NUMA и что про него знает vSphere?
Я думаю, многие уже успели заглянуть и прочитать эту статью на английском в моем блоге, но для тех кому все таки комфортней читать на родном языке, нежели иностранном (как сказали бы на dirty.ru – на анти-монгольском), я перевожу очередную свою статью.
Вы уже наверняка знаете, что NUMA это неравномерный доступ к памяти. В настоящий момент эта технология представлена в процессорах Intel Nehalem и AMD Opteron. Честно говоря, я, как практикующий по большей части сетевик, всегда был уверен, что все процессоры равномерно борются за доступ к памяти между собой, однако в случае с NUMA процессорами мое представление сильно устарело.

Приблизительно так это выглядело до появления нового поколения процессеров.
В новой же архитектуре каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти и образует NUMA узел. То есть при 4 процессорах и 64 Гбайт памяти у вас будет 4 NUMA узла, каждый с 16 Гбайт памяти.
Насколько я понял, новый подход к распределению доступа к памяти был изобретен в силу того, что современные » target=»_blank»>сервера настолько напичканы процессорами и памятью, что становится технологически и экономически невыгодно обеспечивать доступ к памяти через единственную общую шину. Что в свою очередь может вести к соперничеству за полосу пропускания между процессорами, ну и к более низкой масштабируемости производительности самих » target=»_blank»>серверов. Новый подход привносит 2 новых понятия – Локальная память и Удаленная память. В то время как к локальной памяти процессор обращается напрямую, то к Удаленной памяти ему приходится обращаться старым дедовским методом, через общую шину, что означает более высокую задержку. Это также означает, что для эффективного использования новой архитектуры наша ОС понимать, что она работает на NUMA узле и правильно управлять своими проложениями/процессами, иначе ОС просто рискует оказаться в ситуации, когда приложение исполняется на процессоре одного узла, в то время как его (приложения) адресное пространство памяти располагается на другом узле. Быстрый поиск показал, что NUMA архитектура поддерживается Майкрософт начиная с Windows 2003 и Vmware – как минимум с ESX Server 2.
Не уверен, что в GUI как то можно увидеть данные NUMA узла, но определенно это можно посмотреть в esxtop.
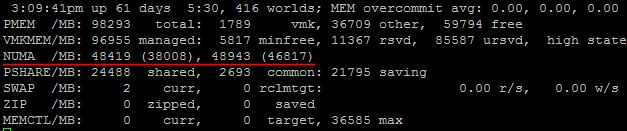
Итак, тут мы можем наблюдать, что в нашем » target=»_blank»>сервере 2 NUMA узла, и что в каждом их них 48 Гбайт памяти. Вот этот документ говорит, что первое значение означает количество локальной памяти в NUMA узле, а второе, в скобочках – количество свободной памяти. Однако, пару раз на своих продакшн » target=»_blank»>серверах я наблюдал второе значение выше, чем первое, и никакого объяснения этому найти не смог.
Итак, как только ESX » target=»_blank»>сервер обнаруживает, что он работает на » target=»_blank»>сервере с NUMA архитектурой, он незамедлительно включает NUMA планировщик, который в свою очередь заботится о виртуальных машинах и о том, чтобы все vCPU каждой машины находились в пределах одного NUMA узла. В предыдущих версиях ESX (до 4.1) для эффективной работы на NUMA системах максимальное количество vCPU виртуальной машины всегда ограничивалось количеством ядер на одном процессоре. Иначе NUMA планировщик просто игнорировал эту ВМ и vCPU равномерно распределялись поверх всех доступных ядер. Однако в ESX 4.1 была представлена новая технология, называемая Wide VM. Она позволяет нам назначать в ВМ большее количество vCPU, чем ядер на процессоре. Согласно Vmware документу планировщик разбивает нашу «широкую виртуальную машину» на несколько NUMA клиентов и затем уже каждый NUMA клиент обрабатывается по стандартной схеме, в пределах одного NUMA узла. Однако, память все таки будет разрозненной между выбранными NUMA узлами этой Wide VM, на которых работают vCPU виртуальной машины. Это происходит потому, что предсказать к какому участку памяти обратится тот или иной vCPU NUMA клиент практически невозможно. Несмотря на это, Wide VM все равно предоставляют существенно улучшенный механизм доступа к памяти по сравнению со стандартным «размазыванием» виртуальной машины поверх всех NUMA узлов.
Еще одна замечательная особенность NUMA планировщика это то, что он не только решает где расположить виртуальную машину при ее запуске, но и постоянно следит за ее соотношением локальной и удаленной памяти. И если это значение уходит ниже порога (по неподтвержденной инфо – 80%), то планировщик начинает мигрировать ВМ в другой NUMA узел. Более того ESX будет контролировать скорость миграции чтобы избежать излишней загруженности общей шины, через которую общаются все NUMA узлы.
Стоит также отметить, что при установке в памяти » target=»_blank»>сервер вы должны уставновить память в правильные слоты, т.к. за распределение памяти между NUMA узлами отвечает не NUMA планировщик, а именно физическая архитектура » target=»_blank»>сервера.
Ну и напоследок, немного полезной информации, которую вы можете подчерпнуть из esxtop.

Краткое описание значений:
NHN Номер NUMA узла
NMIG Количество миграций виртуальной машины между NUMA узлами
NMREM Количество удаленной памяти, используемой ВМ
NLMEM Количество локальной памяти, используемой ВМ
N&L Процентное соотношение между локальной и удаленной памятью
GST_ND(X) Количество выделенной памяти для ВМ на узле X
OVD_ND(X) Количество памяти потраченной на накладные расходы на узле X
Хотелось бы отметить, что как обычно вся эта статья всего лишь компиляция того, что мне показалось интересным из прочитанного за последнее время в блогах таких товарищей как Frank Denneman и Duncan Epping, а также официальных документов Vmware.
NUMизматика, NUMерология и просто о NUMA
Три Богатыря
И начнем с отрицания отрицания. То есть, посмотрим на Uniform Memory Access (Однородный доступ к памяти), известный также так SMP (Symmetric Multi Processing – Симметричная Многопроцессорная Обработка).
SMP – это архитектура, в которой процессоры соединены с общей системной памятью при помощи шины или подобного соединения)симметрично, и имеют к ней равный однородный доступ. Именно так, как показано на схеме ниже (на примере двух CPU), были устроены все многопроцессорные машины Intel, когда контроллер памяти (MCH/MGCH), больше известный как «Северный Мост» (“NorthBridge”) находился в чипсете.
Недостаток SMP очевиден — при росте числа CPU, шина становится узким местом, значительно ограничивая производительность приложений, интенсивно использующих память. Именно поэтому SMP системы почти не масштабируются, два-три десятка процессоров для них – это уже теоретический предел.
Альтернатива SMP для производительных вычислений – это MPP (Massive Parallel Processing).
MPP — архитектура, разделяющая систему на многочисленные узлы, процессоры в которых имеют доступ исключительно к локальным ресурсам. MPP прекрасно масштабируется, но не столь прекрасно программируется. А именно — не обеспечивает встроенного механизма обмена данными между узлами. То есть, реализовывать коммуникации, распределение и планировку задач на узлах должен выполняемый на MPP софт, что подходит далеко не для всех задач и их программистов.
И, наконец, NUMA (Non-Uniform Memory Access). Эта архитектура объединяет положительные черты SMP и MPP. NUMA система разделяется на множественные узлы, имеющие доступ как к своей локальной памяти, так и к памяти других узлов (логично называемой «удаленной»). Естественно, доступ к удаленной памяти оказывается гораздо медленнее, чем к локальной. Оттуда и название – «неоднородный доступ к памяти». Это – не только название, но и недостаток архитектуры NUMA, для смягчения которого может потребоваться специальная оптимизация софта, о которой — дальше.
Вот как выглядит двухсокетная NUMA система Intel Xeon (а именно там дебютировала Intel NUMA) с контроллерами памяти, интегрированными в CPU.
Процессоры здесь соединены QPI — Intel QuickPath соединением «точка-точка» с высокой пропускной способностью и низкой задержкой передачи.
На рисунке не показан кеш процессоров, но все три уровня кеш памяти, конечно же, там есть. А значит, есть и особенность NUMA, о которой необходимо сказать: NUMA, используемая в системах Intel, поддерживает когерентность кешей и разделяемой памяти (то есть, соответствие данных между кешами разных CPU), поэтому ее иногда называют ccNUMA — cache coherent NUMA. Это означает наличие специального аппаратного решения для согласования содержимого кешей, а также и памяти, когда более чем один кеш хранит одну и ту же ее часть. Конечно, такое общение кешей ухудшает общую производительность системы, но без него программировать систему с непредсказуемым текущим состоянием данных было бы крайне интересно затруднительно. Для уменьшения влияния этого эффекта, следует избегать ситуаций, когда несколько процессоров сразу работают с одним блоком памяти (не обязательно с одной переменной!). Именно так и пытаются поступить продукты, поддерживающие NUMA.
Таким образом, от железа мы плавно перешли к программному обеспечению и производительности NUMA систем.
Итак, NUMA поддерживается следующими OS:
Windows Server 2003, Windows XP 64-bit и Windows Vista – до 64 логических процессоров,
Windows 7, Windows Server 2008 R2 – полная поддержка.
Linux OS kernel: 2.6 и выше, UNIX OS — Solaris и HP-Unix.
Если говорить о базах данных, то NUMA поддерживается Oracle8i, Oracle9i, Oracle10g и Oracle11g, а также SQL Server 2005 и SQL Server 2008.
Поддержка NUMA реализована и в Java SE 6u2, JVM 1.6, а также .NET runtime на вышеупомянутых версиях Windows.
Полностью поддерживает NUMA математическая библиотека Intel – MKL.
«Поддержка NUMA» означает следующее – продукт знает о топологии NUMA машины, на которой исполняется, и пытается использовать ее максимально эффективно, то есть, организовать работу потоков так, чтобы они в полной мере использовали память своего узла (того, на котором исполняется данный поток) и минимально – чужих. Ключевое слово здесь – «пытается», так как сделать это в общем случае возможно не всегда.
Поэтому может случиться, что продукт, не поддерживающий NUMA, то есть, просто не знающий о ней, что совсем не мешает ему запускаться и исполняться на NUMA-системах, покажет не худшую производительность, чем официально поддерживающий NUMA. Пример такого продукта — знаменитая библиотека Intel Threading Building Blocks.
Именно поэтому в BIOS мультисокетных » target=»_blank»>серверов с NUMA есть специальный пункт «Разрешить\запретить NUMA». Конечно же, от запрета NUMA в BIOS топология системы никак не изменится — удаленная память не приблизится. Произойдет только следующее – система не сообщит ОС и ПО о том, что она NUMA, а значит, распределение памяти и планировка потоков будут «обычными», такими как на симметричных многопроцессорных системах.
Если BIOS разрешает NUMA, то операционная система сможет узнать о конфигурации NUMA узлов из System Resource Affinity Table (SRAT) в Advanced Configuration and Power Interface (ACPI). Приложения могут получить такую информацию, используя библиотеку libnuma в Linux, а сами понимаете, на каких системах — Windows NUMA interface.
Эта информация – начало поддержки NUMA вашим приложением. За ним должна следовать непосредственно попытка максимально эффективно использовать NUMA. Общие слова на эту тему уже сказаны, для дальнейших пояснений перейду к частному примеру.
Допустим, вы выделяете память при помощи malloc. Если дело происходит в Linux, то malloc только резервирует память, а ее физическое выделение происходит только при фактическом обращении к данной памяти. В этом случае память автоматически выделится на том узле, который ее и использует, что очень хорошо для NUMA. В Windows же malloc работает по-другому, он выделяет физическую память непосредственно при аллоцировании, то есть, на узле выделяющего память потока. Поэтому она вполне может оказаться удаленной для других потоков, ее использующих. Но есть в Windows и дружественное к NUMA выделение памяти. Это VirtualAlloc, который может работать точно также, как malloc в Linux. Еще более продвинутый вариант — VirtualAllocExNuma из Windows NUMA API.
Следующий простой пример, использующий OpenMP,
можно подружить с NUMA, обеспечив инициализацию данных каждым потоком, вызывающую соответствующую привязку физической памяти к использующему ее узлу:
Отдельным пунктом здесь надо упомянуть Affinity — принудительную привязку потоков к конкретным процессорам, предотвращающую возможную переброску операционной системой потоков между процессорами и могущую вызвать потенциальный «отрыв» потоков от своей используемой локальной памяти.
Для установки Affinity имеются соответствующие API как в Linux, так и в Windows ( стандартный Windows API, и NUMA WinAPI). Также функциональность для установки привязки присутствуют во многих параллельных библиотеках (например, в показанном выше примере OpenMP за это отвечает переменная окружения KMP_AFFINITY ).
Но надо понимать, что во-первых, affinity срабатывает не всегда (для системы это, скорее, намек, чем приказ), а во-вторых, положительный эффект от установки Affinity будет только в том случае, когда вы полностью контролируете систему, то есть, на ней работает исключительно ваше приложение, а сама ОС не сильно нагружает систему. Если же, как это чаще всего бывает, приложений несколько, причем, они интенсивно используют CPU и память, пытаясь при этом привязаться к одному процессору, ничего не зная друг о друге, да и ОС конкурирует за те же ресурсы, то от использования Affinity может быть больше вреда, чем пользы
Производительность.
1.4 раза), пропускная способность локальной памяти превосходит удаленную на 40% ”.
На вашей реальной системе эти приблизительные данные могут быть получены при помощи бесплатной утилиты Microsoft Sysinternals — CoreInfo, оценивающей относительную «стоимость» доступа к памяти разных узлов NUMA. Результат, конечно, сильно приблизительный, но некоторые выводы сделать позовляет.
Пример результата Coreinfo:
Как видите, разница составляет всего чуть более 5%! Результат приятно удивительный. И это – случай максимальной разницы, достигаемый при 32 одновременно работающих потоках с запросами (при другом количестве потоков разница еще меньше).
Так нужно ли оптимизировать для NUMA? Зайду издалека. Хотя у меня нет времени убираться дома, зато есть время читать советы по уборке :). И один из полезных, виденных мной советов такой — чтобы меньше убираться, надо избежать потенциального беспорядка, для чего старайтесь хранить все вещи как можно ближе к месту их использования.
Теперь замените «вещи» на «данные», а «квартиру» на «программу» и увидите один из способов достичь порядка в ваших программах. Но это как раз и будет NUMA-оптимизация, о которой вы сейчас и прочли.
sidadm
записки SAP Basis консультанта
Полезное
вторник, 13 июля 2021 г.
VMware и NUMA: выбор правильного размера памяти VM
Современные » target=»_blank»>серверные решения на базе архитектуры x86, которые сейчас используются почти во всех программно-аппаратных комплексах, имеют некоторые нюансы. Многопроцессорные » target=»_blank»>сервера, имеющие на материнской плате 2, 4 или даже 8 процессорных сокетов, являются по сути NUMA-архитектурой. NUMA (Non-Uniform Memory Architecture) означает, что каждый процессорный сокет имеет свой пул локальных модулей оперативной памяти и такая связка называется узлом NUMA (рис. 1).
 |
| Рис. 1. UMA и NUMA архитектуры. |
Все процессорные ядра и вся оперативная память объединены в одну систему, но обращение процессора к своим (локальным) модулям памяти происходит с большей скоростью (или меньшими задержками), чем к памяти соседнего процессора.
Все современные операционные системы и программные решения более высокого уровня (например, виртуальный гипервизор или СУБД) понимают особенности этой архитектуры. В идеале, это понимание позволяет большинство операций выполнять с памятью локального процессора, не ходя в «дальние края» за памятью соседа.
vSphere от VMware тоже прекрасно разбирается в NUMA. При конфигурировании виртуальной машины (если вы не активируете опцию «Enable CPU Hot Add») и при её работе гипервизор будет размещать виртуальные процессорные ядра (vCPU) и память виртуальной машины в один узел NUMA. Причём, эта функция работает по умолчанию, ничего отдельно настраивать не надо.
Хочу на своём примере показать недостаточно корректную настройку размера виртуальных машин, с учётом NUMA архитектуры. На проекте, про который хочу рассказать, были » target=»_blank»>сервера двух типов:
Понимая, всю ситуацию с NUMA архитектурой я разместил на » target=»_blank»>серверах первого типа виртуальные машины с характеристиками:
Но после прокачки своих знаний по VMware, мне открылось, что я совершил ошибку при конфигурации объёмов памяти.
 |
| Рис. 2. Основной экран утилиты esxtop. |
 |
| Рис. 3. Активация просмотра статистики по NUMA узлам. |
После этого на экране появится несколько важных полей:
Последний параметр помогает проанализировать итог работы виртуальной машины на NUMA узлах. Если он равен 100%, значит производительность оптимальна. Если же ниже 100%, значит не всегда в процессе работы на реальных процессорных ядрах для текущей виртуальной машины идёт попадание в память локального узла NUMA.
По моей ситуации. Первые две большие виртуальные машины не всегда попадают в память локального NUMA узла (рис. 4 и 5). Напомню, что обе машины работают на » target=»_blank»>серверах с размером узла NUMA = 16 ядер (с учётом HT) + 96 Гб.
 |
| Рис. 4. Статистика по NUMA виртуальной машины 8 vCPU + 96 Гб. |
 |
| Рис. 5. Статистика по NUMA виртуальной машины 16 vCPU + 192 Гб. |
«Небольшие» виртуальные машины, работающие на » target=»_blank»>серверах второго типа (с размером узла NUMA = 16 ядер (с учётом HT) + 128 Гб памяти), отлично умещаются в локальных NUMA узлах (рис. 6). Забора «чужой» памяти нет, всё работает оптимально.
 |
| Рис. 6. Статистика по NUMA виртуальной машины, работающей на » target=»_blank»>сервере второго типа. |
Если у меня будет возможность, то я переконфигурирую данные виртуальные машины, которые не оптимально попадают в узлы NUMA. И потом поделюсь с вами результатами статистики.
