать фичи, для последующего их переключения довольно просто, но чаще всего это не так. Кучу раз встречался со случаями, когда фича имеет выключатели в куче мест, они находятся на всех слоях приложения, вдогонку само отключение фичи вызывает веселые сайд-эффекты.
В процессе подготовки читал разные источники, но ключевым стал этот пост в блоге Фаулера, там автор разбирает данный вопрос с примерами из js, я же попробовал адаптировать это к реалиям iOS-разработки, естественно, ничего теоретически нового я не придумал.
Забегая вперед, напишу, что позже с этой темой я выступил на локальной Рамблеровской конфе Rambler.iOS, а потом и на питерской Mobius. Надо сказать, что как раз на последней народ принял довольно прохладно, и в комментах было и про банально, и про то что не надо, а если надо, то делается просто. Отдельно были комменты про скомканный материал(мы с коллегой решили уместиться в один слот, чтобы народ не скучал, видимо получилось слишком бодро) и про то, что слишком много теории, нужна практика и примеры.
Про просто я не согласен(иначе не встречался бы код где переключение фичи размазано по всему приложению), а вот недостаток практики и примеров попробую исправить. Кто уже устал читать может глянуть сразу в пример на github.
Теория
Концепция
В данном подходе есть несколько основных моментов:
Категории фич
В том самом посте из блога Фаулера, довольно долго расписываются категории с диаграммами Венна, я же предложу ровно две: статические и динамические. Именно эти ровно потому, что для них есть принципиальное различие в плане реализации.
Статические
К статическим относим фичи, о состоянии, на которое они опираются, известно заранее. Например нам надо что-то отображать в зависимости от размера экрана, или от версии операционной системы, или от начального конфига приложения. Во всех случаях к моменту создания модуля уже известно состояние, или оно меняется снаружи и сам модуль выступает в пассивной роли. Далее можно действовать двумя способами: передаем снаружи некий конфиг, или правильно настраиваем зависимости(например подставляем in-Memory хранилище вместо CoreData). В этом случае класс получается самодостаточным и ему никто не нужен для определения собственного поведения.
Динамические
Тут находятся фичи, о ключевом состоянии которого нам всегда необходимо знать, обычно это состояние может меняться множество раз за время жизни нашего компонента. Например мы хотим дизейблить кнопку, если есть интернет соединение, и включать обратно, если есть. Также хотелось бы инкапсулировать логику по принятию решения в отдельный объект, чтобы не тащить все необходимые для этого зависимости в сам класс.
Примеры
И наконец примеры! Давайте разберемся как это все будет выглядить на реальных примерах. Отдельно напишу, что подготовил для вас репозиторий со всем кодом, который был использован в примерах.
Для простоты понимания и чтобы абстрагироваться от какой либо конкретной архитектуры, буду использовать MVC + FeatureService, для принятия решения о включенности динамических фич. Вот теперь точно поехали!
Статические
Пример 1 (Передача конфига)
Как будет выглядить ветвление логики внутри:
Тут все довольно просто, нам передали конфиг, мы его сохранили в свойство, каждый раз когда нам надо принять решение, просто смотрим на соответствующие свойства.
Пример 2 (Настройка зависимостей)
У нас есть табличка, где мы отображаем список постов, туда мы хотим подмешать рекламу. Контроллер сам ничего не грузит, а получает все данные у своих провайдеров:
Мы просим данные у провайдера статей и у провайдера новостей, если второго нет, мы просто ничего не получим, все довольно просто:
Как и в первом случае место управления фичей находится за пределом модуля, да еще в случае с зависимостями не требуются ни проверки, ни места ветвления, все работает само.
Пример 3 (Сервис настроек)
Представим, что при заходе на экран нам надо показывать полноэкранную рекламу, но не чаще раза в сутки.
FeatureServiceViewController.m:
Контроллер обращается к специальному сервису за этими знаниями и действует в соответствии с ответом. Как выглядит сервис внутри:
FeatureServiceImplementation.m
Сервис содержит в себе все необходимые зависиомти для принятия решения. Иногда ему также требуется передавать некоторые параметры из контроллера.
