Как узнать историю сайта и восстановить его из веб-архива

Поделиться этим постом

История сайтов полезна вебмастерам при покупке доменов, чтобы вычислить возраст, узнать важные показатели и отделить хорошие от плохих. Ведь фильтры и баны в прошлом напрямую влияют на продвижение сайта в будущем. Поэтому стоит покупать новые домены либо домены с положительной историей.
1. Зачем нужна история сайта
Хронография домена зачастую выдаёт информацию о нём с момента создания. Виртуальные архивы сайтов также дают возможность узнать:
При помощи архивных данных, которые хранятся в интернет-архивах, можно восстановить информацию, которая была утеряна, и посмотреть, как сайт выглядел раньше. Например, если при обновлении баз данных либо смене шаблона сайт перестал работать, можно восстановить сайт из веб-архива по дате и скопировать оттуда старые тексты.
Бывает и так: анализ трафика показал, что при прошлом дизайне сайт приносил больше прибыли. Сравнение текущей и прошлой версий одного ресурса позволяет сделать соответствующие выводы и улучшить работу.
В отличие от старых доменов, новые всегда обладают чистой историей, ведь у них не было владельцев, и они не были зарегистрированы как сайты. Такие домены покупают, не боясь столкнуться с фильтрами и другими проблемами. Однако многие вебмастера предпочитают покупать готовые сайты с рук или на аукционах. Причина здесь одна: старый домен с хорошей историей легче продвинуть в поиске, чем начинать оптимизацию с чистого листа.
При покупке старого сайта нужно тщательно проверять его прошлое. Важно, чтобы на сайте не было ворованного контента, запрещённых тематик и банов по причине любых нарушений.
Чтобы убедиться, что вы покупаете не кота в мешке, вы можете пройтись по нашему чеклисту «Как проверить сайт перед покупкой».
2. Принципы работы веб-архивов
Веб-архивы время от времени посещают открытые к доступу сайты. При одном таком посещении автоматически создаются точные копии страниц, которые сохраняются на » target=»_blank»>сервере архива. Под каждой копией отмечается дата. Дальше любой пользователь может восстановить нужную версию сайта через календарь.
2.1. Инструменты для проверки истории сайта, и как ими пользоваться
2.1.1. Webarchive
Самый крупный ресурс, на котором хранится история большинства сайтов, — Webarchive. Иногда этот сервис называют машиной времени сайтов или Wayback Machine. Здесь можно посмотреть даже историю тех ресурсов, которые давно прекратили существование.

Чтобы проверить состояние домена, нужно ввести его в строку поиска и нажать Enter. Сервис выдаст информацию о сайте с момента его первой регистрации. В нижней части страницы отображается календарь с кликабельными датами. После нажатия на число архив покажет версию сайта, которая была актуальна в тот день.
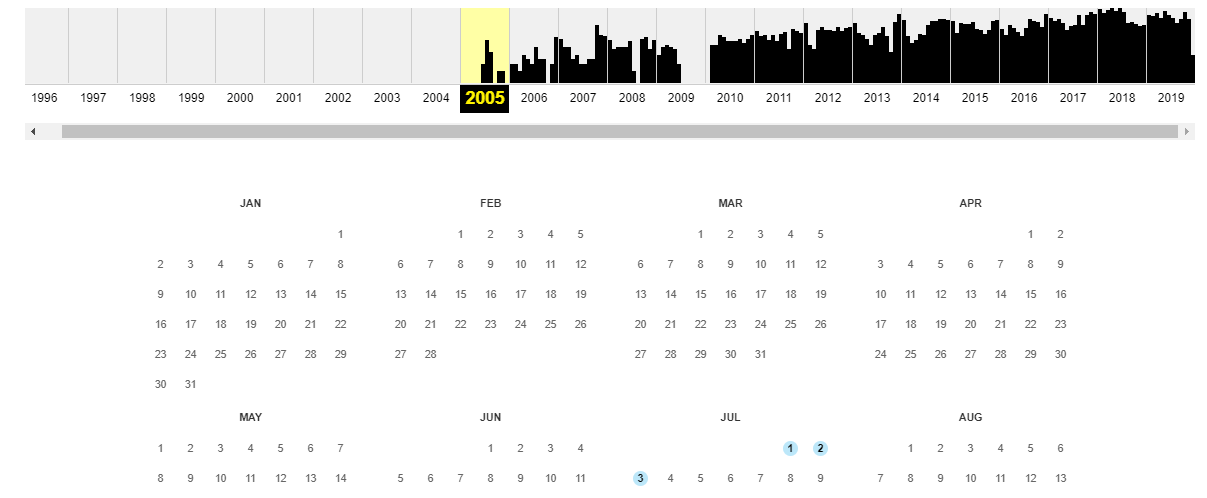
Синим цветом отмечены даты сохранения копий страниц сайта, зелёным — версии с редиректами. С помощью стрелок вверху можно проследить историю изменения сайта по хронологии.

Бывает, что история сайта недоступна. Этому есть несколько причин:
Чтобы запретить архивацию сайта, можно прописать в robots.txt директиву на запрет сохранения копий:
После этого никто не сумеет восстановить страницы вашего сайта в будущем. Но и вы сами не сможете сделать это, если потребуется.
Если в Webarchive нет интересующего вас сайта, вы можете сами добавить его в сервис, сохранив актуальную копию любой страницы сайта. Для этого нужно ввести её текущий адрес и нажать «Save page».
