8 распространенных структур данных на примере JavaScript

Звучит ли это знакомо: «Я начал заниматься веб разработкой после прохождения курсов»?
Возможно, вы хотите улучшить свои знания основ информатики в части структур данных и алгоритмов. Сегодня мы поговорим о некоторых наиболее распространенных структурах данных на примере JS.
1. Стек (вызовов) (Stack)
Стек следует принципу LIFO (Last In First Out — последним вошел, первым вышел). Если вы сложили книги друг на друга, и захотели взять самую нижнюю книгу, то сначала возьмете верхнюю, затем следующую и т.д. Кнопка «Назад» в браузере позволяет перейти (вернуться) на предыдущую страницу.
Стек имеет следующие методы:
2. Очередь (кью) (Queue)
Очередь напоминает стек. Разница состоит в том, что очередь следует принципу FIFO (First In First Out — первым вошел, первым вышел). Когда вы стоите в очереди, первый в ней всегда будет первым.
Очередь имеет следующие методы:
Порядок очередности (приоритет)
Очередь имеет продвинутую версию. Присвойте каждому элементу приоритет, и элементы будут отсортированы соответствующим образом:
3. Связный список (связанный, список узлов и ссылок или указателей) (Linked List)
Буквально, связный список — это цепочечная структура данных, где каждый узел состоит из двух частей: данных узла и указателя на следующий узел. Связный список и условный массив являются линейными структурами данных с сериализованным хранилищем. Отличия состоят в следующем:
| Критерий | Массив | Список |
|---|---|---|
| Выделение памяти | Статическое, происходит последовательно во время компиляции | Динамическое, происходит асинхронно во время запуска (выполнения) |
| Получение элементов | Поиск по индексу, высокая скорость | Поиск по всем узлам очереди, скорость менее высокая |
| Добавление/удаление элементов | В связи с последовательным и статическим распределением памяти скорость ниже | В связи с динамическим распределением памяти скорость выше |
| Структура | Одно или несколько направлений | Однонаправленный, двунаправленный или циклический |
Односвязный список имеет следующие методы:
4. Коллекция (значений) (Set)
Коллекция (множество) — одна из основных концепций математики: набор хорошо определенных и обособленных объектов. ES6 представил коллекцию, которая имеет некоторое сходство с массивом. Тем не менее, коллекция не допускает включения повторяющихся элементов и не содержит индексов.
Стандартная коллекция имеет следующие методы:
5. Хеш-таблица (таблица кэширования) (Hash Table)
Хеш-таблица — это структура данных, которая строится по принципу ключ-значение. Из-за высокой скорости поиска значений по ключам, она используется в таких структурах, как Map, Dictionary и Object. Как показано на рисунке, хеш-таблица имеет hash function, преобразующую ключи в список номеров, которые используются как имена (значения) ключей. Время поиска значения по ключу может достигать O(1). Одинаковые ключи должны возвращать одинаковые значения — в этом суть функции хэширования.
Хеш-таблица имеет следующие методы:
6. Дерево (Tree)
Древовидная структура — это многослойная (многоуровневая) структура. Это также нелинейная структура, в отличие от массива, стека и очереди. Данная структура очень эффективна в части добавления и поиска элементов. Вот некоторые концепции древовидной структуры:
Методами данного дерева являются следующие:
7. Нагруженное (префиксное) дерево (Trie, читается как «try»)
Префиксное дерево — это разновидность поискового дерева. Данные в нем сохраняются последовательно (шаг за шагом) — каждый узел дерева представляет собой один шаг. Префиксное дерево используется в словарях, поскольку существенно ускоряет поиск.
Каждый узел дерева — буква алфавита, следование по ветке приводит к формированию слова. Оно также содержит «булевый индикатор» для определения того, что текущий узел является последней буквой.
Префиксное дерево имеет следующие методы:
8. Граф (график) (Graph)
Граф, также известный как сеть (Network), представляет собой коллекцию связанных между собой узлов. Бывает два вида графов — ориентированный и неориентированный, в зависимости от того, имеют ли ссылки направление. Графы используются повсеместно, например, для расчета наилучшего маршрута в навигационных приложениях или для формирования списка рекомендаций в социальных сетях.
Графы могут быть представлены в виде списка или матрицы.
Список
В данном случае все родительские узлы располагаются слева, а их дочерние элементы справа.
Матрица
В данном случае узлы распределяются по строкам и столбцам, пересечение строки и столбца показывает отношение между узлами: 0 означает, что узлы не связаны между собой, 1 — узлы связаны.
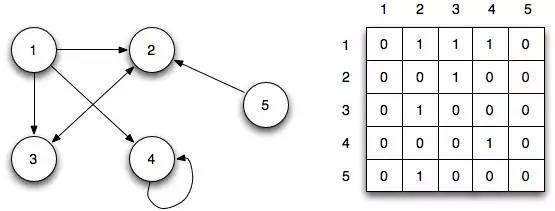
Поиск по графу осуществляется двумя методами — поиск в ширину (Breath-First-Search, BFS) и поиск в глубину (Depth-First-Search, DFS).
На этом у меня все. Надеюсь, вы нашли для себя что-то полезное. Счастливого кодинга!
Стек и очередь в JavaScript
Простая статья рассказывающая о базовых структура данных знания о которых может пригодится например при прохождение собеседования на позицию веб программиста.
В статье кратко описываются две важные структуры данных — стек и очередь, и демонстрируется пример их реализации в JavaScript.
Каждый раз, когда мы разрабатываем новое приложение, есть определенные моменты, которые которые нужно обдумать заранее, чтобы достичь конечной цели и получить хороший результат. Например, это может быть моменты связанные с хранением данных, работа с логикой состояния, то как должна обрабатываться аутентификация и т. д.
Наверное, одним из самых важных моментов является хранение данных. Данные — важный аспект каждого приложения. От выбора способа хранения данных зависит работа всего приложения, его скорость и надежность. Поэтому так важен выбор типа структуры данных. Существуют разные структуры данных, у каждой свой вариант использования, но все они могут иметь одну и ту же цель — достижение максимальной производительности приложения при хранении и работе с данными.
Представьте, что вам нужно вымыть стопку тарелок после обеда с семьей. Как бы вы это начали? Что ж, очевидный ответ: сверху.
Так же и стек представляет собой структуру последовательных и упорядоченных элементов, основанную на принципе «последний пришел — первым ушел» (LIFO — last in first out).
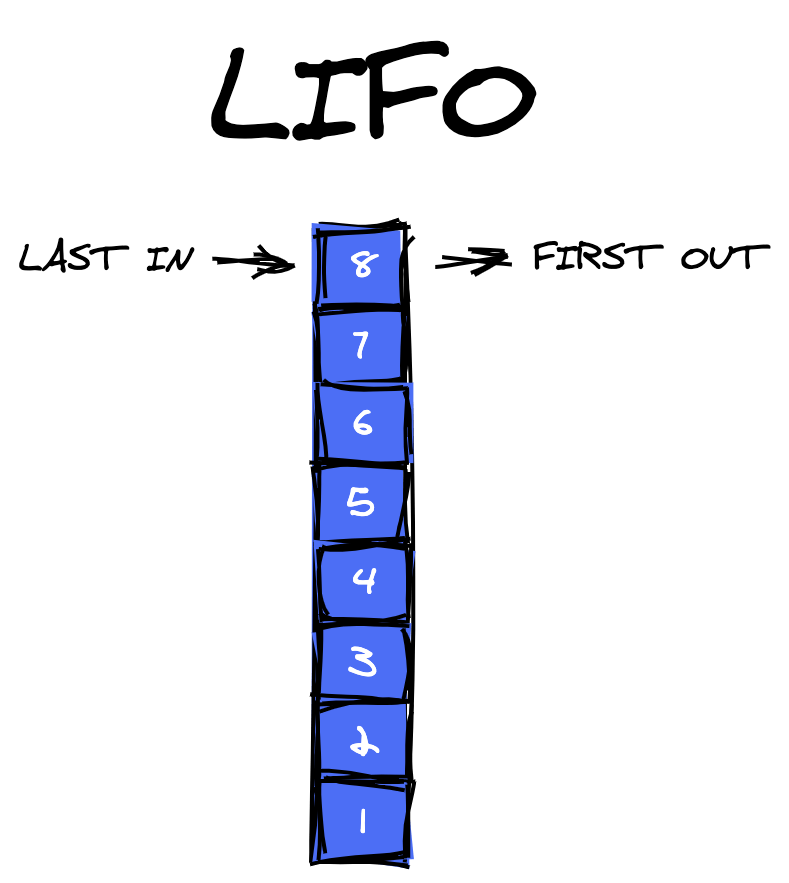
Структура данных стека выполняет две основные операции:
То есть стек — это линейная структура данных, что означает, что все элементы расположены в последовательном порядке. В результате операции push и pop могут происходить только на одном конце структуры, в данном случае на вершине стека.
Теперь, когда мы знаем, как работает структура данных стека, приступим к реализации на JavaScript.
Хорошая вещь в работе со стековыми структурами данных в JavaScript заключается в том, что JavaScript уже предоставляет нужные нам методы push и pop. Метод push добавляет элемент в массив, а метод pop удаляет последний элемент из массива.
Мы можем начать наш стек, создав новый массив с именем stack:
Теперь мы можем создать нашу операцию push. Эта функция будет отвечать за получение элемента в качестве аргумента и добавление этого элемента в наш стек.
Теперь мы создадим следующую операцию pop. Эта функция будет отвечать за удаление последнего элемента стека. По сути, это будет последний элемент, добавленный в стек. Поскольку мы не знаем, какой именно элемент может быть последним в стеке, эта функция не получает никаких аргументов.
Мы также можем реализовать структуру данных стека в JavaScript с помощью классов.
Некоторым разработчикам нравится реализовывать стековые структуры данных с использованием связанных списков вместо массивов в JavaScript. Хотя это может показаться хорошим решением, его производительность может быть не самой лучшей.
Как здесь указал Хёнджэ Джун, производительность массивов в сравнение со связанными списками в стековых структурах данных намного выше.
В некоторых особых случаях связанные списки могут работать лучше, чем массивы, но при реализации структур данных стека в JavaScript всегда предпочтительнее массивы. Методы массива, которые мы использовали, push и pop, имеют сложность O (1), что означает, что они совершено не зависят от количества обрабатываемых данных и всегда будут иметь одинаковую производительность.
Очередь
Представьте себе, что у нас есть очередь людей, которые хотят войти в конкретный ресторан. Последний человек в очереди будет последним, кто войдет в ресторан, в зависимости от размера очереди. Первый человек, который встанет в очередь, будет первым, кто войдет в ресторан.
Так же и очередь — это линейная структура последовательных и упорядоченных элементов, похожая на стек, с той разницей, что она работает по принципу «первым пришел — первым вышел» (FIFO — first in first out).

Структура данных очереди имеет две основные операции:
Как и случае со стеком в JavaScript есть уже готовый метод удаления первого элемента массива, которым является метод массива shift.
Благодаря этому реализация очереди в JavaScript становится очень простой и мощной. Мы можем определить наш массив очереди следующим образом:
Теперь мы можем создать нашу операцию постановки в очередь, чтобы добавить элемент в нашу очередь, точно так же, как мы это сделали с примером стека. Создадим функцию с именем enqueue и передадим ей аргумент:
Теперь мы можем создать функцию для удаления первого элемента нашей очереди для этого создадим функцию dequeue.
Все довольно просто.
Далее хотелось бы обратить внимание на некоторые скрытые различия между стеком и очередью, которые можно сначала не заметить, особенно в производительности.
Помните, что методы push и pop имеют сложность O(1)? Метод shift имеет сложность O(n).
Простая разница в сложности (или как еще говорят О большого) может иметь определяющее значение для работы приложения. Если вы планируете работать со структурой данных очереди, лучший вариант — создать собственную очередь. Например так:
Структуры данных как стека, так и очереди очень гибки и просты в реализации, но для каждой из них существуют разные варианты использования.
Стек полезен, когда мы хотим добавить элементы внутри списка в последовательном порядке и удалить последний добавленный элемент. Очередь полезна, когда нам нужно такое же поведение, но вместо удаления последнего добавленного элемента мы хотим использовать первый элемент, добавленный в список.
Заключение
Структуры данных — это очень полезные концепции, о которой нужно знать. Они могут помочь нам улучшить наше логическое мышление, то, как мы структурируем и решаем проблемы, и как мы находим наилучшие решения для конкретных случаев использования в наших современных приложениях. Стеки и очереди — это два мощных решения, которые могут помочь нам организовать данные в последовательном порядке в зависимости от того, какого результата мы хотим достичь, и получить эффективную и фантастическую производительность.
Дополнение от переводчика
Хотел бы в этой статье упомянуть еще об одной базовой структуре данных о которых следует помнить при упоминание стека и очереди.
Эта куча (heap)
Само слово куча в контексте JavaScript имеет два значения. Одно значение касается выделение памяти, второе — как раз касается организации данных. Просто и понятно эти два понятия рассмотрены например в этой статье.
Здесь я приведу лишь простое объяснение структуры данных куча.
Куча — это такой вид дерева, у которого есть одно важное свойство: если узел A — это родитель узла B, то ключ узла A больше ключа узла B (или равен ему).
Лучше всего это можно увидеть на картинке.
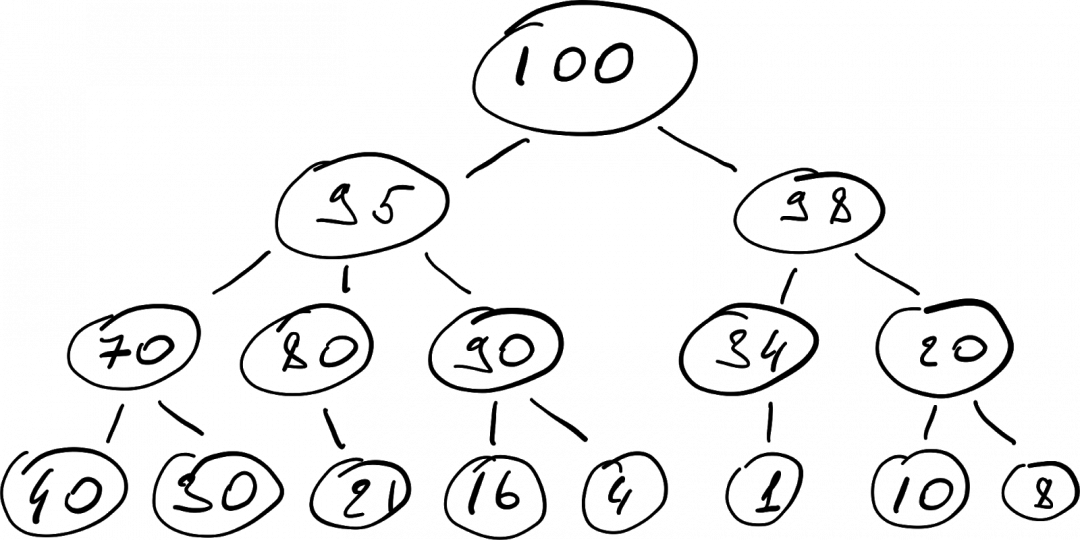
Реализации кучи как структуры данных в JavaScript совсем не так просто как стека и очереди. Более подробно это рассмотрено например в этой статье.
Как реализовать стек и очередь в JavaScript?
каков наилучший способ реализации стека и очереди в JavaScript?
Я ищу, чтобы сделать алгоритм шунтирования Ярда, и мне понадобятся эти структуры данных.
21 ответов
Javascript имеет методы push и pop, которые работают с обычными объектами массива Javascript.
для очередей смотрите здесь:
очереди.js-простая и эффективная реализация очереди для JavaScript, функция dequeue которой работает в амортизированном постоянном времени. В результате для больших очередей это может быть значительно быстрее, чем использование массивов.
Если вы хотите создать свои собственные структуры данных, вы можете создать свои собственные:
реализация стек и очереди используя Список Ссылок
вот реализация стека:
и вот как вы можете использовать стек:
если вы хотите увидеть подробное описание об этой реализации и, как это может быть далее улучшено, вы можете прочитать здесь:http://jschap.com/data-structures-in-javascript-stack/
вот код для реализации очереди в es6:
вот как вы можете использовать эту реализацию:
или вы можете использовать два массива для реализации структуры данных очереди.
Если я поп элементы сейчас, то выход будет 3,2,1. Но нам нужна структура FIFO, чтобы вы могли сделать следующее.
вот довольно простая реализация очереди с двумя целями:
реализация стека разделяет только вторую цель.
Если вы понимаете стеки с функциями push() и pop (), то queue-это просто одна из этих операций в смысле oposite. Oposite of push () является unshift () и oposite pop () es shift (). Затем:
Javascript array shift () работает медленно, особенно при удержании многих элементов. Я знаю два способа реализации очереди с амортизированной сложностью O(1).
сначала используется круговой буфер и удвоение таблицы. Я реализовывал это раньше. Вы можете увидеть мой исходный код здесь https://github.com/kevyuu/rapid-queue
второй способ-использовать два стека. Это код для очереди с двумя стеками
это сравнение производительности используя см. Этот тест jsperf
CircularQueue.shift () vs Array.shift ()
Как вы можете видеть, это значительно быстрее с большим набором данных
вот связанная версия списка очереди, которая также включает последний узел, как предложено @perkins и как наиболее уместно.
Вы можете использовать свой собственный класс настройки на основе концепции, здесь фрагмент кода, который вы можете использовать для выполнения материала
и чтобы проверить это, используйте консоль и попробуйте эти строки один за другим.
структура регулярного массива в Javascript представляет собой стек (первый вход, последний выход), а также может использоваться в качестве очереди (первый вход, первый выход) в зависимости от выполняемых вызовов.
проверьте эту ссылку, чтобы узнать, как заставить массив действовать как очередь:
Если вы ищете реализацию ES6 OOP структуры данных стека и очереди с некоторыми основными операциями (на основе связанных списков), то это может выглядеть так:
стек.js
очереди.js
и реализация LinkedList, которая используется для стека и очереди в примерах выше, может быть найдена на GitHub здесь.
создайте пару классов, которые предоставляют различные методы, которые имеет каждая из этих структур данных (push, pop, peek и т. д.). Теперь реализуем методы. Если вы знакомы с понятиями стека/очереди, это должно быть довольно просто. Вы можете реализовать стек с массивом и очередь со связанным списком, хотя, конечно, есть и другие способы сделать это. Javascript сделает это легко, потому что он слабо типизирован, поэтому вам даже не придется беспокоиться о generic типы, которые вам придется делать, если вы реализуете его на Java или C#.
вот моя реализация стеков.
мне кажется, что встроенный массив подходит для стека. Если вам нужна очередь в TypeScript, вот реализация
реализация стека тривиальна, как объясняется в других ответах.
однако я не нашел удовлетворительных ответов в этом потоке для реализации очереди в javascript, поэтому я сделал свой собственный.
в этом потоке есть три типа решений:
отложенные массивы сдвига являются наиболее удовлетворительным решением на мой взгляд, но они все еще хранят все в одном большом непрерывном массиве, который может быть проблематично, и приложение будет шататься, когда массив нарезается.
Я сделал реализацию, используя связанные списки небольших массивов (1000 элементов максимум каждый). Массивы ведут себя как массивы с задержкой сдвига, за исключением того, что они никогда не разрезаются: когда каждый элемент массива удаляется, массив просто отбрасывается.
пакета на НПМ С базовой функциональностью FIFO я только что нажал ее недавно. Код разделен на две части.
здесь это первая часть
а вот главная Queue класс:
тип аннотации ( : X ) можно легко удалить, чтобы получить код ES6 javascript.
Структуры данных в JavaScript: стек и очередь
Теперь остановитесь на мгновение и представьте, сколько раз мы, как пользователь и разработчик, используем стеки и очереди. Это потрясающе, не так ли? Из-за их повсеместности и сходства в дизайне я решил использовать их для ознакомления со структурами данных.
В информатике стек представляет собой линейную структуру данных. Если это предложение имеет для вас предельное значение, как оно изначально имело для меня, рассмотрим эту альтернативу: стек организует данные в последовательный порядок.
Этот последовательный порядок обычно описывается как стопка блюд в столовой. Когда тарелку добавляют в стопку блюд, она сохраняет порядок, когда она была добавлена; кроме того, когда добавляется другая тарелка, ее подталкивают к нижней части стопки. Каждый раз, когда мы добавляем новую тарелку, тарелка подталкивается к нижней части стопки, но она также представляет собой верхнюю часть стопки тарелок.
Этот процесс добавления тарелок сохранит последовательный порядок, когда каждая тарелка была добавлена в стек. Удаление тарелок из стека также сохранит последовательный порядок всех тарелок. Если тарелка удаляется из верхней части стека, каждая другая тарелка в стеке по-прежнему сохраняет правильный порядок в стеке. То, что я описываю, возможно, слишком выглядит чересчур подробно, но смысл заключается в том, как тарелки добавляются и удаляются в большинстве кафетерий!
Чтобы предоставить более технический пример стека, вспомним операцию «отменить» текстового редактора. Каждый раз, когда текст добавляется в текстовый редактор, этот текст помещается в стек. Первое дополнение к текстовому редактору представляет собой нижнюю часть стека; Последнее изменение представляет собой верхнюю часть стека. Если пользователь хочет отменить последнее изменение, верхняя часть стека будет удалена. Этот процесс можно повторить до тех пор, пока в стек не будет добавлено больше дополнений, это пустой файл!
Операции стека
Поскольку теперь у нас есть концептуальная модель стека, определим две операции стека:
Реализация стека
Теперь давайте напишем код для стека!
Свойства стека
Методы стека
Нам нужно определить методы, которые могут добавлять (push) и удалять (pop) данные из стека. Начнем с добавления данных.
Метод 1 из 2: push(data)
У нас есть два требования к этому методу:
Метод 2 из 2: pop()
Вот наши цели для этого метода:
pop() соответствует каждой из наших четырех целей. Сначала мы объявляем две переменные: size инициализируется размером стека, а deletedData присваивается последним данным, добавленным в стек. Во-вторых, мы удаляем пару ключ-значение наших последних добавленных данных. В-третьих, мы уменьшаем размер стека на 1. В-четвертых, мы возвращаем данные, которые были удалены из стека.
С добавлением нашего оператора if тело нашего кода выполняется только при наличии данных в нашем хранилище.
Полная реализация стека
Наша реализация Stack завершена. Независимо от порядка, в котором мы ссылаемся на любой из наших методов, наш код работает! Вот окончательная версия нашего кода:
От стека к очереди
Стек полезен, когда мы хотим добавить данные в последовательном порядке и удалить эти данные. Основываясь на своем определении, стек может удалить только самые последние добавленные данные. Что произойдет, если мы хотим удалить самые старые данные? Мы хотим использовать структуру данных под названием очередь.
Очередь
Подобно стеку, очередь представляет собой линейную структуру данных. В отличие от стека, очередь удаляет только самые старые добавленные данные.