Еще больше подробностей
Теперь когда мы посмотрели на примеры можно обсудить преимущества данного подхода и некоторые моменты, которые сразу не бросаются в глаза. В особенности это касается динамических фич.
Отсутствие логики принятия решения в VC
Место ветвления
Есть несколько моментов от которых хотелось бы предостеречь
Избыточная инкапсуляция
Данный подход может привести к желанию использовать его всегда, но не стоит делать каждую фичу выключаемой:
Зависимые фичи
В идеале лучше не иметь зависимых фич, но в случае, если этого не избежать, надо стараться уменьшать уровень зависмости. В качестве примера зависимых фич можно привести авиарежим и настройки связанные с получением данных. Если включен авиарежим, не имеет значение что в них выбрано.
Что получаем?
Итоги
Подход довольно простой, но в то же время он формализует множество важных моментов, которые с одной стороны лежат на поверхности, когда на них смотришь, но которые можно забыть во время реализации. Я реализовывал нечто подобное и раньше особо не задумываясь, но знакомство с подробностями данного подхода уложило в голове как можно инкапсулировать фичи и то от чего стоит продостеречься.
Напишите мне в комментариях или мне в twitter, что думаете. Буду признателен за фидбек.
Что такое feature toggle или как избавиться от мучительных мёржей и долгоживущих веток?
Допустим, вы хотите разработать новую фичу, но не уверены, что она понравится пользователям, и вам нужно иметь способ безболезненно её скрыть. Или предположим, что вы работаете над новой большой фичей и хотите избежать монстр-коммитов. Или просто хочется сделать поведение сайта легко конфигурируемым. Как можно решить все эти проблемы, читайте под катом.
Проблема
Представьте, что циклы разработки вашей команды длятся по две недели, а реализация новой фичи потребует от команды 3 месяца разработки. На первый взгляд, есть две возможные схемы действий:
Использование feature switcher-ов для решения проблем
Такая проблема встречается в разработке довольно часто и есть изящное решение, позволяющее взять лучшее от описанных выше подходов — feature toggle или feature switcher.
По сути, feature switcher — это boolean флаг, который хранится в базе данных и содержит информацию о том, должна быть включена та или иная фича или нет. Значение этого флага может быть извлечено из базы данных по ключу. Удобство использования feature switcher-ов заключается в том, что они могут быть легко изменены бизнес-пользователем во время runtime через панель администратора без необходимости заново деплоить приложение.
Ниже приведен пример использования feature toggle на языке Java:
В примере выше configurationManager — это класс, позволяющий извлечь значение определенного feature switcher-а из базы данных по его ключу.
Также, при помощи feature switcher-ов, можно отображать/скрывать определенные элементы на фронтенде. Для этого придется положить значение флага в Model и передать его на View как это показано ниже:
После чего использовать переданное значение для рендеринга того или иного HTML кода:
Виды feature switcher-ов
Описанный концепт использования feature switcher-ов — это лишь один возможный случай использования и такие feature switcher-ы называются release toggles. Всего выделяют 3 разных вида feature switcher-ов:
Проблемы использования feature toggle-ов
Поскольку я работаю на проекте, где активно используются feature toggle-ы, то кроме очевидных достоинств их использования я начал замечать и проблемы, связанные с ними:
Решения некоторых из описанных проблем
Помочь решить вышеописанные проблемы могут следующие действия:
Итоги
Feature switcher — очень простой и одновременно мощный механизм, позволяющий избегать монструозных коммитов, легко менять поведения приложения или собирать несколько разных приложений на одной кодовой базе, используя разную конфигурацию feature toggle-ов.
Однако, стоит также помнить, что этот паттерн разработки имеет некоторые недостатки, которые выливаются в трудночитаемый и трудно поддерживаемый код, поэтому следует избегать чрезмерного использования этого паттерна и периодически проводить документирование feature switcher-ов и их ревизию, чтобы удалять неиспользуемые и, как следствие, очищать проект от “мёртвого” кода.
Feature Toggles (aka Feature Flags)
Feature Toggles (often also refered to as Feature Flags) are a powerful technique, allowing teams to modify system behavior without changing code. They fall into various usage categories, and it’s important to take that categorization into account when implementing and managing toggles. Toggles introduce complexity. We can keep that complexity in check by using smart toggle implementation practices and appropriate tools to manage our toggle configuration, but we should also aim to constrain the number of toggles in our system.
Pete Hodgson is an independent software delivery consultant based in the San Francisco Bay Area. He specializes in helping startup engineering teams improve their engineering practices and technical architecture.
Pete previously spent six years as a consultant with Thoughtworks, leading technical practices for their West Coast business. He also did several stints as a tech lead at various San Francisco startups.
Contents
«Feature Toggling» is a set of patterns which can help a team to deliver new functionality to users rapidly but safely. In this article on Feature Toggling we’ll start off with a short story showing some typical scenarios where Feature Toggles are helpful. Then we’ll dig into the details, covering specific patterns and practices which will help a team succeed with Feature Toggles.
Feature Toggles are also refered to as Feature Flags, Feature Bits, or Feature Flippers. These are all synonyms for the same set of techniques. Throughout this article I’ll use feature toggles and feature flags interchangebly.
A Toggling Tale
Picture the scene. You’re on one of several teams working on a sophisticated town planning simulation game. Your team is responsible for the core simulation engine. You have been tasked with increasing the efficiency of the Spline Reticulation algorithm. You know this will require a fairly large overhaul of the implementation which will take several weeks. Meanwhile other members of your team will need to continue some ongoing work on related areas of the codebase.
You want to avoid branching for this work if at all possible, based on previous painful experiences of merging long-lived branches in the past. Instead, you decide that the entire team will continue to work on trunk, but the developers working on the Spline Reticulation improvements will use a Feature Toggle to prevent their work from impacting the rest of the team or destabilizing the codebase.
The birth of a Feature Flag
Here’s the first change introduced by the pair working on the algorithm:
these examples all use JavaScript ES2015
The pair have moved the current algorithm implementation into an oldFashionedSplineReticulation function, and turned reticulateSplines into a Toggle Point. Now if someone is working on the new algorithm they can enable the «use new Algorithm» Feature by uncommenting the useNewAlgorithm = true line.
Making a flag dynamic
A few hours pass and the pair are ready to run their new algorithm through some of the simulation engine’s integration tests. They also want to exercise the old algorithm in the same integration test run. They’ll need to be able to enable or disable the Feature dynamically, which means it’s time to move on from the clunky mechanism of commenting or uncommenting that useNewAlgorithm = true line:
We’ve now introduced a featureIsEnabled function, a Toggle Router which can be used to dynamically control which codepath is live. There are many ways to implement a Toggle Router, varying from a simple in-memory store to a highly sophisticated distributed system with a fancy UI. For now we’ll start with a very simple system:
note that we’re using ES2015’s method shorthand
Getting ready to release
To perform manual testing of a feature which hasn’t yet been verified as ready for general use we need to be able to have the feature Off for our general user base in production but be able to turn it On for internal users. There are a lot of different approaches to achieve this goal:
(We’ll be digging into these approaches in more detail later on, so don’t worry if some of these concepts are new to you.)
The team decides to go with a per-request Toggle Router since it gives them a lot of flexibility. The team particularly appreciate that this will allow them to test their new algorithm without needing a separate testing environment. Instead they can simply turn the algorithm on in their production environment but only for internal users (as detected via a special cookie). The team can now turn that cookie on for themselves and verify that the new feature performs as expected.
Canary releasing
A/B testing
The team’s product manager learns about this approach and is quite excited. She suggests that the team use a similar mechanism to perform some A/B testing. There’s been a long-running debate as to whether modifying the crime rate algorithm to take pollution levels into account would increase or decrease the game’s playability. They now have the ability to settle the debate using data. They plan to roll out a cheap implementation which captures the essence of the idea, controlled with a Feature Flag. They will turn the feature on for a reasonably large cohort of users, then study how those users behave compared to a «control» cohort. This approach will allow the team to resolve contentious product debates based on data, rather than HiPPOs.
This brief scenario is intended to illustrate both the basic concept of Feature Toggling but also to highlight how many different applications this core capability can have. Now that we’ve seen some examples of those applications let’s dig a little deeper. We’ll explore different categories of toggles and see what makes them different. We’ll cover how to write maintainable toggle code, and finally share practices to avoid some of pitfalls of a feature-toggled system.
Categories of toggles
Let’s consider various categories of toggle through the lens of these two dimensions and see where they fit.
Release Toggles
Release Toggles allow incomplete and un-tested codepaths to be shipped to production as latent code which may never be turned on.
These are feature flags used to enable trunk-based development for teams practicing Continuous Delivery. They allow in-progress features to be checked into a shared integration branch (e.g. master or trunk) while still allowing that branch to be deployed to production at any time. Release Toggles allow incomplete and un-tested codepaths to be shipped to production as latent code which may never be turned on.
Product Managers may also use a product-centric version of this same approach to prevent half-complete product features from being exposed to their end users. For example, the product manager of an ecommerce site might not want to let users see a new Estimated Shipping Date feature which only works for one of the site’s shipping partners, preferring to wait until that feature has been implemented for all shipping partners. Product Managers may have other reasons for not wanting to expose features even if they are fully implemented and tested. Feature release might be being coordinated with a marketing campaign, for example. Using Release Toggles in this way is the most common way to implement the Continuous Delivery principle of «separating [feature] release from [code] deployment.»
Release Toggles are transitionary by nature. They should generally not stick around much longer than a week or two, although product-centric toggles may need to remain in place for a longer period. The toggling decision for a Release Toggle is typically very static. Every toggling decision for a given release version will be the same, and changing that toggling decision by rolling out a new release with a toggle configuration change is usually perfectly acceptable.
Experiment Toggles
Experiment Toggles are used to perform multivariate or A/B testing. Each user of the system is placed into a cohort and at runtime the Toggle Router will consistently send a given user down one codepath or the other, based upon which cohort they are in. By tracking the aggregate behavior of different cohorts we can compare the effect of different codepaths. This technique is commonly used to make data-driven optimizations to things such as the purchase flow of an ecommerce system, or the Call To Action wording on a button.
Ops Toggles
These flags are used to control operational aspects of our system’s behavior. We might introduce an Ops Toggle when rolling out a new feature which has unclear performance implications so that system operators can disable or degrade that feature quickly in production if needed.
Permissioning Toggles
A Champagne Brunch is similar in many ways to a Canary Release. The distinction between the two is that a Canary Released feature is exposed to a randomly selected cohort of users while a Champagne Brunch feature is exposed to a specific set of users.
Managing different categories of toggles
Now that we have a toggle categorization scheme we can discuss how those two dimensions of dynamism and longevity affect how we work with feature flags of different categories.
static vs dynamic toggles
Toggles which are making runtime routing decisions necessarily need more sophisticated Toggle Routers, along with more complex configuration for those routers.
For simple static routing decisions a toggle configuration can be a simple On or Off for each feature with a toggle router which is just responsible for relaying that static on/off state to the Toggle Point. As we discussed earlier, other categories of toggle are more dynamic and demand more sophisticated toggle routers. For example the router for an Experiment Toggle makes routing decisions dynamically for a given user, perhaps using some sort of consistent cohorting algorithm based on that user’s id. Rather than reading a static toggle state from configuration this toggle router will instead need to read some sort of cohort configuration defining things like how large the experimental cohort and control cohort should be. That configuration would be used as an input into the cohorting algorithm.
We’ll dig into more detail on different ways to manage this toggle configuration later on.
Long-lived toggles vs transient toggles
We can also divide our toggle categories into those which are essentially transient in nature vs. those which are long-lived and may be in place for years. This distinction should have a strong influence on our approach to implementing a feature’s Toggle Points. If we’re adding a Release Toggle which will be removed in a few days time then we can probably get away with a Toggle Point which does a simple if/else check on a Toggle Router. This is what we did with our spline reticulation example earlier:
However if we’re creating a new Permissioning Toggle with Toggle Points which we expect to stick around for a very long time then we certainly don’t want to implement those Toggle Points by sprinkling if/else checks around indiscriminately. We’ll need to use more maintainable implementation techniques.