Update: результаты оптимизации можно найти в этом посте.
Non-Uniform Memory Architecture (NUMA): исследование подсистемы памяти двухпроцессорных платформ AMD Opteron с помощью RightMark Memory Analyzer
Неоднородная архитектура памяти (NUMA) как особый вид организации подсистемы памяти существует уже довольно давно. Ее наиболее наглядный и доступный вариант представлен подсистемой памяти многопроцессорных платформ AMD Opteron, и существует он, можно сказать, с момента анонса самих процессоров AMD Opteron 200-х и 800-х серий, поддерживающих многопроцессорные конфигурации. Вместе с тем, изучение этой архитектуры памяти (здесь и далее мы будем иметь в виду исключительно ее «AMD-шный вариант») на низком уровне, анализ ее преимуществ и недостатков до сих пор не проводились. Этим мы и решили заняться в настоящей статье, благо в распоряжении нашей тестовой лаборатории оказалась очередная двухпроцессорная система на базе процессоров AMD Opteron. Но для начала, напомним основные особенности этой архитектуры.
Большинство типовых многопроцессорных систем реализовано в виде симметричной многопроцессорной архитектуры (SMP), предоставляющей всем процессорам общую системную шину (а, следовательно, и шину памяти).
С одной стороны, эта схема обеспечивает практически одинаковые задержки при доступе к памяти со стороны любого процессора. Но с другой стороны, общая системная шина является потенциальным узким местом всей подсистемы памяти по такому не менее (и даже намного более) важному показателю, как пропускная способность. Действительно, если многопоточное приложение оказывается требовательным к пропускной способности, его производительность будет во многом сдерживаться такой организацией подсистемы памяти.
Что же предлагает AMD в своем варианте неоднородной архитектуры памяти NUMA (ее полное название Cache-Coherent Non-Uniform Memory Architecture, ccNUMA)? Все предельно просто поскольку процессоры AMD64 обладают интегрированным контроллером памяти, каждый процессор в многопроцессорной системе наделен своей «собственной» памятью. При этом, процессоры связаны между собой посредством шины HyperTransport, не имеющей прямого отношения к подсистеме памяти (чего не скажешь о традиционной FSB).
В случае NUMA-системы задержки при обращении процессора к «своей» памяти оказываются невысоки (в особенности, по сравнению с SMP-системой). В то же время, доступ к «чужой» памяти, принадлежащей другому процессору, сопровождается более высокими задержками. Понятие «неоднородности» такой организации памяти берет свое начало именно отсюда. Вместе с тем, нетрудно догадаться, что при правильной организации доступа к памяти (когда каждый процессор оперирует данными, находящимися исключительно в «своей» памяти) такая схема будет выгодно отличаться от классического SMP-решения благодаря отсутствию ограничения по пропускной способности общей системной шины. Суммарная пиковая пропускная способность подсистемы памяти в этом случае будет равняться удвоенной пропускной способности используемых модулей памяти.
Однако «правильная организация доступа к памяти» здесь — ключевое и критически важное понятие. Платформы с архитектурой NUMA должны поддерживаться как со стороны ОС (хотя бы для того, чтобы сама система и приложения могли «увидеть» память всех процессоров, как единый блок памяти), так и со стороны приложений. Последние версии Windows XP (SP2) и Windows Server 2003 полностью поддерживают NUMA-системы (для 32-разрядных версий необходимо включение режима Physical Address Extension (ключ /PAE в boot.ini), который, к счастью, для AMD64-платформ включен по умолчанию, поскольку необходим для реализации Data Execution Prevention). Что касается приложений, здесь, прежде всего, имеется в виду нежелательность возникновения ситуации, когда приложение размещает свои данные в области памяти одного процессора, после чего обращается к ним с другого процессора. А как влияет соблюдение или несоблюдение этой рекомендации, мы сейчас и рассмотрим.