Чтобы помочь вам концептуализировать, как это будет работать, давайте возьмем минутку, чтобы использовать аналогию. Представьте себе, что очередь очень похожа на систему билетов в гастроном. Каждый клиент берет билет и обслуживается при вызове их номера. Сначала нужно обслуживать клиента, который берет первый билет.
Давайте далее предположим, что этот билет имеет номер «один», отображаемый на нем. Следующий билет имеет номер «два», отображаемый на нем. Клиент, который берет второй билет, будет обслуживаться вторым. (Если бы наша система билетов работала как стек, то клиент, который первым вступил в стек, был бы последним, который будет обслуживаться!)
Более практичным примером очереди является цикл событий веб-браузера. По мере запуска различных событий, таких как щелчок кнопки, они добавляются в очередь цикла событий и обрабатываются в том порядке, в котором они попали в очередь.
Операции очереди
Поскольку теперь у нас есть концептуальная модель очереди, определим ее операции. Как вы заметили, операции очереди очень похожи на стек. Разница заключается в том, где данные удаляются.
Реализация очереди
Теперь давайте напишем код для очереди!
Свойства очереди
Методы очереди
Метод 1 из 3: size()
У нас есть две цели для этого метода:
Теперь давайте применим эту реализацию size стека к нашей очереди. Представьте, что пять клиентов берут билет из нашей системы билетов. У первого клиента есть билет, показывающий номер 1, а пятый клиент имеет билет с номером 5. С очередью сначала обслуживается клиент с первым билетом.
Давайте теперь представим, что первый клиент обслуживается и этот билет удаляется из очереди. Подобно стеку, мы можем получить правильный размер нашей очереди, вычитая 1 из 5. В нашей очереди в настоящее время есть четыре небронированных билета. Теперь возникает проблема: размер больше не соответствует правильным номерам билетов. Если мы просто вычтем один из пяти, мы будем иметь размер 4. Мы не можем использовать 4 для определения текущего диапазона оставшихся билетов в очереди. Есть ли у нас билеты в очереди с номерами от 1 до 4 или от 2 до 5? Ответ непонятен.
Представьте, что в нашем гастрономе есть две системы продажи билетов:
Вот самая сложная концепция в отношении наличия двух систем продажи билетов: когда номера в обеих системах идентичны, каждый клиент в очереди обработан и очередь пуста. Для усиления этой логики мы будем использовать следующий сценарий:
Теперь у нас есть свойство ( _newestIndex ), которое может указать нам наибольшее число (ключ), назначенное в очереди, и свойство ( _oldestIndex ), которое может рассказать нам самый старший номер индекса (ключа) в очереди.
Метод 2 из 3: enqueue (data)
Для enqueue у нас есть две цели:
На основе этих двух целей мы создадим следующую реализацию enqueue(data) :
Метод 3 из 3: dequeue()
Вот цели для этого метода:
Затем мы удаляем самый старый индекс в очереди. После его удаления мы увеличиваем значение this._oldestIndex на 1. Наконец, мы возвращаем данные, которые мы только что удалили.
Подобно проблеме в нашей первой реализации pop() с стеком, наша реализация dequeue() не обрабатывает ситуации, когда данные удаляются до добавления каких-либо данных. Нам нужно создать условное выражение для обработки этого прецедента.
Всякий раз, когда значения oldestIndex и newestIndex не равны, мы выполняем ранее имевшуюся логику.
Полная реализация очереди
Наша реализация очереди завершена. Давайте рассмотрим весь код.
Заключение
В этой статье мы рассмотрели две линейные структуры данных: стеки и очереди. Стек хранит данные в последовательном порядке и удаляет последние добавленные данные; Очередь хранит данные в последовательном порядке, но удаляет самые старые добавленные данные.
Если реализация этих структур данных кажется тривиальной, напомните себе о цели структуры данных. Они не предназначены для чрезмерной сложности; Они призваны помочь нам организовать данные. В этом контексте, если вы обнаружите, что данные должны быть организованы в последовательном порядке, рассмотрите возможность использования стека или очереди.