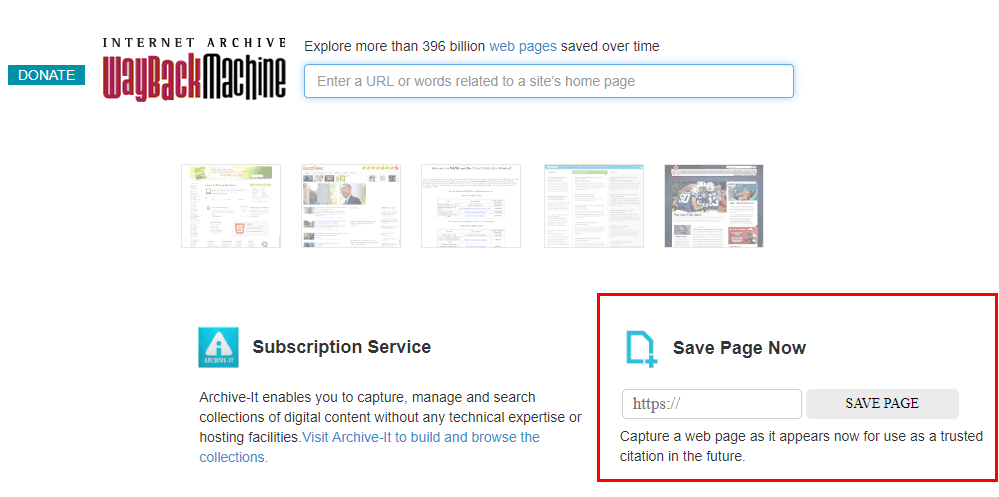
Этот сервис также может быть полезен, когда необходимо восстановить неработающий сайт через инструмент RoboTools c большой базой уникальных текстов. Например, домен выставлен на продажу, а в его истории сохранены страницы с хорошими текстами. Так как сайта уже не существует — его страницы не индексируются. Поэтому старые тексты можно использовать для наполнения нового проекта.
2.1.2. Whois
Еще один инструмент для проверки доменных имён — Whois. С его помощью можно узнать:
Для этого нужно ввести URL в строку поиска.
После анализа сайта при нажатии на стрелку в разделе «Dates» открывается более подробная информация о домене.

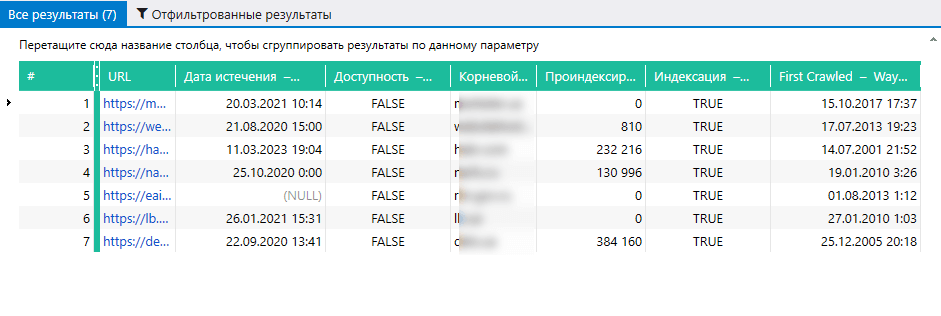
Тянуть данные из сервисов и делать массовую проверку URL вы можете даже в бесплатной версии Netpeak Checker без ограничений по времени и количеству URL, в которой также доступно много других базовых функций.
Чтобы начать пользоваться бесплатным Netpeak Checker, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
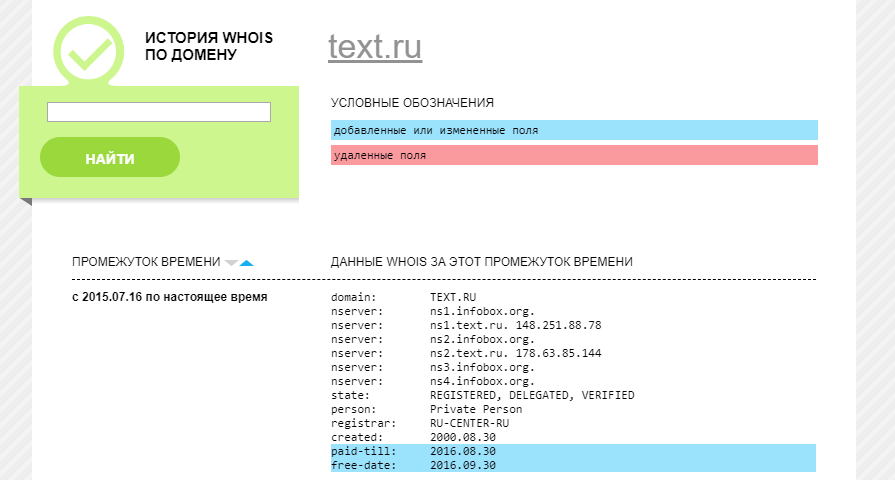
2.1.3. Whoishistory
Узнать историю домена также можно на сайте Whoishistory.
3. Как восстановить сайт из веб-архива
Для восстановления сайта из веб-архива используется сервис Аrchivarix.
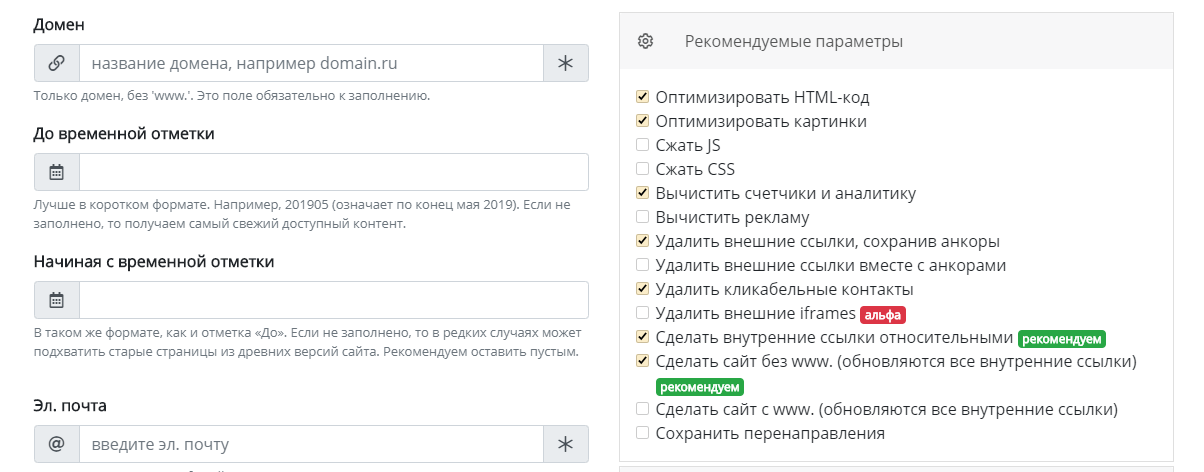
После введения информации появляется уведомление с подтверждением. Здесь же виден скриншот сайта и данные о нём. Параллельно на почту приходит письмо с архивными данными для восстановления. Остаётся загрузить эти файлы на » target=»_blank»>сервер и проверить работоспособность сайта.
Подводим итоги
Посмотреть историю сайта можно при помощи веб-архивов — сервисов, которые создают копии страниц в разные периоды времени. Даже если сайт прекращает существование, информация о его предыдущих версиях может оставаться в открытом доступе.
Самым популярным сайтом для просмотра и восстановления истории считается Wayback Machine. В нём хранятся все данные о домене с момента его создания. Если нажать на определенную дату в календаре, можно посмотреть, как выглядел сайт в тот день.
Дополнительно вы можете сохранить текущую версию сайта, восстановить неработающий домен и проверить, был ли он когда-то использован. Также узнать информацию о сайте можно при помощи сервисов Whois, Whoishistory и аналогов.
А вы пользуетесь этими сервисами? Для каких задач? Поделитесь в комментариях 😊
Как посмотреть на сайт в прошлом: инструмент + способ восстановления

Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – a rchive.org. Для этого нужно выполнить следующее:
После этого откроется главная страница в том виде, какой она была в выбранный период.
Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.
Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.
На тот момент выглядел Яндекс вот так:
Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:
YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видео» target=»_blank»>сервер, » target=»_blank»>хостингом:
Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:
ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.
Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.
Как выглядел раньше любой сайт? Путешествуем в прошлое с WebArchive
У 9 из 10 наших читателей есть свой сайт или интернет-магазин на 1C-UMI. Кто-то создал его недавно, а кому-то уже можно праздновать юбилей. За годы развития веб-ресурсы претерпевают множество изменений во внешнем виде и функционале. Иногда хочется вспомнить, каким же был ваш проект раньше, когда всё только начиналось. Или поднять какую-то утерянную информацию, которая была на сайте ранее. Сделать это легко при помощи чудо-сервиса Wayback Machine.
Как пользоваться веб-архивом
Откройте сервис, вбейте в строку поиска домен или полный адрес своего сайта. Сервис автоматически начнет поиск и через пару секунд покажет вам результаты в виде временной шкалы и календаря с датами, когда были сделаны снимки ресурса.
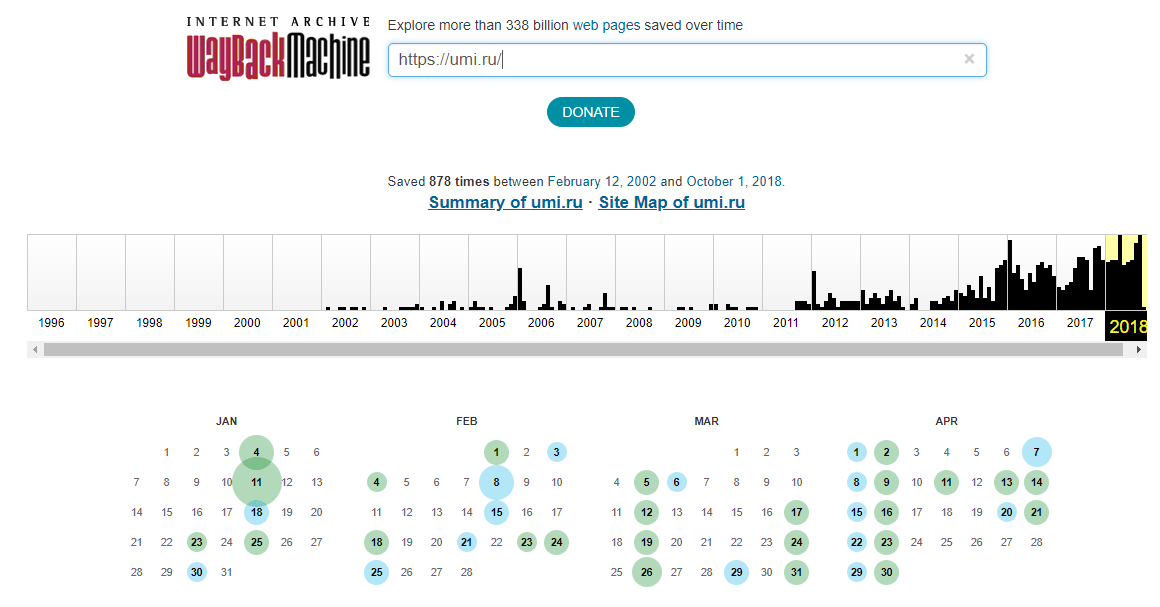
Чтобы перейти к конкретному году, кликните по соответствующему блоку на шкале. Затем в календаре ниже нажмите на одну из дат, выделенных голубым цветом. Если в тот день было сделано несколько снимков, при нажатии на дату вы увидите окно для выбора нужного вам времени. Если снимок был один, вы сразу попадете на сохраненную версию.