Конфигурация тестового стенда и ПО
Результаты исследований
Исследование проводилось в стандартном режиме тестирования подсистемы памяти любой платформы. Измерялись: средняя реальная пропускная способность памяти (ПСП) при операциях простого линейного чтения и записи данных из памяти/в память, максимальная реальная ПСП при операциях чтения (с программной предвыборкой данных, Software Prefetch) и записи (методом прямого сохранения данных, Non-Temporal Store), а также латентность памяти при псевдослучайном и случайном обходе 16-МБ блока данных.
Некоторым отличием от общепринятой методологии явилась «привязка» тестов к определенному физическому процессору возможность, уже давно реализованная в RMMA, да все никак не опробованная на практике. Ее суть такова: размещение блока данных в памяти всегда осуществляется первым процессором (что для NUMA-aware OS означает, что блок будет выделен в физической памяти первого процессора), после чего запуск тестов может быть осуществлен как на том же, первом, так и на любом другом присутствующем в системе процессоре. Это позволяет нам оценить скорость обмена данными между процессором и памятью (и прочие характеристики) как «своей», так и «чужой», принадлежащей соседнему процессору.
Симметричный режим «2+2», No Node Interleave
Настроек подсистемы памяти в BIOS двухпроцессорной системы AMD Opteron оказалось довольно много. А именно, настраиваются как минимум три параметра (по принципу Disabled/Enabled, или Disabled/Auto), что дает нам общее число вариантов — 8. Это: Node Interleave (чередование памяти между «узлами», то есть интегрированными контроллерами процессоров — замечательная возможность, которую мы подробно рассмотрим ниже), Bank Interleave (классическое чередование доступа к логическим банкам модулей памяти), а также Memory Swizzle (нечто похожее на Bank Interleave, но так до конца и не понятое :)). Поскольку изменение последнего параметра не оказывало ощутимого влияния на результаты тестов, было решено оставить его по умолчанию (Enabled). Остальные параметры варьировались, и в первой серии тестов была выбрана симметричная конфигурация «2+2» (по 2 модуля на каждый процессор), Node Interleave был отключен, а параметр Bank Interleave варьировался между Disabled и Auto (последнее означает, что чередование банков осуществляется в соответствии с характеристиками самого модуля).
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3618 (±3) | 2369 (±2) | 3654 (±5) | 2387 (±2) |
| Средняя реальная ПСП на запись, МБ/с | 1616 (±2) | 1415 (±2) | 2417 (±56) | 1878 (±29) |
| Максимальная реальная ПСП на чтение, МБ/с | 6286 | 3116 | 6344 | 3133 |
| Максимальная реальная ПСП на запись, МБ/с | 5924 | 3032 | 6143 | 3033 |
| Минимальная латентность псевдослучайного доступа, нс | 45.6 | 70.9 | 44.1 | 70.5 |
| Максимальная латентность псевдослучайного доступа, нс | 48.3 | 74.7 | 47.3 | 74.3 |
| Минимальная латентность случайного доступа, нс | 74.7 | 112.3 | 74.7 | 112.3 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.3 | 78.6 | 116.3 |
Доступ процессора к «своей» памяти (CPU 0) дает вполне привычную картину, пожалуй, даже отлично выглядящую, учитывая, что используется регистровая память DDR-400 с не самыми быстрыми таймингами (3-3-3-8). Включение Bank Interleave приводит к улучшению некоторых показателей ПСП (особенно средней реальной ПСП на запись, с одновременным увеличением разброса ее величины) и практически не влияет на задержки.
Обращение процессора к «чужой» памяти (CPU 1) приводит к заметному ухудшению всех показателей подсистемы памяти. Прежде всего, это двукратное падение максимальной реальной ПСП на чтение/запись (получается как бы одноканальный режим доступа, но с чем связано такое ограничение не совсем понятно, поскольку частота HyperTransport в нашем случае составляет 1000 МГц, что обеспечивает пиковую пропускную способность межпроцессорного соединения 4.0 ГБ/с). Снижение средней реальной ПСП менее ощутимо, а задержки возрастают на 50-60%.
Таким образом, «неоднородность» подсистемы памяти, о которой мы упоминали в теоретической части — налицо (и, разумеется, не только в терминах латентности, но и ПСП). Что подтверждает необходимость использования не только NUMA-aware OS, но и специально оптимизированных многопоточных приложений, в которых каждый поток самостоятельно выделяет память под свои данные и работает со своей областью памяти. В противном случае (однопоточные приложения и многопоточные, «не задумывающиеся» о правильном с точки зрения NUMA размещении данных в памяти) следует ожидать снижение производительности подсистемы памяти. Рассмотрим это на примере однопоточных приложений, на сегодняшний день по-прежнему представляющих большинство ПО. Известно, что в многопроцессорной системе диспетчер ОС назначает приложениям процессорное время так, чтобы разделить его поровну между всеми имеющимися процессорами (таким образом, в случае двухпроцессорной системы примерно 50% приходится на первый процессор, и 50% — на второй). Таким образом, момент размещения памяти обязательно придется на какой-нибудь из процессоров (например, CPU0), в то время как код приложения, осуществляющий доступ к этим данным, будет исполняться как на CPU0, так и на CPU1. И половину времени подсистема памяти будет работать с полной эффективностью, а половину — со вдвое сниженной, как показывают наши тесты. Поэтому, как это ни странно, эффективность работы с памятью таких приложений можно повысить, принудительно «привязав» их к одному из процессоров (задав Process Affinity), что, в общем-то, сделать не так и сложно.
Хуже будет обстоять дело в случае неоптимизированных под NUMA многопоточных приложений, так же размещающих свои данные в памяти лишь одного из процессоров. Такая конфигурация может даже уступать традиционным SMP-вариантам суммарная пропускная способность будет ограничена пропускной способностью одного из контроллеров памяти, а задержки доступа будут неравномерными. Тем не менее, даже в этом непростом случае архитектура NUMA в ее AMD-шном воплощении предусматривает выход из ситуации, о котором ниже.
Несимметричный режим «4+0»
А пока мы решили немного. «удешевить» систему — то есть имитировать ситуацию, преобладающую среди более дешевых двухпроцессорных плат под AMD Opteron, когда модули памяти можно установить всего для одного процессора — для второго процессора такая память принудительно становится «чужой». Собственно, исходя из теоретических предположений, ожидать сильно отличающихся результатов в этом случае явно не стоит — ситуация отличается ровно тем, что у «своего» процессора памяти стало в 2 раза больше, а у «чужого» ее как не было, так и нет. Поэтому приводим мы их исключительно для полноты картины.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3623 (±5) | 2375 (±2) | 3684 (±33) | 2397 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1611 (±2) | 1418 (±2) | 2090 (±136) | 1932 (±31) |
| Максимальная реальная ПСП на чтение, МБ/с | 6249 | 3128 | 6358 | 3128 |
| Максимальная реальная ПСП на запись, МБ/с | 5878 | 3032 | 6234 | 3032 |
| Минимальная латентность псевдослучайного доступа, нс | 44.3 | 70.6 | 43.9 | 70.0 |
| Максимальная латентность псевдослучайного доступа, нс | 47.6 | 74.4 | 47.1 | 73.7 |
| Минимальная латентность случайного доступа, нс | 74.7 | 111.8 | 77.0 | 111.8 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.0 | 80.7 | 115.9 |
Так оно и есть теория подтверждается практикой. Небольшие отличия наблюдаются лишь при включении Bank Interleave в этом случае несколько снижается ПСП и увеличивается ее разброс (столь сильный разброс связан с плавным возрастанием ПСП на запись при увеличении размера блока от 4 до 16 МБ). Вместе с тем, в рамках нашего исследования это не столь важно, поскольку отражает лишь внутренние особенности функционирования Bank Interleave при использовании либо двух, либо четырех конкретных модулей памяти.
Зададимся лучше более важным вопросом: означают ли наши результаты то, что можно сэкономить и использовать более дешевый вариант построения подсистемы памяти? Делать этого однозначно не стоит, причем как в случае NUMA-оптимизированных приложений, так и без них. В первом случае причина ясна хорошо оптимизированные многопоточные приложения, если они требовательны к ПСП, получат максимум от симметричной организации подсистемы памяти. А во втором случае, симметричная организация «2+2» вместо асимметричной «4+0» позволяет задействовать режим Node Interleave. или просто выиграть от правильной «привязки» приложений к процессорам.
