I. Коротко об XML¶
Введение в XML¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
Структура XML¶
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Основные правила синтаксиса XML:
Открывающий и закрывающий теги должны определяться в одном регистре:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| меньше, чем | ||
| > | > | больше, чем |
| & | & | амперсанд |
| ‘ | ‘ | апостроф |
| « | « | кавычки |
Только символы и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Чтобы получить больше информации, необходимо модифицировать запрос //book[title[@lang=»it»]] вернет:
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
Примером использования XSD cхем может служить электронная отчетность:
XML Введение
Много языков базируются на XML; Некоторые примеры: XHTML, MathML, SVG, XUL, XBL, RSS, и RDF. Вы можете создать свой.
«Корректный» XML (правильно сформированный)
Правила оформления
Для корректного XML документа должны исполняться следующие условия:
Правильное оформление документа.
Соблюдаться все синтаксические правила XML.
Документ должен соответствовать семантическим правилам языка (которые обычно заданны в схеме XML или DTD (англ. Document Type Definition)).
Пример
Пример ниже показывает документ с тегом, который не закрывает сам себя и не имеет закрывающего тега (это неправильно оформленный XML документ).
Давайте посмотрим на корректную версию этого документа:
В большинство браузеров встроен дебаггер, который может идентифицировать плохо написанный XML документ.
Сущности
HTML и XML предлагают методы (которые называют сущности) для обращения к специальным зарезервированным символам (например угловые скобки, обозначающие начало и конец тега). Существует пять сущностей, которые вы обязательно должны знать:
| Сущность | Символ | Описание |
|---|---|---|
| > | Знак больше (одна из угловых скобок) | |
| & | & | Амперсанд |
| « | « | Двойная кавычка |
| ‘ | ‘ | Одинарная кавычка (апостроф) |
Не смотря на то, что по умолчанию создано всего пять сущностей, вы можете добавить в документ свои сущности используя Document Type Definition. Например, создать новую &warning; сущность, можно так:
Отображение XML
Есть также много других мощных методов отображения XML, например, XSLT(англ. Extensible Stylesheet Language Transformations), который может использоваться для преобразование XML в другие языки такие, как HTML. Это делает XML очень универсальным.
Рекомендации
Эта статья является очень маленьким введением в XML, с очень маленьким количеством примеров и ссылок для того, чтобы вы могли начать работать с этим языком. Чтобы больше узнать про XML, вам придётся искать информацию и более информативные статьи в интернете.
Изучайте HTML (англ. HyperText Markup Language), знание HTML поможет вам лучше понять XML.
Смотрите также
XML для начинающих
Вероятно, вы слышали о языке XML и вам известно множество причин, по которым его необходимо использовать в вашей организации. Но что именно представляет собой XML? В этой статье объясняется, что такое XML и как он работает.
В этой статье
Пометки, разметка и теги
Чтобы понять XML, полезно понимать идею пометки данных. Люди создавали документы на протяжении многих лет и на протяжении всего времени они их помечали. Например, преподаватели могут постоянно пометить документы учащихся. Учащиеся могут перемещать абзацы, уточнять предложения, исправлять опечатки и так далее. Пометка документа определяет структуру, смысл и внешний вид сведений в документе. Если вы когда-либо использовали функцию «Отслеживание изменений» в Microsoft Office Word, то использовали компьютеризированную форму пометки.
В мире информационных технологий термин «пометка» превратился в термин «разметка». При разметке используются коды, называемые тегами (или иногда токенами), для определения структуры, визуального оформления и — в случае XML — смысла данных.
Текст этой статьи в формате HTML является хорошим примером применения компьютерной разметки. Если в Microsoft Internet Explorer щелкнуть эту страницу правой кнопкой мыши и выбрать команду Просмотр HTML-кода, вы увидите читаемый текст и теги HTML, например
. В HTML- и XML-документах теги легко распознать, поскольку они заключены в угловые скобки. В исходном тексте этой статьи теги HTML выполняют множество функций, например определяют начало и конец каждого абзаца (
) и местоположение рисунков.
Отличительные черты XML
Документы в форматах HTML и XML содержат данные, заключенные в теги, но на этом сходство между двумя языками заканчивается. В формате HTML теги определяют оформление данных — расположение заголовков, начало абзаца и т. д. В формате XML теги определяют структуру и смысл данных — то, чем они являются.
При описании структуры и смысла данных становится возможным их повторное использование несколькими способами. Например, если у вас есть блок данных о продажах, каждый элемент в котором четко определен, то можно загрузить в отчет о продажах только необходимые элементы, а другие данные передать в бухгалтерскую базу данных. Иначе говоря, можно использовать одну систему для генерации данных и пометки их тегами в формате XML, а затем обрабатывать эти данные в любых других системах вне зависимости от клиентской платформы или операционной системы. Благодаря такой совместимости XML является основой одной из самых популярных технологий обмена данными.
Учитывайте при работе следующее:
HTML нельзя использовать вместо XML. Однако XML-данные можно заключать в HTML-теги и отображать на веб-страницах.
Возможности HTML ограничены предопределенным набором тегов, общим для всех пользователей.
Правила XML разрешают создавать любые теги, требуемые для описания данных и их структуры. Допустим, что вам необходимо хранить и совместно использовать сведения о домашних животных. Для этого можно создать следующий XML-код:
Как видно, по тегам XML понятно, какие данные вы просматриваете. Например, ясно, что это данные о коте, и можно легко определить его имя, возраст и т. д. Благодаря возможности создавать теги, определяющие почти любую структуру данных, язык XML является расширяемым.
Но не путайте теги в данном примере с тегами в HTML-файле. Например, если приведенный выше текст в формате XML вставить в HTML-файл и открыть его в браузере, то результаты будут выглядеть следующим образом:
Izzy Siamese 6 yes no Izz138bod Colin Wilcox
Веб-браузер проигнорирует теги XML и отобразит только данные.
Правильно сформированные данные
Вероятно, вы слышали, как кто-то из ИТ-специалистов говорил о «правильно сформированном» XML-файле. Правильно сформированный XML-файл должен соответствовать очень строгим правилам. Если он не соответствует этим правилам, XML не работает. Например, в предыдущем примере каждый открывающий тег имеет соответствующий закрывающий тег, поэтому в данном примере соблюдено одно из правил правильно сформированного XML-файла. Если же удалить из файла какой-либо тег и попытаться открыть его в одной из программ Office, то появится сообщение об ошибке и использовать такой файл будет невозможно.
Правила создания правильно сформированного XML-файла знать необязательно (хотя понять их нетрудно), но следует помнить, что использовать в других приложениях и системах можно лишь правильно сформированные XML-данные. Если XML-файл не открывается, то он, вероятно, неправильно сформирован.
XML не зависит от платформы, и это значит, что любая программа, созданная для использования XML, может читать и обрабатывать XML-данные независимо от оборудования или операционной системы. Например, при применении правильных тегов XML можно использовать программу на настольном компьютере для открытия и обработки данных, полученных с мейнфрейма. И, независимо от того, кто создал XML-данные, с ними данными можно работать в различных приложениях Office. Благодаря своей совместимости XML стал одной из самых популярных технологий обмена данными между базами данных и пользовательскими компьютерами.
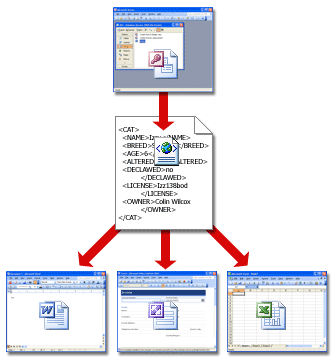
В дополнение к правильно сформированным данным с тегами XML-системы обычно используют два дополнительных компонента: схемы и преобразования. В следующих разделах описывается, как они работают.