Implementation Techniques
Feature Flags seem to beget rather messy Toggle Point code, and these Toggle Points also have a tendency to proliferate throughout a codebase. It’s important to keep this tendency in check for any feature flags in your codebase, and critically important if the flag will be long-lived. There are a few implementation patterns and practices which help to reduce this issue.
De-coupling decision points from decision logic
One common mistake with Feature Toggles is to couple the place where a toggling decision is made (the Toggle Point) with the logic behind the decision (the Toggle Router). Let’s look at an example. We’re working on the next generation of our ecommerce system. One of our new features will allow a user to easily cancel an order by clicking a link inside their order confirmation email (aka invoice email). We’re using feature flags to manage the rollout of all our next gen functionality. Our initial feature flagging implementation looks like this:
While generating the invoice email our InvoiceEmailler checks to see whether the next-gen-ecomm feature is enabled. If it is then the emailer adds some extra order cancellation content to the email.
Happily, any problem in software can be solved by adding a layer of indirection. We can decouple a toggling decision point from the logic behind that decision like so:
Inversion of Decision
In software design we can often solve these coupling issues by applying Inversion of Control. This is true in this case. Here’s how we might decouple our invoice emailer from our feature flagging infrastructure:
We also introduced a FeatureAwareFactory to centralize the creation of these decision-injected objects. This is an application of the general Dependency Injection pattern. If a DI system were in play in our codebase then we’d probably use that system to implement this approach.
Avoiding conditionals
In our examples so far our Toggle Point has been implemented using an if statement. This might make sense for a simple, short-lived toggle. However point conditionals are not advised anywhere where a feature will require several Toggle Points, or where you expect the Toggle Point to be long-lived. A more maintainable alternative is to implement alternative codepaths using some sort of Strategy pattern:
Toggle Configuration
Dynamic routing vs dynamic configuration
Prefer static configuration
Approaches for managing toggle configuration
While static configuration is preferable there are cases such as Ops Toggles where a more dynamic approach is required. Let’s look at some options for managing toggle configuration, ranging from approaches which are simple but less dynamic through to some approaches which are highly sophisticated but come with a lot of additional complexity.
Hardcoded Toggle Configuration
Slightly more sophisticated than the commenting approach is the use of a preprocessor’s #ifdef feature, where available.
Because this type of hardcoding doesn’t allow dynamic re-configuration of a toggle it is only suitable for feature flags where we’re willing to follow a pattern of deploying code in order to re-configure the flag.
Parameterized Toggle Configuration
The build-time configuration provided by hardcoded configuration isn’t flexible enough for many use cases, including a lot of testing scenarios. A simple approach which at least allows feature flags to be re-configured without re-building an app or service is to specify Toggle Configuration via command-line arguments or environment variables. This is a simple and time-honored approach to toggling which has been around since well before anyone referred to the technique as Feature Toggling or Feature Flagging. However it comes with limitations. It can become unwieldy to coordinate configuration across a large number of processes, and changes to a toggle’s configuration require either a re-deploy or at the very least a process restart (and probably privileged access to servers by the person re-configuring the toggle too).
Toggle Configuration File
Another option is to read Toggle Configuration from some sort of structured file. It’s quite common for this approach to Toggle Configuration to begin life as one part of a more general application configuration file.
With a Toggle Configuration file you can now re-configure a feature flag by simply changing that file rather than re-building application code itself. However, although you don’t need to re-build your app to toggle a feature in most cases you’ll probably still need to perform a re-deploy in order to re-configure a flag.
Toggle Configuration in App DB
Using static files to manage toggle configuration can become cumbersome once you reach a certain scale. Modifying configuration via files is relatively fiddly. Ensuring consistency across a fleet of servers becomes a challenge, making changes consistently even more so. In response to this many organizations move Toggle Configuration into some type of centralized store, often an existing application DB. This is usually accompanied by the build-out of some form of admin UI which allows system operators, testers and product managers to view and modify Features Flags and their configuration.
Distributed Toggle Configuration
Some of these systems (such as Consul) come with an admin UI which provides a basic way to manage Toggle Configuration. However at some point a small custom app for administering toggle config is usually created.
Overriding configuration
So far our discussion has assumed that all configuration is provided by a singular mechanism. The reality for many systems is more sophisticated, with overriding layers of configuration coming from various sources. With Toggle Configuration it’s quite common to have a default configuration along with environment-specific overrides. Those overrides may come from something as simple as an additional configuration file or something sophisticated like a Zookeeper cluster. Be aware that any environment-specific overriding runs counter to the Continuous Delivery ideal of having the exact same bits and configuration flow all the way through your delivery pipeline. Often pragmatism dictates that some environment-specific overrides are used, but striving to keep both your deployable units and your configuration as environment-agnostic as possible will lead to a simpler, safer pipeline. We’ll re-visit this topic shortly when we talk about testing a feature toggled system.
Per-request overrides
An alternative approach to a environment-specific configuration overrides is to allow a toggle’s On/Off state to be overridden on a per-request basis by way of a special cookie, query parameter, or HTTP header. This has a few advantages over a full configuration override. If a service is load-balanced you can still be confident that the override will be applied no matter which service instance you are hitting. You can also override feature flags in a production environment without affecting other users, and you’re less likely to accidentally leave an override in place. If the per-request override mechanism uses persistent cookies then someone testing your system can configure their own custom set of toggle overrides which will remain consistently applied in their browser.
I elaborate on this technique for cookie-based overrides in this post and have also described a ruby implementation open-sourced by myself and a Thoughtworks colleague.
Working with feature-flagged systems
While feature toggling is absolutely a helpful technique it does also bring additional complexity. There are a few techniques which can help make life easier when working with a feature-flagged system.
Expose current feature toggle configuration
It’s always been a helpful practice to embed build/version numbers into a deployed artifact and expose that metadata somewhere so that a dev, tester or operator can find out what specific code is running in a given environment. The same idea should be applied with feature flags. Any system using feature flags should expose some way for an operator to discover the current state of the toggle configuration. In an HTTP-oriented SOA system this is often accomplished via some sort of metadata API endpoint or endpoints. See for example Spring Boot’s Actuator endpoints.
Take advantage of structured Toggle Configuration files
It’s typical to store base Toggle Configuration in some sort of structured, human-readable file (often in YAML format) managed via source-control. There are some additional benefits we can derive from this file. Including a human-readable description for each toggle is surprisingly useful, particularly for toggles managed by folks other than the core delivery team. What would you prefer to see when trying to decide whether to enable an Ops toggle during a production outage event: basic-rec-algo or «Use a simplistic recommendation algorithm. This is fast and produces less load on backend systems, but is way less accurate than our standard algorithm.»? Some teams also opt to include additional metadata in their toggle configuration files such as a creation date, a primary developer contact, or even an expiration date for toggles which are intended to be short lived.
Manage different toggles differently
As discussed earlier, there are various categories of Feature Toggles with different characteristics. These differences should be embraced, and different toggles managed in different ways, even if all the various toggles might be controlled using the same technical machinery.
Let’s revisit our previous example of an ecommerce site which has a Recommended Products section on the homepage. Initially we might have placed that section behind a Release Toggle while it was under development. We might then have moved it to being behind an Experiment Toggle to validate that it was helping drive revenue. Finally we might move it behind an Ops Toggle so that we can turn it off when we’re under extreme load. If we’ve followed the earlier advice around de-coupling decision logic from Toggle Points then these differences in toggle category should have had no impact on the Toggle Point code at all.
Feature Toggles introduce validation complexity
We can see that with a single toggle in play this introduces a requirement to double up on at least some of our testing. With multiple toggles in play we have a combinatoric explosion of possible toggle states. Validating behavior for each of these states would be a monumental task. This can lead to some healthy skepticism towards Feature Flags from folks with a testing focus.
Happily, the situation isn’t as bad as some testers might initially imagine. While a feature-flagged release candidate does need testing with a few toggle configurations, it is not necessary to test *every* possible combination. Most feature flags will not interact with each other, and most releases will not involve a change to the configuration of more than one feature flag.
a good convention is to enable existing or legacy behavior when a Feature Flag is Off and new or future behavior when it’s On.
So, which feature toggle configurations should a team test? It’s most important to test the toggle configuration which you expect to become live in production, which means the current production toggle configuration plus any toggles which you intend to release flipped On. It’s also wise to test the fall-back configuration where those toggles you intend to release are also flipped Off. To avoid any surprise regressions in a future release many teams also perform some tests with all toggles flipped On. Note that this advice only makes sense if you stick to a convention of toggle semantics where existing or legacy behavior is enabled when a feature is Off and new or future behavior is enabled when a feature is On.
If your feature flag system doesn’t support runtime configuration then you may have to restart the process you’re testing in order to flip a toggle, or worse re-deploy an artifact into a testing environment. This can have a very detrimental effect on the cycle time of your validation process, which in turn impacts the all important feedback loop that CI/CD provides. To avoid this issue consider exposing an endpoint which allows for dynamic in-memory re-configuration of a feature flag. These types of override becomes even more necessary when you are using things like Experiment Toggles where it’s even more fiddly to exercise both paths of a toggle.
This ability to dynamically re-configure specific service instances is a very sharp tool. If used inappropriately it can cause a lot of pain and confusion in a shared environment. This facility should only ever be used by automated tests, and possibly as part of manual exploratory testing and debugging. If there is a need for a more general-purpose toggle control mechanism for use in production environments it would be best built out using a real distributed configuration system as discussed in the Toggle Configuration section above.
Where to place your toggle
Toggles at the edge
Placing Toggle Points at the edges also makes sense when you are controlling access to new user-facing features which aren’t yet ready for launch. In this context you can again control access using a toggle which simply shows or hides UI elements. As an example, perhaps you are building the ability to log in to your application using Facebook but aren’t ready to roll it out to users just yet. The implementation of this feature may involve changes in various parts of your architecture, but you can control exposure of the feature with a simple feature toggle at the UI layer which hides the «Log in with Facebook» button.
It’s interesting to note that with some of these types of feature flag the bulk of the unreleased functionality itself might actually be publicly exposed, but sitting at a url which is not discoverable by users.
Toggles in the core
There are other types of lower-level toggle which must be placed deeper within your architecture. These toggles are usually technical in nature, and control how some functionality is implemented internally. An example would be a Release Toggle which controls whether to use a new piece of caching infrastructure in front of a third-party API or just route requests directly to that API. Localizing these toggling decisions within the service whose functionality is being toggled is the only sensible option in these cases.
Managing the carrying cost of Feature Toggles
Savvy teams view their Feature Toggles as inventory which comes with a carrying cost, and work to keep that inventory as low as possible.
Savvy teams view the Feature Toggles in their codebase as inventory which comes with a carrying cost and seek to keep that inventory as low as possible. In order to keep the number of feature flags manageable a team must be proactive in removing feature flags that are no longer needed. Some teams have a rule of always adding a toggle removal task onto the team’s backlog whenever a Release Toggle is first introduced. Other teams put «expiration dates» on their toggles. Some go as far as creating «time bombs» which will fail a test (or even refuse to start an application!) if a feature flag is still around after its expiration date. We can also apply a Lean approach to reducing inventory, placing a limit on the number of feature flags a system is allowed to have at any one time. Once that limit is reached if someone wants to add a new toggle they will first need to do the work to remove an existing flag.
Acknowledgements
Thanks to Brandon Byars and Max Lincoln for providing detailed feedback and suggestions to early drafts of this article. Many thanks to Martin Fowler for support, advice and encouragement. Thanks to my colleagues Michael Wongwaisayawan and Leo Shaw for editorial review, and to Fernanda Alcocer for making my diagrams look less ugly.
09 October 2017: highlight feature flag as a synonym
08 February 2016: final part: complete article published
05 February 2016: part 7: working with toggled systems
02 February 2016: part 6: toggle configuration
28 January 2016: part 5: Implementation techniques
27 January 2016: part 4: managing different categories of toggles
22 January 2016: part 3: ops and permissioning toggles



