Str Python. Строки в Python
Одним из самых распространённых типов данных является строковый. Вопреки расхожему мнению, программист чаще сталкивается не с числами, а с текстом. В Python, как известно, всё является объектами. Не исключение и строки – это объекты, состоящие из набора символов. Естественно, в языке существует широкий набор инструментов для работы с этим типом данных.
Строковые операторы
Операторы «+» и «*» в Питоне применимы не только к числам, но и к строкам.
Оператор сложения строк +
Оператор «+» выполняет операцию, называемую конкатенацией, — объединение строк.
Оператор умножения строк *
Оператор «*» дублирует строку указанное количество раз.
Это работает только с целочисленными множителями. Если умножить на ноль или отрицательное число, результатом будет пустая строка. Но лучше так не делать.
Оператор принадлежности подстроки in
Если надо проверить, содержится ли подстрока в строке, удобно пользоваться оператором “in”
Так же можно использовать этот оператор с «not» для инвертирования результата.
Встроенные функции строк в python
Пайтон содержит ряд удобных встроенных функций для работы со строками.
Функция ord() возвращает числовое значение символа, при чём, как для кодировки ASCII, так и для UNICODE.
Функция chr(n) возвращает символьное значение для данного целого числа, то есть выполняет действие обратное ord().
Функция len() возвращает количество символов в строке.
Функция str() возвращает строковое представление объекта.
Индексация строк
Строка является упорядоченной последовательностью символов. Другими словами, она состоит из символов, стоящих в определённом порядке. Благодаря этому, к символу можно обратиться по его порядковому номеру. Для этого надо указать номер символа в квадратных скобках. Нумерация начинается с нуля (0 – это первый символ).
Попытка обращения по индексу большему чем длина строки вызовет исключение IndexError:
Срезы строк
В Python существует механизм срезов коллекций. Срезы позволяют обратиться к подстроке используя индексы. Для этого надо в квадратных скобках указать: [начальный индекс : конечный индекс : шаг]. Каждый из параметров является необязательным. Поскольку строка это коллекция, срезы применимы и к ней.
Форматирование строки
В Python есть функция форматирования строки, которая официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Главной особенностью этой функции является возможность подстановки значения переменной в строку.
Чтобы это сделать с помощью f-строки необходимо:
Изменение строк
Тип данных строка в Python относится к неизменяемым (immutable), но это почти не влияет на удобство их использования, ведь можно создать изменённую копию. Для этого есть два возможных пути:
Как Вы можете видеть, данный метод не меняет строку, а возвращает изменённую копию.
Встроенные методы строк в Python
Поскольку строка в Пайтон – это объект, у него есть свои методы. Методы – это те же самые функции, просто они «закреплены» за объектами определённого класса.
Изменение регистра строки
Если Вам надо изменить регистр строки, удобно использовать один из следующих методов
capitalize() переводит первую букву строки в верхний регистр, остальные в нижний.
Не алфавитные символы не изменяются:
lower() преобразует все буквенные символы в строчные.
swapcase() меняет регистр на противоположный.
title() преобразует первые буквы всех слов в заглавные
upper() преобразует все буквенные символы в заглавные.
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы start и end. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа start и продолжающейся вплоть до позиции символа end, но не включая его. Если start указано, а end нет, метод применяется к части строки от start до конца.
count() подсчитывает количество точных вхождений подстроки в строку.
endswith() определяет, заканчивается ли строка заданной подстрокой.
index() ищет в строке заданную подстроку.
Этот метод идентичен find(), за исключением того, что он вызывает исключение ValueError, если подстрока не найдена.
rfind() ищет в строке заданную подстроку, начиная с конца.
Возвращает индекс последнего вхождения подстроки, который соответствует её началу.
rindex() ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен rfind(), за исключением того, что он вызывает исключение ValueError, если подстрока не найдена.
startswith() определяет, начинается ли строка с заданной подстроки.
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
isalnum() возвращает True, если строка не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра).
isalpha() определяет, состоит ли строка только из букв.
isdigit() определяет, состоит ли строка из цифр.
isidentifier() определяет, является ли строка допустимым идентификатором (название переменной, функции, класса и т.д.) Python.
isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову Пайтон, даже если его нельзя использовать.
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword.
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор Питон, вы должны проверить, что isidentifier() = True и iskeyword() = False.
islower() определяет, являются ли буквенные символы строки строчными.
isprintable() определяет, состоит ли строка только из печатаемых символов.
Это единственный метод данной группы, который возвращает True, если строка не содержит символов. Все остальные возвращаются False.
isspace() определяет, состоит ли строка только из пробельных символов.
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
‘\f’ и ‘\r’ являются escape-последовательностями для символов ASCII; ‘\u2005’ это escape-последовательность для Unicode.
istitle() определяет, начинаются ли слова строки с заглавной буквы.
isupper() определяет, являются ли буквенные символы строки заглавными.