Симметричный режим «2+2», Node Interleave
Вот мы и добрались до самого интересного момента — решения для обычных приложений, ничего не знающих об архитектуре NUMA. Суть его весьма проста, и заключается она в чередовании памяти по 4-КБ страницам между модулями, находящимися на разных «узлах» (контроллерах памяти). В случае двухпроцессорной системы можно сказать, что все четные страницы «достаются» первому процессору, а все нечетные — второму. В результате получается — независимо от того, на какой из процессоров приходится момент размещения данных в памяти, данные будут размещены поровну в пространстве памяти обоих процессоров. И независимо от того, на каком из процессоров исполняется код, половина обращений к памяти будет относиться к «своей» памяти, а половина — к «чужой». Что же, посмотрим, как это проявляет себя на практике.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 2893 (±3) | 2890 (±3) | 2899 (±5) | 2914 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1897 (±20) | 1895 (±20) | 2065 (±34) | 2070 (±34) |
| Максимальная реальная ПСП на чтение, МБ/с | 4211 | 4217 | 4220 | 4231 |
| Максимальная реальная ПСП на запись, МБ/с | 4029 | 4026 | 4029 | 4025 |
| Минимальная латентность псевдослучайного доступа, нс | 57.5 | 58.0 | 57.4 | 58.0 |
| Максимальная латентность псевдослучайного доступа, нс | 60.5 | 60.2 | 60.4 | 60.0 |
| Минимальная латентность случайного доступа, нс | 94.5 | 94.3 | 94.5 | 94.2 |
| Максимальная латентность случайного доступа, нс | 96.3 | 96.0 | 96.6 | 95.9 |
Полная симметрия по всем показателям, «неоднородности» архитектуры памяти как не бывало! Задержки при доступе к памяти при этом составляют истинно среднюю величину (например, при псевдослучайном доступе: (45 + 70) / 2 = 57.5 нс), с ПСП дела обстоят несколько хуже вместо ожидаемой теоретической величины (6.4 + 3.2 / 2) = 4.8 МБ/с мы наблюдаем лишь 4.2 МБ/с.
Заметим, однако, что примерно такие же величины мы получили бы и без включения Node Interleave для простого однопоточного приложения, не «привязанного» к определенному процессору. Более того, принудительная «привязка» приложения к процессору, как мы говорили выше, позволяет даже увеличить ПСП и снизить латентности. Таким образом, единственная адекватная область применения Node Interleave это лишь неоптимизированные многопоточные приложения, которые в противном случае будут упираться в ПСП одного из контроллеров памяти.
Заключение
| Платформа | Пиковая пропускная способность подсистемы памяти, ГБ/с (двухканальная DDR-400) | |||
|---|---|---|---|---|
| Однопоточное приложение | Несколько однопоточных приложений | Многопоточное приложение | NUMA-aware многопоточное приложение | |
| SMP | 6.4 | 6.4 | 6.4 | 6.4 |
| Несимметричная NUMA | 4.2 (6.4 * ) | 6.4 | 6.4 | 6.4 |
| Симметричная NUMA | 4.2 (6.4 * ) | 8.4 (12.8 * ) | 6.4 | 12.8 |
| Симметричная NUMA, Node Interleave | 4.2 | 8.4 | 8.4 | 8.4 |
* в случае «привязки» приложения к одному из процессоров
Итак, SMP-системы (двухпроцессорные Intel Xeon, а также. любые существующие на сегодняшний день двухъядерные процессоры) теоретическая ПСП во всех случаях ограничена цифрой 6.4 ГБ/с, ибо это пиковая ПС единой и единственной процессорной шины.
Недорогие, несимметричные NUMA-системы выглядят не многим лучше, а то и хуже традиционных SMP-систем. Хуже — в случае однопоточных приложений, если их не «привязывать» к тому процессору, который обращается с памятью. Пиковая ПСП во всех остальных случаях здесь также ограничена цифрой 6.4 ГБ/с — то есть пропускной способностью единственного имеющегося в системе интерфейса памяти.
Симметричные NUMA-системы практически во всех случаях обладают преимуществом как над SMP, так и несимметричными NUMA-системами. Достигнуть пиковой ПСП 12.8 ГБ/с на таких платформах могут либо специальные NUMA-оптимизированные приложения, либо. два обычных, однопоточных приложения, «раскиданных» каждое по своему процессору.
Наконец, что же дает симметричным NUMA-платформам включение режима Node Interleave? Преимущество можно увидеть только в одном случае неоптимизированных многопоточных приложений (да еще и, конечно же, при условии, что каждый из потоков будет интенсивно обращаться с данными, находящимися в памяти). Если же грамотно запускать однопоточные приложения, либо использовать NUMA-оптимизированные включение этого режима однозначно не нужно, оно может лишь ухудшить производительность.
Таким образом, результаты проведенных нами исследований и их анализа позволяют заключить, что NUMA однозначно более совершенная архитектура памяти по сравнению с традиционными SMP-решениями, способная в большинстве случаев обеспечить над ними преимущество по низкоуровневым характеристикам подсистемы памяти.



