Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding=’ISO-8859–1′ ). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.

▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
Данные из начала датафрейма
Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
Сведения о датафрейме
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
Результаты работы команды anime[‘genre’].tolist()
Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
Результаты выполнения команды
▍Получение строк по числовым индексам
Следующая конструкция позволяет выбрать три первых строки датафрейма:
Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values :
Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Таблица, содержащая значения NaN
Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.
Структуры данных в pandas / pd 2
Ядром pandas являются две структуры данных, в которых происходят все операции:
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
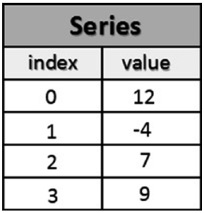
Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
Или же можно выбрать метку, соответствующую положению индекса.
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
Создание Series из массивов NumPy
Фильтрация значений
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
Операции и математические функции
Для операторов можно написать простое арифметическое уравнение.
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Значения NaN
Функции isnull() и notnull() очень полезны для определения индексов без значения.
Series из словарей
Операции с сериями
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
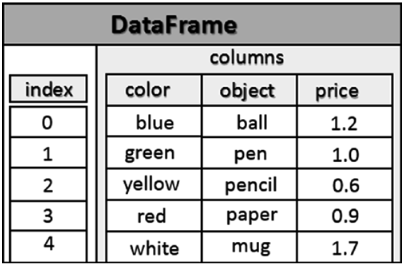
Создание Dataframe
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Выбор элементов
То же можно проделать и для получения списка индексов.
Указав в квадратных скобках название колонки, можно получить значений в ней.
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
Для выбора нескольких строк можно указать массив с их последовательностью.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
Присваивание и замена значений
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
Вхождение значений
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Dataframe из вложенного словаря
В Python часто используется вложенный dict :
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
В отличие от других элементов в структурах данных pandas ( Series и Dataframe ) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
Операции между структурами данных
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Операции между Dataframe и Series
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |