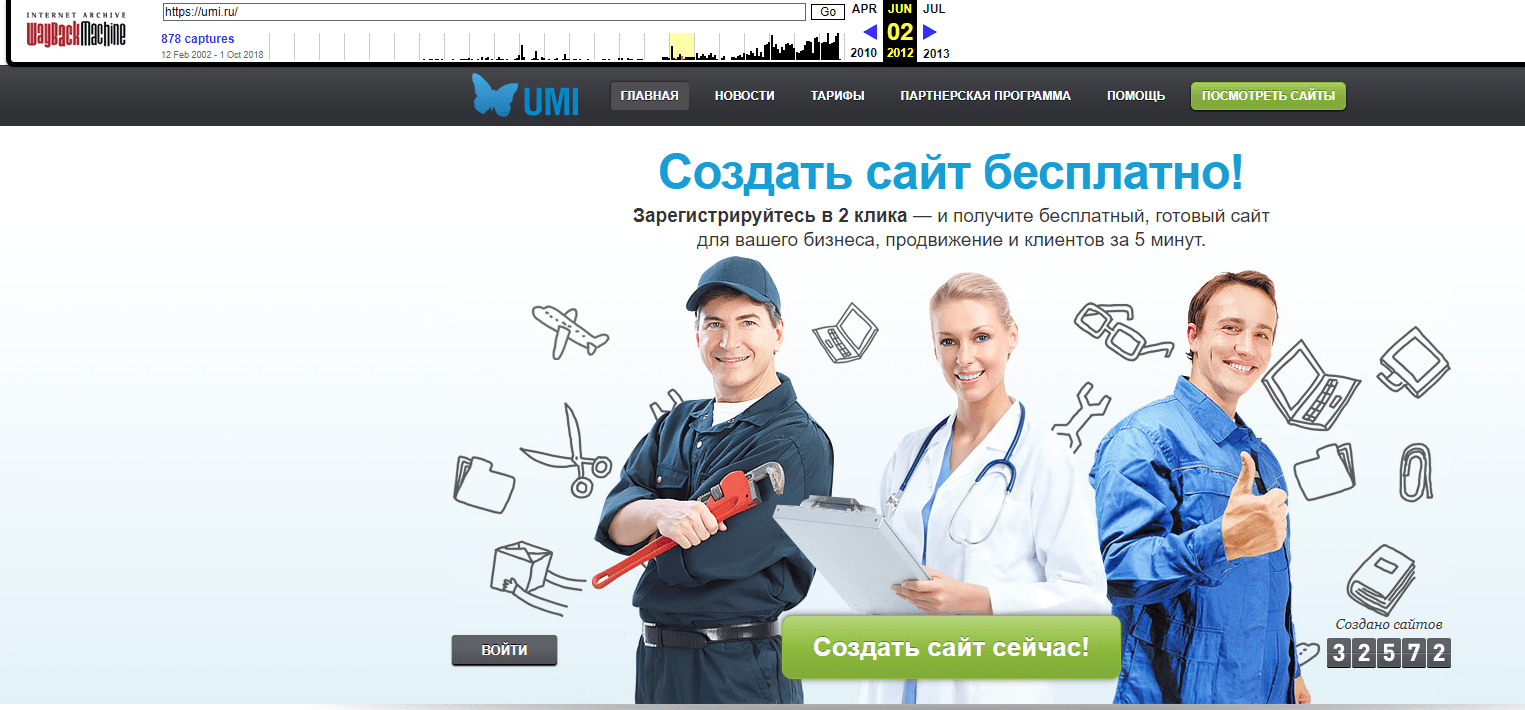
Вот так выглядел наш сайт 1C-UMI летом 2012 года:
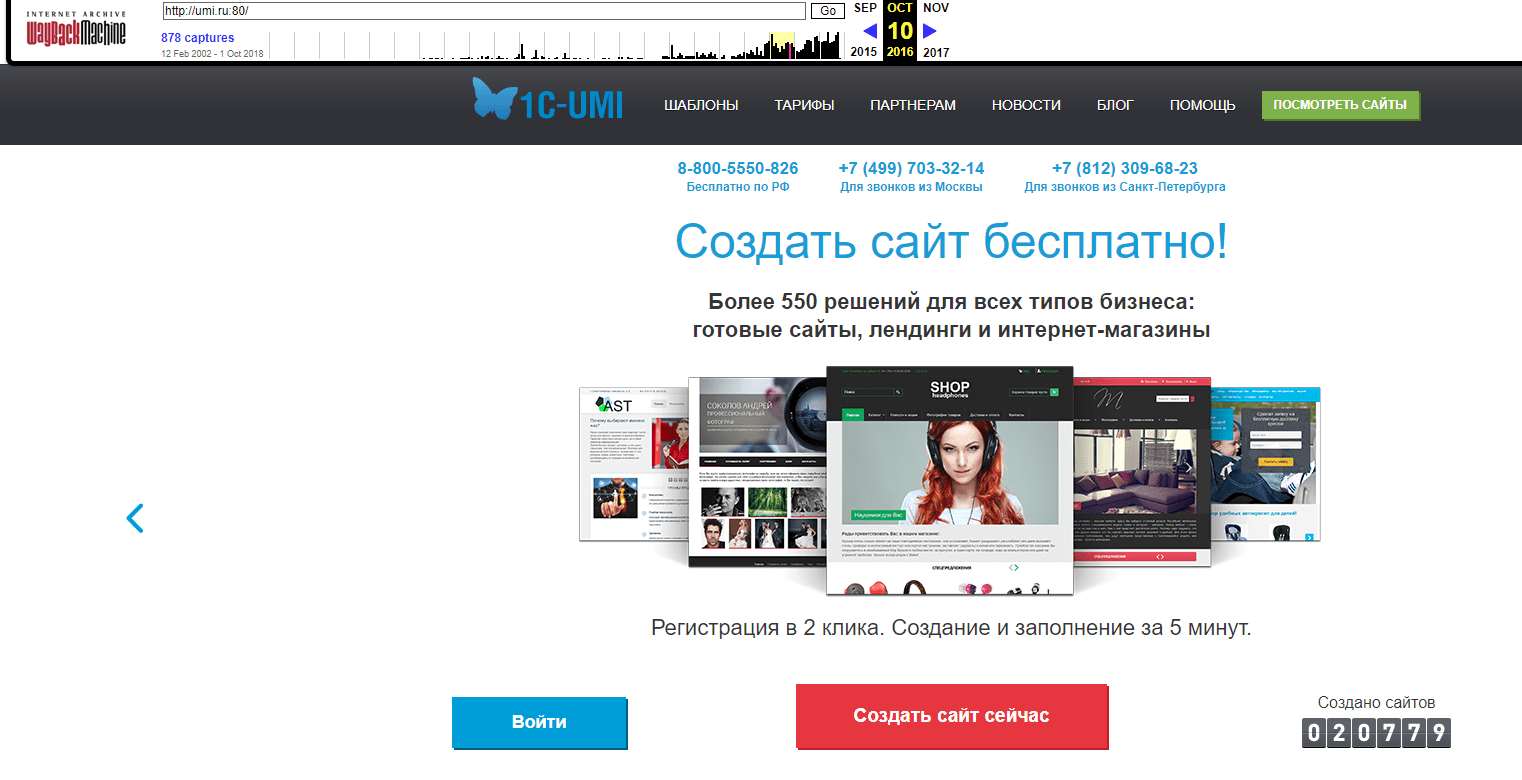
А вот так его видели наши пользователи осенью 2016 года:
Чем дольше ресурс работает, тем больше его снимков будет в WebArhive. Для путешествия в прошлое используйте временную шкалу и блок переключения месяцев и чисел справа от нее.
Самое классное — что данный сервис не делает скриншоты сайтов, а сохраняет их целиком. Таким образом, вы увидите версию 10-летней давности и, все разделы, формы, почитаете тексты, полистаете изображения и многое другое.
Какие сайты попадают в веб-архив
Оказаться в Wayback Machine может любой сайт. Особенно это касается тех веб-ресурсов, которые находятся в каталоге DMOZ. Но так как сейчас туда свое «детище» уже не добавить, будет достаточно того, что на вашу площадку ссылаются сайты, снимки которых уже присутствуют в веб-архиве. А даже если таких ссылок нет, ваш ресурс все равно может попасть в базу сервиса. Главное, чтобы в его файле Robots.txt не было запрета.
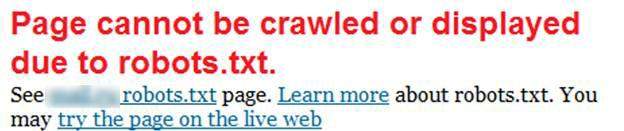
Как проверить? Для сайтов на 1С-UMI откройте раздел «Реклама/SEO → Управление robots.txt» в панели управления сайтом и проверьте, нет ли в нем следующей записи:
Если такой записи (как выше) нет, все хорошо, ваш сайт имеет шанс на попадание в веб-архив. В противном случае, при поиске своего ресурса в сервисе вы увидите надпись, как на скриншоте ниже.
Если вы не хотите ждать, когда сервис соблаговолит сделать снимок вашего сайта, добавьте его в базу WebArchive вручную. Для этого найдите функцию «Save Page Now», которая находится в центральной части страницы справа.
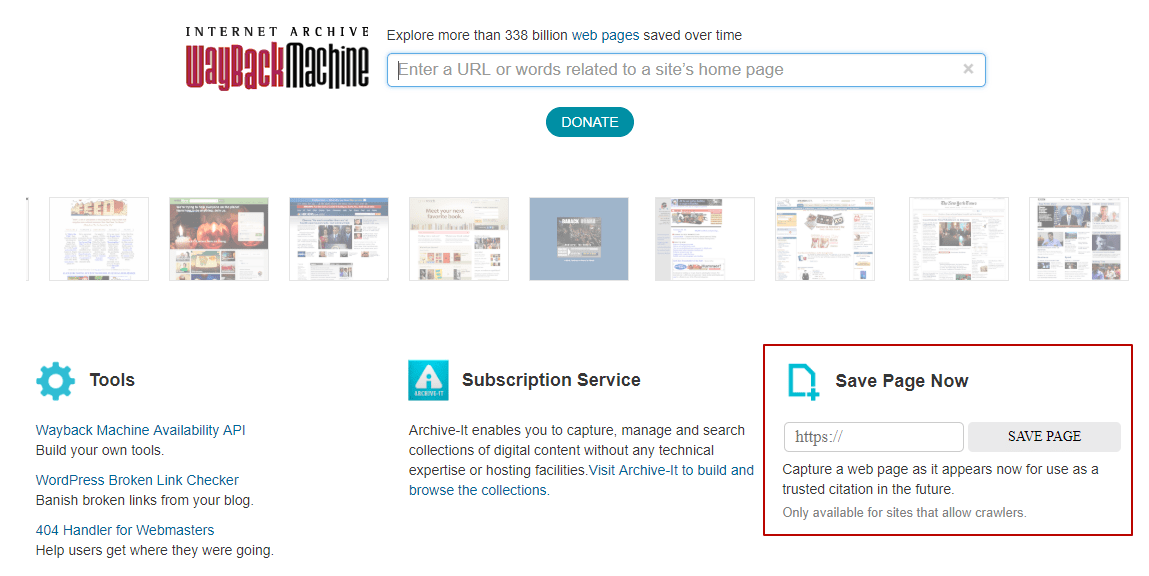
Укажите ссылку на свой ресурс и нажмите на кнопку «SAVE PAGE». Сохранение начнется через несколько секунд и, спустя минуту или около того, будет закончено. За ходом выполнения вы можете наблюдать в небольшом окошке по центру экрана.
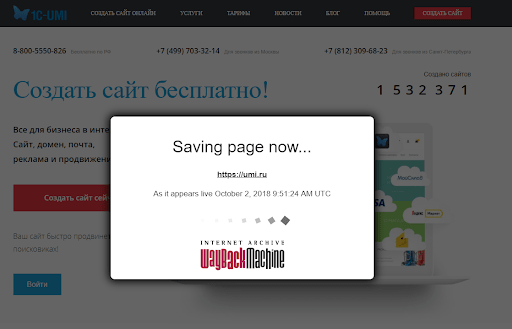
После сохранения снимка страницы начнет загружаться только что архивированная версия сайта.

По окончании процесса окно загрузки закроется, и вы сможете просмотреть сохраненный снимок, побродить по всем разделам сайта и т. д.
Чем будет полезен веб-архив для вас
Данный сервис годится не только для того, чтобы смотреть, в каком состоянии была ваша страничка или любой другой ресурс некоторое время назад. С его помощью вы можете восстановить свой сайт, его страницу, какой-то текст или элемент, если вдруг по какой-то причине данные были стерты. Чтобы этого не произошло, не забывайте почаще выполнять резервное копирование вашего сайта, ну, а на экстренный случай имейте в виду WebArchive. Но имейте в виду также, что WebArchive делает снимки по своему усмотрению с непредсказуемой частотой, поэтому нужной вам версии сайта в нем может и не оказаться.
Вручную восстанавливать ресурс из веб-архива очень долго и для этого нужно неплохо разбираться в сайтостроении и верстке. Однако при желании восстановление можно автоматизировать при помощи онлайн-инструмента ARCHIVARIX.
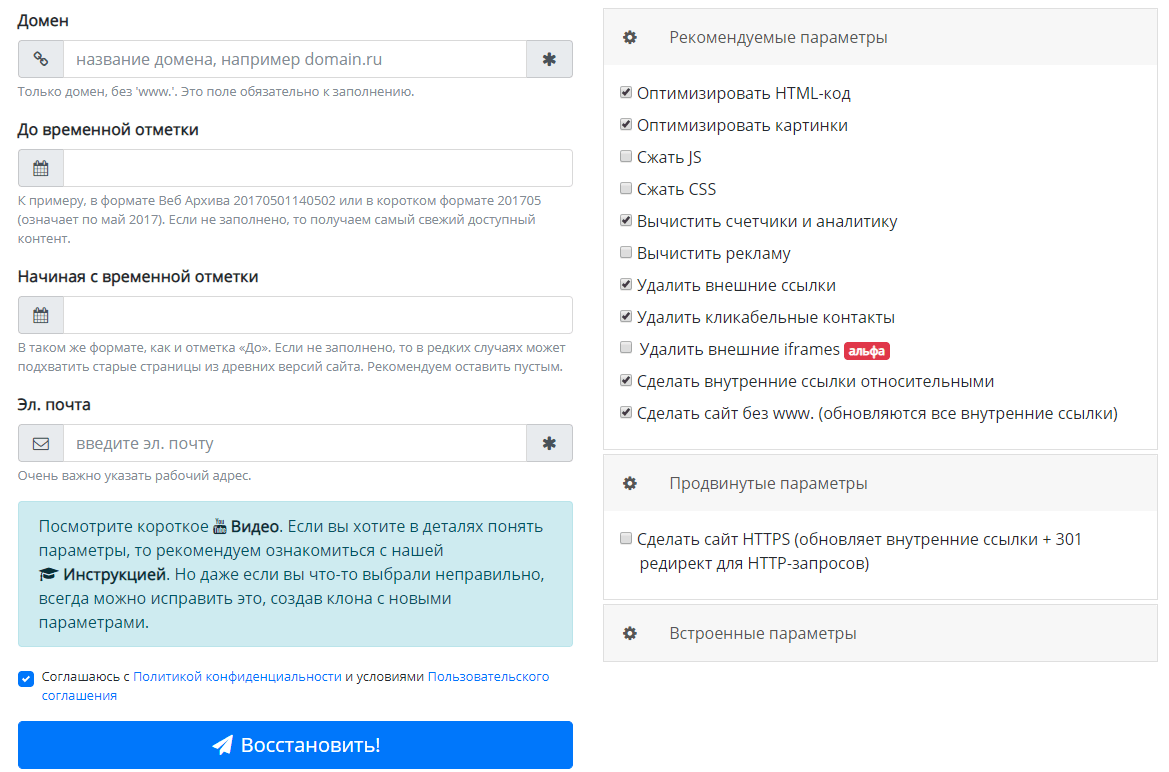
До 200 файлов сервис восстанавливает бесплатно, а при большем количестве взимает небольшую плату.
Веб-архив может быть вам полезен и тем, что он содержит колоссальное количество уникальных текстов, которые опубликованы на канувших в небытие ресурсах. Как это можно использовать с выгодой для своего бизнеса? Допустим, вы запускаете сайт. Сами писать тексты не можете из-за отсутствия времени, а на оплату услуг копирайтера денег нет. Чтобы не откладывать запуск проекта, попробуйте найти уникальный контент в Wayback Machine.
Найдите любой сайт, близкий вашему по тематике, откройте его содержимое, скопируйте тексты и прогоните их через софт или сервис проверки на плагиат. Статьи, которые окажутся уникальными (от 90% и выше), вы можете без зазрения совести опубликовать на своем сайте. Это не будет считаться хищением, так как тексты после удаления ресурсов стали ничейными.
Для поиска таких сайтов можно использовать базы » target=»_blank»>сервер, » target=»_blank»>хостинговых компаний. Обычно они публикуют список тех доменов, срок действия которых истек или вот-вот истечет. Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Несколько фактов о веб-архиве
Первый запуск сервиса WebArchive состоялся в 1996 году. С тех пор этот инструмент сумел накопить в своей базе более 338 миллиардов сайтов. Представьте, сколько это! А дисковое пространство, которое занято информацией в архиве, составляет 1015 Терабайт. Если перевести на математический язык, то это квадриллион.

На следующий год после основания сервиса WebArchive добавил в свою базу сам себя. Хотите посмотреть, как он выглядел на тот момент? Тогда взгляните на изображение ниже.