Выравнивание строк, отступы
Методы из данной группы управляют отображением строки.
center() выравнивает строку по центру.
Если указан необязательный аргумент fill, он используется как символ заполнения:
Если строка больше или равна указанной ширине, строка возвращается без изменений:
expandtabs() заменяет каждый символ табуляции (‘\t’) пробелами. По умолчанию табуляция заменяются на 8 пробелов.
tabsize необязательный параметр, задающий количество пробелов.
ljust() выравнивание по левому краю.
lstrip() удаляет переданные в качестве аргумента символы слева. По умолчанию это пробелы.
replace() заменяет вхождения подстроки в строке.
Необязательный аргумент count, указывает количество замен, которое нужно осуществить:
rjust() выравнивание по правому краю строки в поле.
rstrip() обрезает пробельные символы.
strip() удаляет символы с левого и правого края строки.
Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
zfill() возвращает копию строки дополненную нулями слева для достижения длины строки указанной в параметре width:
Если строка короче или равна параметру width, строка возвращается без изменений:
Методы преобразование строки в список
Методы в данной группе превращают строку в другой тип данных и наоборот. Эти методы возвращают или принимают коллекции (чаще всего это список).
join() возвращает строку, которая является результатом конкатенации элементов коллекции и разделителя.
Стоит обратить внимание что все элементы итерируемого объекта должны быть строкового типа. Так же Вы могли заметить в последнем примере, что для объединения словаря в строку метод join() использует не значения, а ключи. Если Вам нужны именно ключи, то делается это так:
Сложнее ситуация, когда нужны пары ключ-значение. Здесь придётся сперва распаковать кортежи.
partition() делит строку на основе разделителя (действие, обратное join). Возвращаемое значение представляет собой кортеж из трех частей:
Если разделитель не найден, возвращаемый кортеж содержит строку и ещё две пустые строки:
rpartition() делит строку на основе разделителя, начиная с конца.
rsplit() делит строку на список из подстрок. По умолчанию разделителем является пробел.
split() делит строку на список из подстрок.
Ведет себя как rsplit(), за исключением того, что при указании maxsplit – максимального количества разбиений, деление начинается с левого края строки:
Если параметр maxsplit не указан, между rsplit() и split() разницы нет.
splitlines() делит текст на список строк и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Заключение
В этом уроке мы рассмотрели основные инструменты для работы со строками в Python. Как видите, они удобны и гибки. Есть встроенные функции и методы объекта «строка», строковые литералы. Ещё больше возможностей даёт нерассмотренный в этом уроке метод format и модуль re. Так же отдельного разговора заслуживает работа с кодировками. Следует отметить для тех, кто уже знаком с другими языками программирования: в отличие от некоторых из них, один символ в Пайтоне тоже является строкой. И изюминка напоследок. Поскольку в Питоне всё является объектом, у каждой строки тоже есть атрибуты.
Строки в python 3: методы, функции, форматирование
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s :
Вот примеры умножения строк:
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
Оператор принадлежности подстроки in
Встроенные функции строк в python
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() также обрабатывает символы Юникода:
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s :
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj :
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
Например, схематическое представление индексов строки ‘foobar’ выглядит следующим образом:
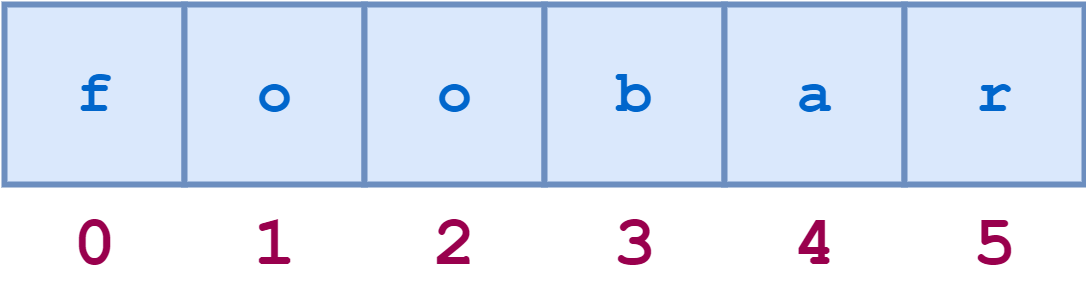
Отдельные символы доступны по индексу следующим образом:
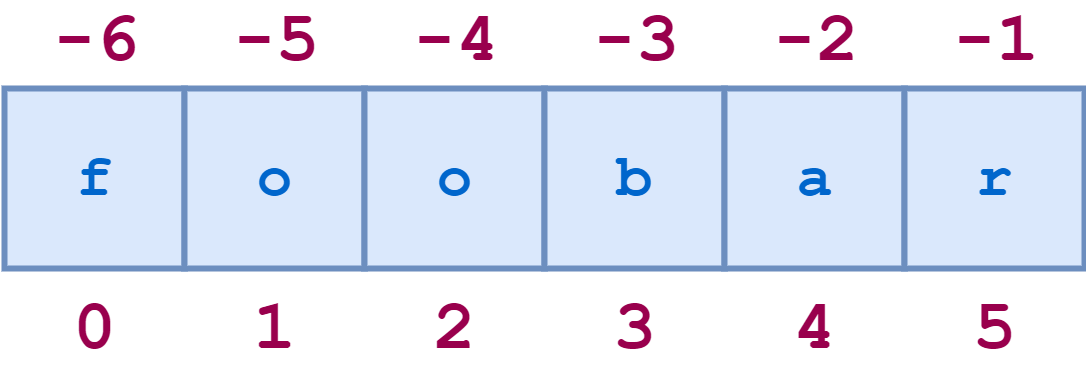
Вот несколько примеров отрицательного индексирования:
Срезы строк
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m] :
Для любой строки s и любого целого n числа ( 0 ≤ n ≤ len(s) ), s[:n] + s[n:] будет s :
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
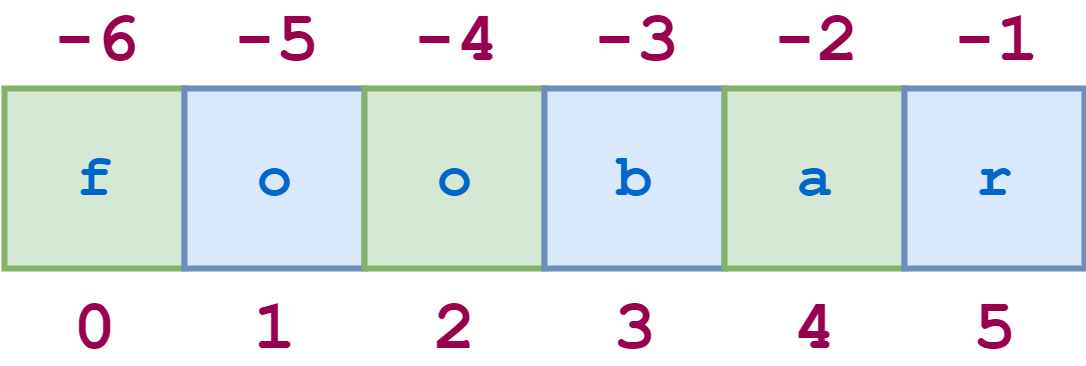
Иллюстративный код показан здесь:
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
Это общая парадигма для разворота (reverse) строки:
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале ( f’string’ ), и python заменит имя соответствующим значением.
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
Код с использованием f-string, приведенный ниже выглядит намного чище:
Любой из трех типов кавычек в python можно использовать для f-строки:
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError :
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
Есть встроенный метод string.replace(x, y) :
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ( [] ), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
Не алфавитные символы не изменяются:
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
string.count([, [, ]]) подсчитывает количество вхождений подстроки в строку.
s.count() возвращает количество точных вхождений подстроки в s :
Количество вхождений изменится, если указать и :
string.endswith( [, [, ]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith( ) возвращает, True если s заканчивается указанным и False если нет:
string.find([, [, ]]) ищет в строке заданную подстроку.
s.find() возвращает первый индекс в s который соответствует началу строки :
string.index([, [, ]]) ищет в строке заданную подстроку.
string.rfind([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
string.rindex([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
string.isalpha() определяет, состоит ли строка только из букв.
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
string.islower() определяет, являются ли буквенные символы строки строчными.
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
string.isspace() определяет, состоит ли строка только из пробельных символов.
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
‘\f’ и ‘\r’ являются escape-последовательностями для символов ASCII; ‘\u2005’ это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
string.isupper() определяет, являются ли буквенные символы строки заглавными.
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center( [, ]) выравнивает строку по центру.
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ( ‘\t’ ) пробелами. По умолчанию табуляция заменяются на 8 пробелов:
tabsize необязательный параметр, задающий количество пробелов:
string.ljust( [, ]) выравнивание по левому краю строки в поле.
string.lstrip([ ]) обрезает пробельные символы слева
s.lstrip() возвращает копию s в которой все пробельные символы с левого края удалены:
string.replace(
- , [, ]) заменяет вхождения подстроки в строке.
s.replace(
- , ) возвращает копию s где все вхождения подстроки
- , заменены на :
string.rjust( [, ]) выравнивание по правому краю строки в поле.
string.rstrip([ ]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
string.strip([ ]) удаляет символы с левого и правого края строки.
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
string.zfill( ) дополняет строку нулями слева.
s.zfill( ) возвращает копию s дополненную ‘0’ слева для достижения длины строки указанной в :
Если s содержит знак перед цифрами, он остается слева строки:
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( [] ), а кортеж заключен в простые ( () ).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join( ) объединяет список в строку.
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
Это можно исправить так:
string.partition( ) делит строку на основе разделителя.
s.rpartition( ) делит строку на основе разделителя, начиная с конца.
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
Если указан, он используется в качестве разделителя:
Это не работает, когда не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
string.splitlines([ ]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:



