Прогнозирование оттока клиентов со scikit-learn
Показатель оттока клиентов – бизнес-термин, описывающий насколько интенсивно клиенты покидают компанию или прекращают оплачивать товары или услуги. Это ключевой показатель для многих компаний, потому что зачастую приобретение новых клиентов обходится намного дороже, чем удержание старых (в некоторых случаях от 5 до 20 раз дороже).
Следовательно, понимание того, как поддерживать заинтересованность клиентов представляет собой логический фундамент для разработки стратегий и практик их удержания. В результате, предприятия стремятся получить более совершенные технологии выявления возможного ухода клиентов. Так, многие из них прибегают к методам интеллектуального анализа данных и машинного обучения.
Прогнозирование оттока клиентов имеет особенно большое значение для компаний, применяющих бизнес-модель на основе подписки. К такому типу организаций относятся мобильные операторы, операторы кабельного телевидения и компании, обслуживающие прием платежей с помощью кредитных карт.
В то же время, моделирование оттока клиентов находит широкое применение и в других областях. Например, казино используют прогнозные модели, чтобы предсказать идеальные условия в зале, позволяющие удержать игроков в Блэкджек за столом. Аналогично, авиакомпании могут предложить клиентам, у которых есть жалобы, заменить их билет на билет первого класса. Это далеко не весь список.
В этой статье мы рассмотрим моделирование оттока клиентов с помощью Python.
Постойте, не уходите!
Оказывается, для уменьшения оттока клиентов требуются существенные ресурсы. Специалисты звонят клиентам, находящимся в «зоне риска», и мотивируют их продолжать сотрудничество.
Весь же цимес в том, что мы живем в эпоху данных и располагаем мощными инструментами, позволяющими решить задачу практически любой сложности.
Джон Форман (John Forman) из компании MailChimp написал по этому поводу следующее:
«Я работаю в индустрии email-маркетинга в компании MailChimp.com. Мы помогаем компаниям рассылать информационные письма их клиентам, и каждый раз, когда кто-то использует термин «взрывная массовая рассылка» («e-mail blast»), маленькая частичка меня умирает.
Почему? Потому что электронные почтовые ящики больше не являются «черными ящиками», в которые вы словно забрасываете светошумовые гранаты. Нет, с помощью email-маркетинга (как и в случае многих других форм онлайн-взаимодействия, таких как твиты, публикации на Facebook и кампании на Pinterest) предприятия получают отклик о вовлечении аудитории на индивидуальном уровне, анализируя клики, онлайн-покупки, обмен информацией в социальных сетях и т.д. Эти данные не являются шумом. Они характеризуют ваших клиентов. Но для непосвященных, эта информация может казаться непонятным языком, например, греческим или эсперанто».
В данном контексте эффективное удержание клиентов сводится к задаче, в рамках которой, используя имеющиеся данные, необходимо отличить клиентов, собирающихся уйти, от тех, кто этого делать не собирается.
Мы рассмотрим простой пример – как использовать библиотеки Python для предсказания оттока клиентов и применить данное решение для оптимизации работы команды специалистов по их удержанию.
Набор данных
Мы будем использовать набор данных, содержащий информацию о клиентах телефонной компании. Вы можете загрузить его здесь.
Данные вполне обычные. Каждая строка представляет собой одного клиента. Столбцы содержат различную информацию, такую как номер телефона, длительность разговоров в различное время суток, размер оплаты за услуги, общее время, в течение которого клиент обслуживается компанией, а также информацию о том, покинул клиент компанию или нет.
Out ⌈2⌉:

В этой статье мы будем использовать достаточно простую статистическую модель, поэтому пространство признаков почти полностью соответствует тому, что вы видите выше. Код, представленный ниже, просто исключает не интересующие нас столбцы и преобразует строковые значения в булевы значения (поскольку модели не очень хорошо работают со строковыми значениями «yes» и «no»). Остальные числовые значения остаются без изменений.
Отлично, теперь у нас есть пространство признаков «X» и набор целевых значений «y». Вперед, к прогнозам!
Насколько хороша ваша модель?
Выразить, протестировать, повторить. Процесс реализации машинного обучения может быть каким угодно, но только не статичным. Всегда есть возможность создать новые признаки, использовать новые данные, применить новые классификаторы, у каждого из которых есть специфические параметры, доступные для настройки. И после каждого изменения крайне важно иметь возможность получить ответ на вопрос: «Действительно ли новая версия лучше предыдущей?» Каким же образом это можно реализовать?
В данной статье мы будем использовать перекрестную проверку (cross validation). Перекрестная проверка позволяет избежать переобучения (обучение и тестирование прогнозов на одних и тех же данных), обеспечивая при этом эффективное прогнозирование для каждого набора данных. Это реализуется путем систематического сокрытия различных подмножеств обучающего набора данных во время обучения моделей. После завершения обучения каждая модель тестируется на том подмножестве данных, которое было скрыто от нее при обучении. Таким образом имитируются различные наборы данных для обучения и тестирования. Если все сделано правильно, прогнозы будут «объективными».
Вот как это реализуется с помощью библиотеки scikit-learn.
Мы решили сравнить три различных алгоритма: метод опорных векторов (support vector machine, SVM), случайный лес (random forest) и метод k ближайших соседей (k-nearest neighbors, KNN). Ничего особенного здесь нет, просто подвергаем каждый алгоритм перекрестной проверке и определяем, как часто классификатор предсказывает правильный класс.
Случайный лес победил, не так ли?
Точность (precision) и полнота (recall)
Метрики не являются идеальными формулами, которые всегда выставляют высокие оценки хорошим моделям и низкие оценки плохим моделям. В сущности, они выражают некоторое «мнение» относительно эффективности модели, а человек уже самостоятельно должен делать выводы об адекватности оценки. Проблема с метрикой «правильность» (accuracy) заключается в том, что результаты не обязательно эквивалентны. Если классификатор спрогнозирует уход клиента, но клиент останется, – это не очень хорошо, но простительно. Однако если классификатор предскажет, что клиент не уйдет, я не стану предпринимать никакие действия, а клиент все же уйдет – это уже действительно плохо.
Мы используем еще одну встроенную в scikit-learn функцию для создания матрицы ошибок (confusion matrix). Матрица ошибок – это способ визуализации прогнозов классификатора, представляющий собой таблицу, демонстрирующую распределение прогнозов для данного класса. Ось X представляет истинные классы (ушел клиент или нет), а ось Y представляет классы, предсказанные моделью (прогнозы моего классификатора относительно возможного ухода клиента).
Важным вопросом является следующий: «Каково отношение количества правильно спрогнозированных уходов к общему количеству фактических уходов?» Эта метрика имеет название «полнота» (recall). По диаграммам видно, что случайный лес превосходит остальные алгоритмы по данному показателю. Притом, что было 483 фактических случая ухода клиентов (значение «1»), 330 прогнозов оказались правильными. Следовательно, «полнота» для случайного леса составляет примерно 68% (330/483 ≈ 2/3), что значительно лучше, чем результат метода опорных векторов (≈ 50%) или метода k ближайших соседей (≈ 35%).
Другой важный вопрос описывает метрику под названием «точность» (precision): «Каково отношение количества правильно спрогнозированных уходов к общему количеству спрогнозированных уходов?» Случайный лес снова превосходит остальные алгоритмы и демонстрирует «точность» около 93% (330 из 356). Метод опорных векторов немного позади – 87% (235 из 269). Метод k ближайших соседей на последнем месте – около 80%.
Хотя по точности и полноте случайный лес превосходит SVC и KNN, этот алгоритм не всегда будет на первом месте. На основе различных метрик алгоритмы получают различные оценки, поэтому понимание положительных и отрицательных сторон каждого метода оценивания должно направлять ваши дальнейшие действия.
Мыслить категориями вероятностей
Мы слегка отклоняемся от области своей специализации, но чтобы получить ответы на эти вопросы, необходим немного другой подход к прогнозированию. Библиотека scikit-learn позволяет легко перейти к вероятностям. Три моих модели имеют функцию predict_proba(), встроенную в объекты их классов. Ниже представлен тот же код перекрестной проверки всего лишь с несколькими измененными строками.
Насколько хорошо хорошее?
Определить, насколько хорош предиктор, который оперирует вероятностями вместо классов, немного труднее. Допустим, мы предсказываем, что вероятность дождя завтра 20%, но при этом не можем пережить все возможные исходы. Дождь либо идет, либо нет.
В этом случае помогает то, что предикторы делают не один прогноз, а более 3 000 прогнозов. Таким образом, каждый раз, когда мы предсказываем, что событие произойдет в 20% случаев, мы можем узнать, как часто это событие происходит на самом деле. В следующем фрагменте кода библиотека Pandas помогает мне сравнить прогнозы, сделанные с помощью случайного леса, с фактическими исходами.
Out ⌈8⌉:
Случайный лес предсказал, что 75 клиентов имеют вероятность ухода, равную 0,9, и в реальности эта группа имеет показатель
Калибровка (calibration) и дискриминация (discrimination)
Используя таблицу, представленную выше, мы можем создать несложный график, позволяющий визуализировать вероятности. Ось X представляет вероятность ухода, которую случайный лес присвоил группе клиентов. Ось Y представляет фактический показатель ухода в пределах группы. Каждая точка имеет размер, пропорциональный численности группы.
Вы, наверное, обратили внимание на две прямые, начерченные с помощью функции stat_function().
Красная линия представляет идеальный прогноз для данной группы, т.е. случай, когда предсказанная вероятность ухода клиентов равна фактической частоте данных исходов. Зеленая прямая представляет базовую вероятность ухода. Для этого набора данных она составляет около 0,15.
Смысл калибровки можно выразить следующим образом: «События, предсказанная вероятность которых составляет 60%, должны происходить в 60% случаев». Для всех клиентов, для которых я прогнозирую риск ухода в диапазоне от 30% до 40%, фактический показатель ухода должен составлять около 35%. В графическом выражении это дает возможность оценить, насколько прогнозы близки к красной линии.
Дискриминация дает представление о том, насколько прогнозы далеки от зеленой линии. Почему это важно?
Потому что, если мы присвоим вероятность ухода, равную 15%, каждому клиенту, то получим почти идеальную калибровку за счет средних значений, но у нас не будет реальных идей. Дискриминация дает модели более высокую оценку, если она способна выделить группы, более удаленные от базового множества.
В scikit-learn данные метрики не реализованы, поэтому мне пришлось сделать это самостоятельно. Ради всеобщего блага я не привожу в этой статье математику и код. Уравнения взяты из публикации Yaniv, Yates, Smith «Measures of Discrimination Skill in Probabilistic Judgment» (1991). А код модуля churn_measurements, из которого импортируются функции ниже, вы можете найти на GitHub здесь.
In ⌈10⌉:
Давайте сравним модели на основе этих метрик.
In ⌈11⌉:
В отличие от предыдущих сравнений, в данном случае случайный лес лидирует не так явно. Хотя этот алгоритм способен хорошо отличать случаи с высокой и низкой вероятностью ухода клиентов, у него есть проблемы с определением точной вероятности этих событий. Например, группа, для которой случайный лес спрогнозировал показатель оттока, равный 30%, на самом деле имеет этот показатель на уровне 14%. Очевидно, что здесь еще предстоит проделать определенную работу, но мы оставим ее для вас в качестве задания.
Практическое применение модели на платформе Yhat
Пришло время загрузить модель в облако! Чтобы продемонстрировать продвинутую функциональность, создадим тестовый набор данных из исходных данных при помощи функции test_train_split() библиотеки scikit-learn. Далее адаптируем классификатор на основе метода опорных векторов для данного случая.
In ⌈12⌉:
Модель, которую мы собираемся применить, повторяет код из этой статьи с некоторыми модификациями. Поскольку мы уже определили такие переменные, как yes_no_cols, features и scaler в глобальном пространстве, то можем просто использовать их без необходимости определять их в дальнейшем.
Также мы добавили несколько расчетов. Во-первых, показатель «ценность клиента» (customer worth) (сумма всех платежей, взимаемых с данного клиента). В результате комбинации этой величины с вероятностью ухода клиента получается очень важный показатель: ожидаемая утраченная прибыль в случае ухода данного клиента. Здесь важную роль играет модель, дающая точные прогнозы, поскольку данные значения невозможно получить при помощи одной только классификации.
In ⌈13⌉:
Пакетный режим Yhat
Наступает момент, когда инструменты data science должны перестать быть просто скриптами в облаке и начать решать задачи. В данном случае стоит задача повысить эффективность команды по удержанию клиентов, информируя ее о клиентах с высокой вероятностью ухода.
В компании Yhat наш принцип – это поиск способов сделать data science применимой и практичной, как можно быстрее. Поскольку функция execute() принимает и возвращает тип данных DataFrame, платформа Yhat позволяет нам использовать режим пакетной оценки (batch-scoring mode). Концепция проста. Пользователь загружает csv-файл из любого места, модель выполняется, и пользователь получает на выходе csv-файл с результатами. Это означает, что данный метод оценки клиентов по риску ухода может использовать любой сотрудник моей компании, независимо от того, какими техническими навыками он обладает, насколько хорошо разбирается в машинном обучении и какой язык программирования использует, Python или R.
После входа на cloud.yhathq.com мы выбираем свою модель, и рабочее пространство принимает вид, изображенный на рисунке ниже. Загруженный csv-файл представлял собой обучающий набор данных, созданный в предыдущем разделе. На практике, это будет новый файл, экспортируемый из нашей CRM-системы, или клиентская база данных, представленная в таком же формате, как и набор данных, который мы использовали для обучения модели.

Ждем несколько секунд, когда файл с результатами готов, загружаем его по ссылке в нижней части страницы и открываем в Excel.

Готово. Более 800 клиентов проанализированы и ранжированы в несколько кликов.
Предсказываем отток с помощью нейросети

Проблема предсказания оттока клиентов — одна из самых распространенных в практике Data Science (так теперь называется применение статистики и машинного обучения к бизнес-задачам, уже все знают?). Проблема достаточно универсальна: она актуальна для многих отраслей — телеком, банки, игры, стриминг-сервисы, ритейл и пр. Необходимость ее решения довольно легко обосновать с экономической точки зрения: есть куча статей в бизнес-журналах о том, что привлечь нового клиента в N раз дороже, чем удержать старого. И ее базовая постановка проста для понимания так, что на ее примере часто объясняют основы машинного обучения.
Для нас в Plarium-South, как и для любой игровой компании, эта проблема также актуальна. Мы прошли длинный путь через разные постановки и модели и пришли к достаточно оригинальному, на наш взгляд, решению. Все ли так просто, как кажется, как правильно определить отток и зачем тут нейросеть, расскажем под катом.
Отток? Не, не слышал.
Начнем, как полагается, с определений. Есть база клиентов, которые пользуются какими-то услугами, покупают какие-то товары, в нашем случае — играют в игры. В какой-то момент отдельные клиенты перестают пользоваться сервисом, уходят. Это и есть отток. Предполагается, что в тот момент, когда клиент подает первые признаки ухода, его еще можно переубедить: обнять, рассказать, как он важен, предложить скидку, сделать подарок. Таким образом, первоочередная задача состоит в том, чтобы правильно и своевременно предсказать, что клиент собирается уйти.
Может показаться, что возможных значений целевой переменной тут два: пациент либо жив, либо мертв. И действительно, ищем соревнования по предсказанию оттока (крэкс, пэкс, фэкс) и везде видим задачу бинарной классификации: объекты — пользователи, целевая переменная — бинарная. Здесь ярко видно отличие спортивного анализа данных от практического. В практическом анализе перед тем как решать задачу, приходится ее еще и ставить, да так, чтобы из ее решения можно было извлечь прибыль. Чем и займемся.
Отток оттоку рознь
При более близком рассмотрении мы узнаем, что можно выделить два типа оттока — договорный (contractual) и недоговорный (non-contractual). В первом случае клиент явным образом говорит, что он устал и он уходит. Зачастую это сопровождается формальными действиями по прекращению контракта и т. п. В этом случае, действительно, можно четко определить, когда человек является твоим клиентом, когда нет. В недоговорном случае клиент ничего не говорит, никак не уведомляет и просто перестает пользоваться вашим сервисом, услугой, играть в вашу игру и покупать ваши товары. И, как вы уже догадались, второй случай гораздо более распространен.
То есть вы имеете в CRM / базе данных некую активность пользователей (покупки, заходы на сайт, звонки в сотовой сети), которая в какой-то момент уменьшается. Заметьте, не обязательно прекращается, но существенно изменяет интенсивность.
Всех под одну гребенку
Изобразим дни визитов трех гипотетических клиентов синими крестиками на оси времени. Первая мысль — зафиксировать некий период (тут он называется Target definition). Определенную активность в течение этого периода будем считать проявлением жизни, а отсутствие таковой — уходом. Тогда в качестве входных данных для модели предсказания оттока можно взять данные за период до рассматриваемого (Input data).
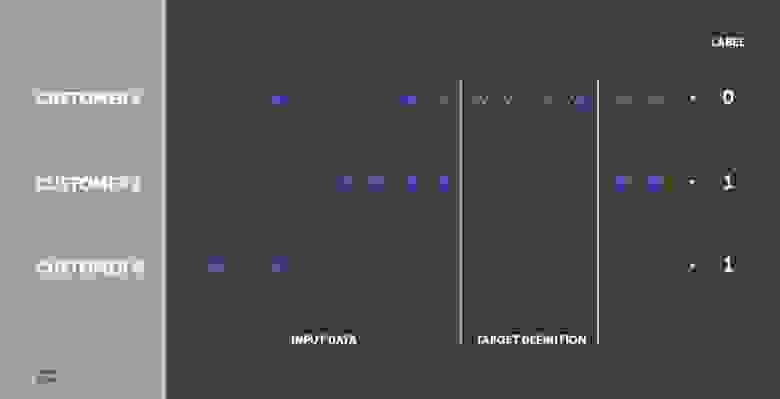
Можно также предусмотрительно оставить между двумя этими периодами некий буфер, например 1–2 недели, с целью научиться предсказывать отток заранее, чтобы успеть совершить некие действия по вразумлению удержанию клиента.
Что плохого в таком подходе? Непонятно, как правильно задать параметры. Какой период взять для определения целевой переменной. Для одного клиента трехдневное отсутствие — это безусловный уход, для другого — стандартное поведение. Вы скажете: “Давайте возьмем большой промежуток — месяц, год, два, тогда точно все попадут”. Тут может возникнуть проблема с историческими данными, т. к. не у всех они хранятся так долго. Кроме того, если мы будем строить модель на данных годичной давности, она может не подходить для текущей ситуации. И, к тому же, чтобы проверить результат работы нашей модели на актуальных данных, придется ждать год. Можно ли не уходить глубоко в историю, а еще лучше вообще обойтись без уравниловки?
Вероятность 50/50 — либо ушел, либо нет
Если мы знаем историю заходов пользователя: как он в среднем себя вел до этого и как давно отсутствует сейчас, — нельзя ли подобрать правильные статистические распределения и посчитать вероятность того, что пользователь жив в данный момент? Можно, и уже было сделано в модели Pareto/NBD еще в 1987 году, где время до ухода описывалось распределением Парето (смесь экспонент с гамма-весами), а распределение визитов/покупок — отрицательным биномиальным. В 2003 возникла идея вместо распределения Парето использовать бета-геометрическое и появилась модель BG/NBD, которая работает быстрее и зачастую без потери качества. Обе модели достойны внимания, и есть хорошие реализации обеих на Python и R. На вход эти модели принимают только три значения по каждому пользователю: количество визитов/покупок, возраст клиента (время, прошедшее с первой покупки до текущего момента) и время, прошедшее с последней покупки. При таком бедном наборе входных данных модели работают очень достойно, что говорит о том, что рановато пока забывать теорвер, его вполне еще можно применять — в промежутках между тем, как «стакать xgboost-ы».
При этом потенциал для улучшений еще есть. Например, есть сезонность, промоакции, влияющие на статистику заходов, — их эти модели не учитывают. Есть другие данные об активности пользователя, которые могут говорить о близости ухода. Так, в конец разочаровавшийся в игре пользователь может попусту растратить ресурсы (не пропадать же добру), распустить войско. Данные о таком поведении могут помочь отличить реальный уход от временного отсутствия (отпуск в джунглях без интернета). Все эти данные нельзя “скормить” вероятностным моделям, описанным выше (хотя есть уважаемые люди, которые пытаются это сделать).
Вызываю нейросеть
А что если взять и построить нейросеть, на выходе которой будут параметры распределений? Про это есть магистерская диссертация выпускника Гетеборгского университета и написанный в рамках нее и прекрасно проиллюстрированный пакет на Python — WTTE-RNN.
Автор решил предсказывать время до следующего захода (time to event) с помощью распределения Вейбулла и всей мощи рекуррентных нейросетей. Кроме теоретической красоты подхода здесь есть еще и важный практический момент: при использовании рекуррентных нейросетей не нужно городить огород с построением признаков из временных рядов (агрегировать набор рядов набором функций по набору периодов и набору лагов), чтобы представить данные в виде плоской таблицы (объекты — признаки). Можно подать временные ряды на вход сети как есть. Подробнее об этом мы недавно рассказывали в ходе доклада на PiterPy. Это серьезно экономит вычислительные и временные ресурсы. Кроме рядов одного типа (например, по дням), можно также подать на вход и ряды другого типа или длины (например, почасовые за последний день), и статические характеристики пользователей (пол, страна), хоть картинку с его портретом (вдруг лысые уходят чаще?), нейросети и такое умеют.
Однако оказалось, что построенная по Вейбуллу функция потерь при обучении часто уходит в NaN. Кроме того, временем до следующего захода не так просто оперировать. Знание его не избавляет от необходимости отвечать на вопросы, какое время до захода считать слишком большим, как рассчитать пороги для каждого пользователя в отдельности и учитывая всяческую сезонность, как отсеять временные перерывы в активности и т. д.
Что же делать?
Не претендуя на однозначную правильность принятого решения, расскажем, какой путь в итоге выбрали мы в Plarium-South. Мы вернулись к бинарному таргету, рассчитали его хитрым образом, а в качестве модели взяли RNN.
Почему к бинарному?
Практическое руководство: предсказать отток клиентов
Дата публикации Jan 15, 2019

Прежде чем мы начнем, давайте кратко напомним, что такое отток на самом деле: «Отток» определяет количество клиентов, которые отписались или аннулировали свой контракт на обслуживание. Клиенты, отворачивающиеся от ваших услуг или продуктов, не приносят удовольствия любому бизнесу. Очень дорого отыграть их, когда они проиграли, даже не думая, что они не сделают все от них зависящее, если не будут удовлетворены.Узнайте все об основах оттока клиентов в одной из моих предыдущих статей, Теперь давайте начнем!
Как мы прогнозируем отток клиентов?

Инструменты, которые мы используем

Чтобы предсказать, изменится ли клиент или нет, мы работаем с Python и его удивительными библиотеками с открытым исходным кодом. Прежде всего мы используем Jupyter Notebook, приложение с открытым исходным кодом для живого программирования, которое позволяет нам рассказать историю с помощью кода. Кроме того, мы импортируемПанды, который помещает наши данные в простую в использовании структуру для анализа данных и преобразования данных. Чтобы сделать исследование данных более понятным, мы используемplotlyвизуализировать некоторые из наших идей. Наконец сscikit учитьсямы разделим наш набор данных и обучим нашу прогнозную модель.
Набор данных
Одним из наиболее ценных активов компании являются данные. Поскольку данные редко публикуются, мы берем доступный набор данных, который вы можете найти наIBMsвеб-сайт, а также на других страницах, таких какKaggle: Набор данных клиентов Telcom. Набор необработанных данных содержит более 7000 записей. Все записи имеют несколько функций и, конечно, столбец с указанием, изменился ли клиент.
Чтобы лучше понять данные, мы сначала загрузим их в панды и исследуем их с помощью некоторых очень простых команд.
Исследование и выбор функций
Этот раздел довольно короткий, так как вы можете узнать больше об общих исследованиях данных в лучших руководствах. Тем не менее, чтобы получить первоначальное представление и узнать, какую историю вы можете рассказать с помощью данных, исследование данных имеет определенный смысл. Используя функции python data.head (5) и «data.shape», мы получаем общий обзор набора данных.

Подробно мы рассмотрим целевую особенность, фактический «отток». Поэтому мы строим его соответственно и видим, что 26,5% от общего объема оттока клиентов Это важно знать, поэтому в наших данных об обучении мы имеем одинаковую долю клиентов с постоянным числом клиентов и клиентов с нулевым уровнем

Подготовка данных и разработка функций
Помните, что чем лучше мы подготовим наши данные для модели машинного обучения, тем лучше будет наш прогноз. У нас может быть самый продвинутый алгоритм, но если наши тренировочные данные отстой, наш результат тоже будет отстой. По этой причине ученые-данные тратят так много времени на подготовку данных. А так как предварительная обработка данных занимает много времени, но здесь это не главное, мы проведем несколько примерных преобразований.
3. Преобразование числовых признаков из объекта
Из нашего исследования данных (в данном случае «data.dtypes ()») мы видим, что столбцы MonthlyCharges и TotalCharges являются числами, но на самом деле в формате объекта. Почему это плохо? Наша модель машинного обучения может работать только с фактическими числовыми данными. Поэтому с помощью функции «to_numeric» мы можем изменить формат и подготовить данные для нашей модели машинного обучения.

Кроме того, мы могли бы использовать функцию «get_dummies ()» для всех категориальных переменных в наборе данных. Это мощная функция, но может быть неприятно иметь так много дополнительных столбцов.
Логистическая регрессия и тестирование моделей
Логистическая регрессия является одним из наиболее часто используемых алгоритмов машинного обучения, и в основном используется, когда зависимая переменная (здесь отток 1 или отток 0) является категориальной. Независимые переменные, напротив, могут быть категориальными или числовыми. Обратите внимание, что, конечно, имеет смысл детально понять теорию, лежащую в основе модели, но в этом случае наша цель состоит в том, чтобы использовать прогнозы, которые мы не пройдем через эту статью.
Шаг 1. Давайте импортируем модель, которую мы хотим использовать из sci-kit learn
Шаг 2. Делаем экземпляр модели
Шаг 3. Проводится ли обучение модели на основе набора обучающих данных и сохраняется ли информация, извлеченная из данных?
С обученной моделью мы можем теперь предсказать, изменился ли клиент для нашего тестового набора данных. Результаты сохраняются в «gnition_test », а затем измеряется и распечатывается оценка точности.

Результаты показывают, что в 80% случаев наша модель предсказывала правильный результат для нашей проблемы бинарной классификации. Это считается очень хорошим для первого запуска, особенно когда мы смотрим, какое влияние оказывает каждая переменная и имеет ли это смысл. Таким образом, с конечной целью сократить отток и своевременно предпринять правильные предупреждающие действия, мы хотим знать, какие независимые переменные больше всего влияют на наш прогнозируемый результат. Поэтому мы устанавливаем коэффициенты в нашей модели на ноль и смотрим вес каждой переменной.

Можно заметить, что некоторые переменные имеют положительное отношение к нашей предсказанной переменной, а некоторые имеют отрицательное отношение. Положительное значение оказывает положительное влияние на нашу прогнозируемую переменную. Хорошим примером является «Контракт-месяц-месяц»: положительное отношение к оттоку означает, что наличие такого типа контракта также увеличивает вероятность оттока клиента. С другой стороны, «Контракт_Два года» находится в крайне негативном отношении к прогнозируемой переменной, а это означает, что клиенты с таким типом контракта вряд ли будут набирать деньги. Но мы также видим, что некоторые переменные не имеют смысла в первом пункте. «Fiber_Optic» находится на верхней позиции с точки зрения положительного влияния на отток. Хотя мы ожидаем, что это заставит клиента остаться, поскольку он предоставляет ему быстрый интернет, наша модель говорит о другом. Здесь важно копать глубже и получить некоторый контекст для данных.
Посмотрите на их профиль, определите характеристики и проанализируйте прошлые взаимодействия с вашим продуктом, а затем просто поговорите с ними. Попросите обратную связь, расскажите о последних разработках, которые могут быть интересны, или ознакомьте их с новыми функциями продукта. Подходите к клиентам, которые, скорее всего, произойдут, но убедитесь, что вы предлагаете подходящие вещи, которые могут соответствовать их индивидуальным потребностям. Это создаст ощущение понимания и привязывает их к вам и вашему бизнесу.