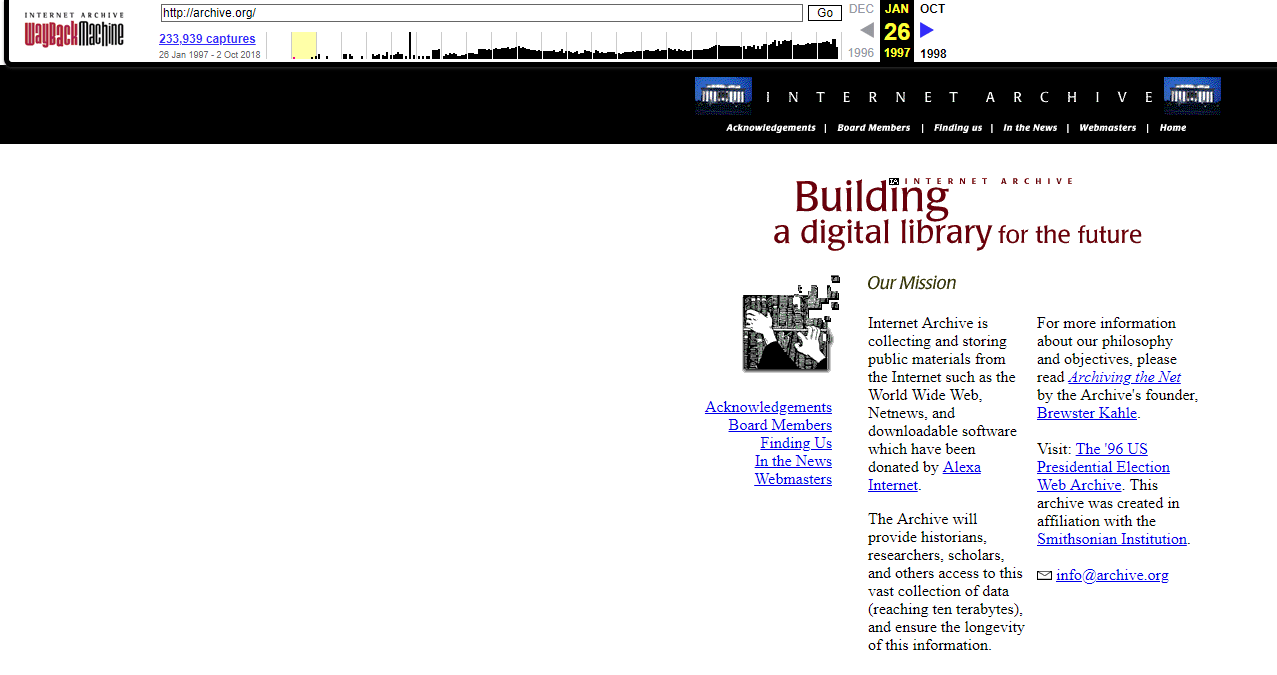
Это самый первый его снимок от 26 января 1997 года.
На данный момент веб-архив считается наилучшим способом из бесплатных для создания снимков интернет-ресурсов. Возьмите его на вооружение.
Справочная: “Архив Интернета” — история создания, миссия и дочерние проекты

Вероятно, на Хабре не так много пользователей, кто никогда не слышал об «Архиве Интернета» (Internet Archive), сервисе, который занимается поиском и сохранением важных для всего человечества цифровых данных, будь то интернет-странички, книги, видео или информация иного типа.
Кто управляет Интернет-архивом, когда он появился и какова его миссия? Об этом читайте в сегодняшней «Справочной».
Зачем вообще нужен «Архив»?
Это далеко не только развлечение. Миссия организации — всеобщий доступ ко всей информации. «Интернет-архив» стремится бороться с монополией на предоставление информации со стороны как телекоммуникационных компаний (Google, Facebook и т.п.), так и государств.
При этом «Архив» является законопослушной организацией. Если по закону США какую-то информацию необходимо удалить, организация это делает.
«Архив Интернета» также служит инструментом работы ученых, спецслужб, историков (например, археографов) и представителей многих других сфер, не говоря уже об отдельных пользователях.
Когда появился «Интернет-архив»?
Создатель «Архива» — американец Брюстер Кейл, который создал компанию Alexa Internet. Оба его сервиса стали чрезвычайно популярными, оба они процветают и сейчас.
«Интернет-архив» начал архивировать информацию с сайтов и хранить копии веб-страниц, начиная с 1996 года. Штаб-квартира этой некоммерческой организации располагается в Сан-Франциско, США.
Правда, в течение пяти лет данные были недоступны для общего доступа — данные хранились на » target=»_blank»>серверах «Архива», и это все, просмотреть старые копии сайтов могла лишь администрация сервиса. С 2001 года администрация сервиса решила предоставить доступ к сохраненным данным всем желающим.
В самом начале «Интернет-архив» был лишь веб-архивом, но затем организация начала сохранять книги, аудио, движущиеся изображения, ПО. Сейчас «Интернет-архив» выступает хранилищем для фотографий и других изображений НАСА, текстов Open Library и т.п.
На что существует организация?
Как работает «Архив»?
Большинство сотрудников заняты в центрах по сканированию книг, выполняя рутинную, но достаточно трудоемкую работу. У организации три дата-центра, расположенных в Калифорнии, США. Один — в Сан-Франциско, второй — Редвуд Сити, третий — Ричмонде. Для того, чтобы избежать опасности потери данных в случае природной катастрофы или других катаклизмов, у «Архива» есть запасные мощности в Египте и Амстердаме.
«Миллионы людей потратили массу времени и усилий, чтобы разделить с другими то, что мы знаем в виде интернета. Мы хотим создать библиотеку для этой новой платформы для публикаций», — заявил основатель Архива интернета Брюстер Кале (Brewster Kahle)
Насколько велик сейчас “Архив”?
У «Интернет-архива» есть несколько подразделений, и у того, которое занимается сбором информации с сайтов, есть собственное название — Wayback Machine. На момент написания «Справочной» в архиве хранилось 339 миллиардов сохраненных веб-страниц. В 2017 году в «Архиве» хранилось 30 петабайт информации, это примерно 300 млрд веб-страниц, 12 млн книг, 4 млн аудиозаписей, 3,3 млн видеороликов, 1,5 млн фотографий и 170 тыс. различных дистрибутивов ПО. Всего за год сервис заметно «прибавил в весе», теперь «Архив» хранит 339 млрд веб-страниц, 19 млн книг, 4,5 млн видеофайлов, 4,7 млн аудиофайлов, 3,2 млн изображений разного рода, 381 тыс. дистрибутивов ПО.
Как организовано хранение данных?
Информация хранится на жестких дисках в так называемых «дата-нодах». Это » target=»_blank»>серверы, каждый из которых содержит 36 жестких дисков (плюс два диска с операционными системами). Дата-ноды группируются в массивы по 10 машин и представляют собой кластерное хранилище. В 2016 году «Архив» использовал 8-терабайтными HDD, сейчас ситуация примерно такая же. Получается, что одна нода вмещает около 288 терабайт данных. В целом, еще используются жесткие диски и других размеров: 2, 3 и 4 ТБ.
В 2016 году жестких дисков было около 20 000. Дата-центры «Архива» оснащены климатическими установками для поддержания микроклимата с постоянными характеристиками. Одно кластерное хранилище из 10 нод потребляет около 5 кВт энергии.
Структура Internet Archive представляет собой виртуальную «библиотеку», которая поделена на такие секции, как книги, фильмы, музыка и т.п. Для каждого элемента есть описание, внесенное в каталог — обычно это название, имя автора и дополнительная информация. С технической точки зрения элементы структурированы и находятся в Linux-директориях.
Общий объем данных, хранимых «Архивом» составляет 22 ПБ, при этом сейчас есть место еще для 22 ПБ. «Потому, что мы параноики», — говорят представители сервиса.

Посмотрите на скриншот содержимого директории — там есть файл с названием, оканчивающимся на «_files.xml». Это каталог с информацией обо всех файлах директории.
Что будет с данными, если выйдет из строя один или несколько » target=»_blank»>серверов?
Ничего страшного не произойдет — данные дублируются. Как только в библиотеке «Архива» появляется новый элемент, он тут же реплицируется и размещается на различных жестких дисках на разных » target=»_blank»>серверах. Процесс «зеркалирования» контента помогает справиться с проблемами вроде отключения электричества и сбоях в файловой системе.
Если выходит из строя жесткий диск, его заменяют на новый. Благодаря зеркалируемой и редуплицируемой структуре данных новичок сразу же заполняется данными, которые находились на старом HDD, вышедшем из строя.
У «Архива» есть специализированная система, которая отслеживает состояние HDD. В день приходится заменять 6-7 вышедших из строя накопителей.
Что такое Wayback Machine?
Это лишь один из сервисов «Интернет-архива», который специализируется на сохранении веб-страниц. У сервиса есть собственный «паук», который регулярно обследует все доступные в сети сайты и сохраняет их на специализированных » target=»_blank»>серверах. Чем популярнее веб-сайт, тем чаще робот копирует его содержимое. Если администратор ресурса не желает, чтобы информация сайта копировалась ботом, достаточно прописать запрет в файле robots.txt.
Популярные ресурсы копируются часто — практически ежедневно. Wayback Machine индексирует даже социальные сети, включая Twitter, Facebook
В 2017 году «Архив» запустил обновленный сервис Wayback Machine, пообещав более удобный доступ к сохраненным веб-страницам. Сервис был написан если не с нуля, то здорово переработан. Теперь он поддерживает ряд форматов файлов, которые ранее просто не сохранялись В том же 2017 году организация заявила, что каждую неделю ее » target=»_blank»>сервера сохраняют около 1 млрд веб-страниц.
Так выглядел Twitter в 2007 году
Что еще можно найти в базе «Интернет-архива»?
Книги. Коллекция организации огромна, она включает оцифрованные книги, как распространенные, так и очень редкие издания. Книги сохраняются не только англоязычные, но и на многих других языках. У «Архива» есть специализированные центры по сканированию книг, всего таких центров 33, расположены они в пяти странах по всему миру.
В день сотрудники центров сканируют около 1000 книг. В базе сервиса содержатся миллионы изданий, работа по их оцифровке финансируется как обычными людьми, так и различными организациями, включая библиотеки и фонды.
С 2007 года «Интернет-архив» сохраняет в своей базе общедоступные книги из Google Book Search. После запуска, база книг быстро разрослась — в 2013 году насчитывалось уже более 900 тысяч книг, сохраненных из сервиса Google.
Один из сервисов «Архива» также предоставляет доступ к книгам, которые полностью открыты, таковых насчитывается уже более миллиона. Называется этот сервис Open Library.
Видео. Сервис хранит 4,5 млн роликов. Они разбиты по тематикам и имеют самую разную направленность. На » target=»_blank»>серверах «Архива» хранятся фильмы, документальные фильмы, записи спортивных соревнований, ТВ-шоу и многие другие материалы.
В 2015 году «Архив» дал начало масштабному проекту — оцифровке видеокассет. Сначала речь шла о 40 тысячах кассет из архива Мэрион Стоукс, женщины, которая в течение многих десятилетий записывала на кассеты новости. Затем добавились и другие видеокассеты, которые присылали «Архиву» поклонники идеи оцифровки данных, важных для человечества.
Аудио. Аналогично видео, «Архив» хранит и аудиофайлы, которые также разбиты по тематикам. В прошлом году «Архив» начал реализовывать свой новый проект — расшифровку шеллачных пластинок, старейшего формата аудиозаписей. Звук сохранялся на пластинках из шеллака — природной смолы, которую выделяют самками червецов. Всего в архиве Great 78 Project несколько сотен тысяч пластинок.
Программное обеспечение. Конечно, хранить все созданное человечеством ПО просто невозможно, даже для «Архива». На » target=»_blank»>серверах хранится винтаж — например, программы для Macintosh, ПО под DOS и прочий софт. В 2016 году сотрудники «Архива» выложили 1500+ программ под Windows 3.1, работать можно прямо в браузере. В 2017 Internet Archive выпустил архив софта для первых Macintosh.
Игры. Да, «Архив» предоставляет доступ к огромному количеству игр. В некоторые из них можно поиграть в среде браузерного эмулятора. Игры хранятся самые разные, в том числе, и с портативных аналогово-цифровых приставок. Есть игры под MS-DOS и консольные игры для Atari и ColecoVision.
Впервые архив старых игр организация выложила еще в 2013 году. Речь идет о тайтлах 30–40 летней давности, в которые можно было играть прямо в браузере. Это игры для приставок Atari 2600 (1977 года выпуска), Atari 7800 (1986 г.), ColecoVision (1982 г.), Philips Videopac G7000 (1978 г.) и Astrocade (1983 г.). Самое интересное, что Internet Archive добился того, что играть можно вполне легально. Сейчас коллекция насчитывает уже более 3400 игр и продолжает пополняться.