Схемы
Не пугайтесь термина «схема». Схема — это просто XML-файл, содержащий правила для содержимого XML-файла данных. Файлы схем обычно имеют расширение XSD, тогда как для файлов данных XML используется расширение XML.
Схемы позволяют программам проверять данные. Они формируют структуру данных и обеспечивают их понятность создателю и другим людям. Например, если пользователь вводит недопустимые данные, например текст в поле даты, программа может предложить ему исправить их. Если данные в XML-файле соответствуют правилам в схеме, для их чтения, интерпретации и обработки можно использовать любую программу, поддерживающую XML. Например, как показано на приведенном ниже рисунке, Excel может проверять данные на соответствие схеме CAT.
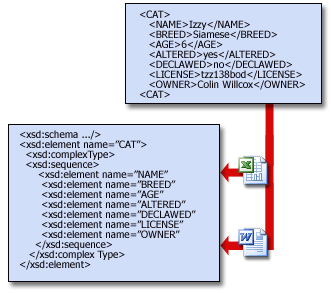
Не беспокойтесь, если в примере не все понятно. Просто обратите внимание на следующее:
Строковые элементы в приведенном примере схемы называются объявлениями. Если бы требовались дополнительные сведения о животном, например его цвет или особые признаки, то специалисты отдела ИТ добавили бы к схеме соответствующие объявления. Систему XML можно изменять по мере развития потребностей бизнеса.
Объявления являются мощным средством управления структурой данных. Например, объявление означает, что теги, такие как и
, должны следовать в указанном выше порядке. С помощью объявлений можно также проверять типы данных, вводимых пользователем. Например, приведенная выше схема требует ввода положительного целого числа для возраста кота и логических значений (TRUE или FALSE) для тегов ALTERED и DECLAWED.
Если данные в XML-файле соответствуют правилам схемы, то такие данные называют допустимыми. Процесс контроля соответствия XML-файла данных правилам схемы называют (достаточно логично) проверкой. Большим преимуществом использования схем является возможность предотвратить с их помощью повреждение данных. Схемы также облегчают поиск поврежденных данных, поскольку при возникновении такой проблемы обработка XML-файла останавливается.
Преобразования
Как говорилось выше, XML также позволяет эффективно использовать и повторно использовать данные. Механизм повторного использования данных называется преобразованием XSLT (или просто преобразованием).
Вы (или ваш ИТ-отдел) можете также использовать преобразования для обмена данными между » target=»_blank»>серверными системами, например между базами данных. Предположим, что в базе данных А данные о продажах хранятся в таблице, удобной для отдела продаж. В базе данных Б хранятся данные о доходах и расходах в таблице, специально разработанной для бухгалтерии. База данных Б может использовать преобразование, чтобы принять данные от базы данных A и поместить их в соответствующие таблицы.
Сочетание файла данных, схемы и преобразования образует базовую систему XML. На следующем рисунке показана работа подобных систем. Файл данных проверяется на соответствие правилам схемы, а затем передается любым пригодным способом для преобразования. В этом случае преобразование размещает данные в таблице на веб-странице.
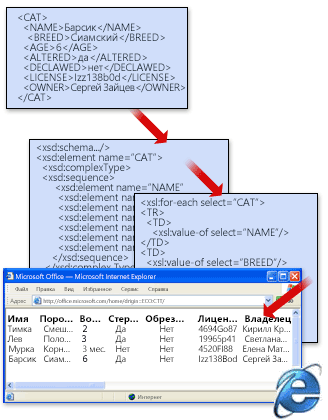
В следующем примере кода показан один из способов написания преобразования. Она загружает данные в таблицу на веб-странице. В этом примере суть не в том, чтобы показать, как написать преобразование, а в том, чтобы показать одну форму, которую может принять преобразование.
В этом примере показано, как может выглядеть текст одного из типов преобразования, но помните, что вы можете ограничиться четким описанием того, что вам нужно от данных, и это описание может быть сделано на вашем родном языке. Например, вы можете пойти в отдел ИТ и сказать, что необходимо напечатать данные о продажах для конкретных регионов за последние два года, и что эти сведения должны выглядеть так-то и так-то. После этого специалисты отдела могут написать (или изменить) преобразование, чтобы выполнить вашу просьбу.
Корпорация Майкрософт и растущее число других компаний создают преобразования для различных задач, что делает использование XML еще более удобным. В будущем, скорее всего, можно будет скачать преобразование, отвечающее вашим потребностям без дополнительной настройки или с небольшими изменениями. Это означает, что со временем использование XML будет требовать все меньше и меньше затрат.
XML в системе Microsoft Office
Профессиональные выпуски Office обеспечивают всестороннюю поддержку XML. Начиная с Microsoft Office 2007, в Microsoft Office используются форматы файлов на основе XML, например DOCX, XLSX и PPTX. Поскольку XML-данные хранятся в текстовом формате вместо запатентованного двоичного формата, ваши клиенты могут определять собственные схемы и использовать ваши данные разными способами без лицензионных отчислений. Дополнительные сведения о новых форматах см. в сведениях о форматах Open XML и расширениях имен файлов. К другим преимуществам относятся:
Меньший размер файлов. Новый формат использует ZIP и другие технологии сжатия, поэтому размер файла на 75 процентов меньше, чем в двоичных форматах, применяемых в более ранних версиях Office.
Более простое восстановление данных и большая безопасность. Формат XML может быть легко прочитан пользователем, поэтому если файл поврежден, его можно открыть в Блокноте или другой программе для просмотра текста и восстановить хотя бы часть данных. Кроме того, новые файлы более безопасны, потому что они не могут содержать код Visual Basic для приложений (VBA). Если новый формат используется для создания шаблонов, то элементы ActiveX и макросы VBA находятся в отдельном, более безопасном разделе файла. Кроме того, можно удалять личные данные из документов с помощью таких средств, как инспектор документов. Дополнительные сведения об использовании инспектора документов см. в статье Удаление скрытых и персональных данных при проверке документов.
Пока все хорошо, но что делать, если у вас есть данные XML без схемы? У Office программ, которые поддерживают XML, есть свои подходы к работе с данными. Например, Excel выдаст схему, если вы откроете XML-файл, который еще не имеет такой схемы. Excel затем вы можете загрузить эти данные в XML-таблицу. Для сортировки, фильтрации или добавления вычислений в данные можно использовать XML-списки и таблицы.
Включение средств XML в Office
По умолчанию вкладка «Разработчик» не отображается. Ее необходимо добавить на ленту для использования команд XML в Office.
В Office 2016, Office 2013 или Office 2010: Отображение вкладки «Разработчик».
Что такое XML
Если вы тестируете API, то должны знать про два основных формата передачи данных:
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
И разберемся, что означает эта запись.
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
Текст внутри угловых скобок — название тега.
Тега всегда два:
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на » target=»_blank»>сервер. Там будет значение count = 7.
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
У элемента attribute есть атрибуты:
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на » target=»_blank»>сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
Итого, как используется схема при разработке SOAP API:
| Правильный запрос | Неправильный запрос |
|---|---|
| Нет обязательного поля name | |
| Опечатка в названии тега (mail вместо email) | |
| . | . |
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
А в WSDl сервиса она записана еще проще:
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для » target=»_blank»>сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
| Нет | Да |
|---|---|
| Есть элементы «test» и «dev», но они расположены рядом, а корневого, внутри которого все лежит — нету. Это скорее похоже на 2 XML документа | А вот тут уже есть элемент credential, который является корневым |
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
Это тоже самое, что передать в нем пустое значение
Аналогично » target=»_blank»>сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
Для тестирования пробуем передать его без кавычек:
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на » target=»_blank»>сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале



