Предназначение файла robots.txt на сайте
Здравствуйте! В моей жизни было такое время, когда я абсолютно ничего не знал про создание сайтов и уж тем более не догадывался про существование файла robots.txt.

Когда простой интерес перерос в серьезное увлечение, появились силы и желание изучить все тонкости. На форумах можно встретить множество тем, связанных с этим файлом, почему? Все просто: robots.txt регулирует доступ поисковых систем к сайту, управляя индексированием и это очень важно!
Зачем скрывать определенное содержимое сайта? Вряд ли Вы обрадуетесь, если поисковый робот проиндексирует файлы администрирования сайта, в которых могут храниться пароли или другая секретная информация.
Для регулирования доступа существуют различные директивы:
Обратите внимание, с 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Всегда нужно помнить о безопасности. Этот файл может посмотреть любой желающий, поэтому не нужно указывать в нем явный путь к административным ресурсам (панелям управления и т.д.). Как говориться, меньше знаешь — крепче спишь. Поэтому, если на страницу нет никаких ссылок и Вы не хотите ее индексировать, то не нужно ее прописывать в роботсе, ее и так никто не найдет, даже роботы-пауки.
Сразу хочу отметить, что поисковые системы по разному относятся к этому файлу. Например, Яндекс безоговорочно следует его правилам и исключает запрещенные страницы из индексирования, в то время как Google воспринимает этот файл как рекомендацию и не более.
Для запрета индексирования страниц возможно применение иных средств:
При этом Google может успешно добавить в поисковую выдачу страницы, запрещенные к индексации, несмотря на все ограничения. Его основной аргумент — если на страницу ссылаются, значит она может появится в результатах поиска. В данном случае рекомендуется не ссылаться на такие страницы, но позвольте, файл robots.txt как раз и предназначен для того, чтобы выкинуть из выдачи такие страницы… На мой взгляд, логика отсутствует 🙄
Удаление страниц из поиска
Если запрещенные страницы все же были проиндексированы, то необходимо воспользоваться Google Search Console и входящим в ее состав инструментом удаления URL-адресов:
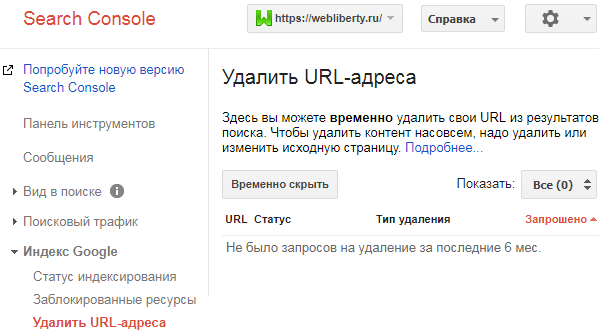
Аналогичный инструмент есть в Яндекс Вебмастере. Подробнее об удалении страниц из индекса поисковых систем читайте в отдельной статье.
Проверка robots.txt
Продолжая тему с Google, можно воспользоваться еще одним инструментом Search Console и проверить файл robots.txt, правильно ли он составлен для запрета индексирования определенных страниц:
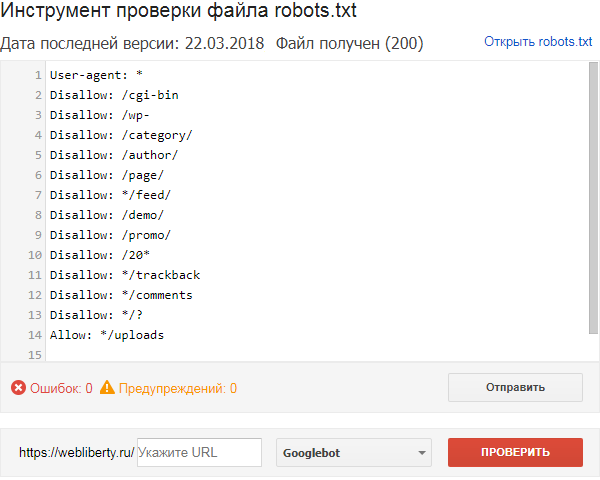
Для этого достаточно ввести в текстовое поле URL-адреса, которые необходимо проверить и нажать кнопку Проверить — в результате проверки выяснится, запрещена данная страница к индексации или же ее содержимое доступно для поисковых роботов.
У Яндекса также есть подобный инструмент, находящийся в Вебмастере, проверка осуществляется аналогичным образом:
Что такое robots.txt [Основы для новичков]

Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
« Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на » target=»_blank»>сервер, » target=»_blank»>хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на » target=»_blank»>сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
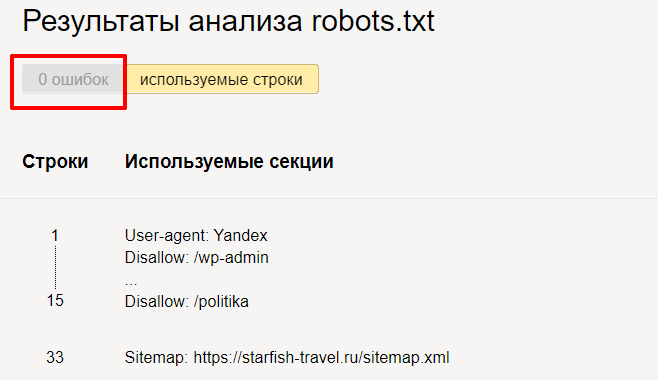
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
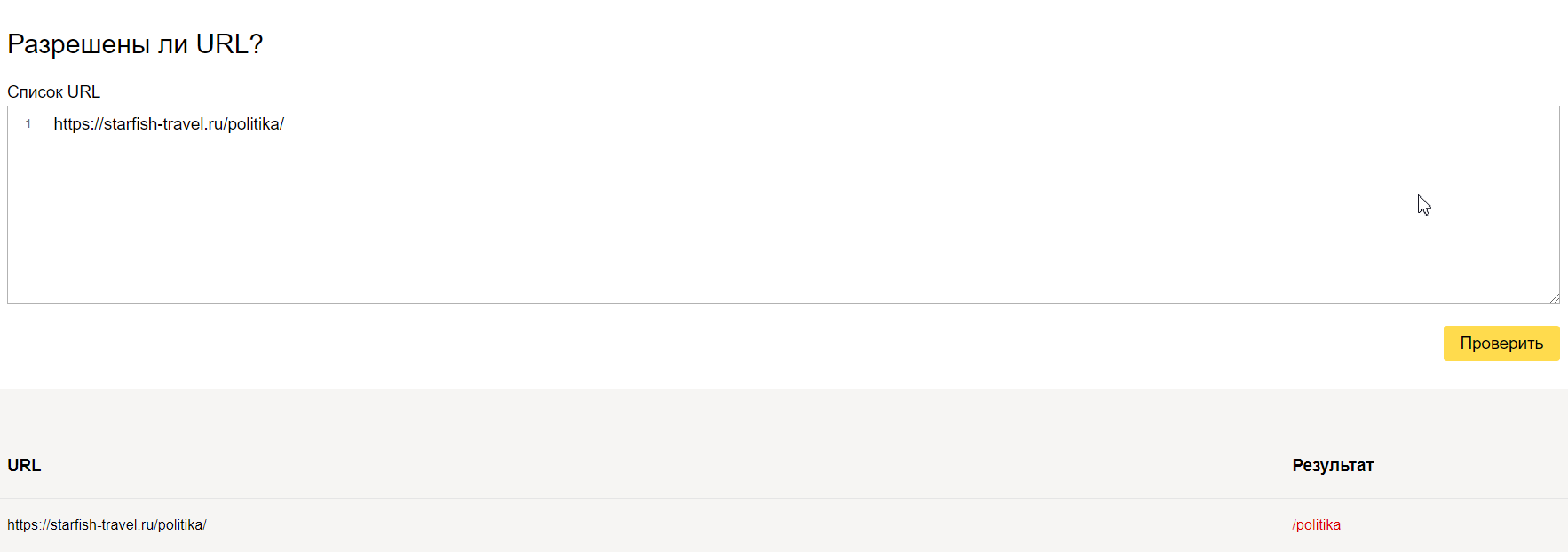
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Что такое robots.txt, и зачем он нужен сайту

Поделиться этим постом

Файл robots.txt хранится в формате текста на » target=»_blank»>сервере. Он состоит из латинских символов и знаков, с помощью которых создаются команды для роботов о том, какие страницы нужно индексировать, а какие нельзя. Robots.txt создаётся по стандартному синтаксису, его директивы понимают роботы всех поисковых систем. Если не использовать этот файл, все страницы сайта будут просканированы без разбора. Это может негативно сказаться на результатах поисковой выдачи.
1. Что такое robots.txt
Это файл, в котором находится обычный текст, состоящий минимум из двух строк. Точное количество слов определяется в индивидуальной потребности запретить или разрешить обход конкретных страниц. Каждая строка файла — одна команда в форме директивы. Она описывает конкретный раздел, категорию или страницу. Каждый раздел начинается с новой строки.
Robots.txt редактируется в любое время, если возникает потребность закрыть от индекса дубли, персональные данные, пользовательские соглашения или новые страницы. Для этого он выгружается через файловый менеджер и редактируется на компьютере. После внесения правок обновлённый robots.txt нужно снова загрузить на » target=»_blank»>сервер и проверить его по ссылке yoursite.ru/robots.txt, где yoursite.ru — название сайта.
Файл также можно создать для запрета или разрешения индексации сразу всех страниц сайта. С его помощью также можно скрывать разделы ресурса для разных роботов. Если прописанные директивы относятся ко всем роботам, в конце первой строки ставится знак «*». При обращении к конкретному поисковику необходимо прописать его название в первой строке-директиве User-agent.
1.1. Для чего нужен robots.txt
Иногда роботы не учитывают директивы из robots.txt. Такое случается из-за ошибок в синтаксисе. Наиболее распространенные:
Время от времени следует проверять корректность и доступ к robots.txt, а также исследовать его на ошибки в синтаксисе. Кстати, в некоторых CMS и » target=»_blank»>сервер, » target=»_blank»>хостинг-панелях есть возможность редактировать файл из админки.
2. Синтаксис robots.txt
Синтаксис файла состоит из обязательных и необязательных директив. Для правильного считывания роботами их нужно прописывать в определённой последовательности: первая директива в каждом разделе — User Agent, далее Disallow, Allow, в конце — главное зеркало и карта сайта.
Несмотря на стандартные правила создания, поисковые боты по-разному считывают информацию из файла. Например, запрет индексации параметров страницы понимает только Yandex, а Googlebot пропустит эту строку.
Важное правило — не допустить ошибки в директивах. Один неверный символ может привести к некорректной индексации.
Чтобы минимизировать риск ошибок, придерживайтесь основных правил составления синтаксиса:
2.1. Основные директивы синтаксиса
3. Как создать robots.txt
Файл robots.txt создаётся в текстовом редакторе на компьютере либо генерируется автоматически при помощи онлайн-сервисов. Отредактировать его можно в обычном блокноте. Пример robots.txt:
В директивах иногда добавляют комментарии для веб-мастеров, которые вставляют в файл после знака # с новой строки. Роботы не учитывают эти данные. Пример robots.txt с комментарием:
Если вы сомневаетесь или не имеете возможности создать файл самостоятельно, воспользуйтесь виртуальным сервисом. Генераторы robots.txt создают файлы по заданным параметрам, которые нужно сразу прописать. Примеры инструментов для генерации: pr-cy и Seolib.
4. Как проверить robots.txt
Протестировать готовый документ можно в сервисах Google и Yandex. Проверка robots.txt возможна лишь после загрузки окончательной версии в корень сайта. Если файл не загружен в корневой каталог, сервис выдаст ошибку.
При обнаружении и успешной проверке файла появляется соответствующее сообщение:
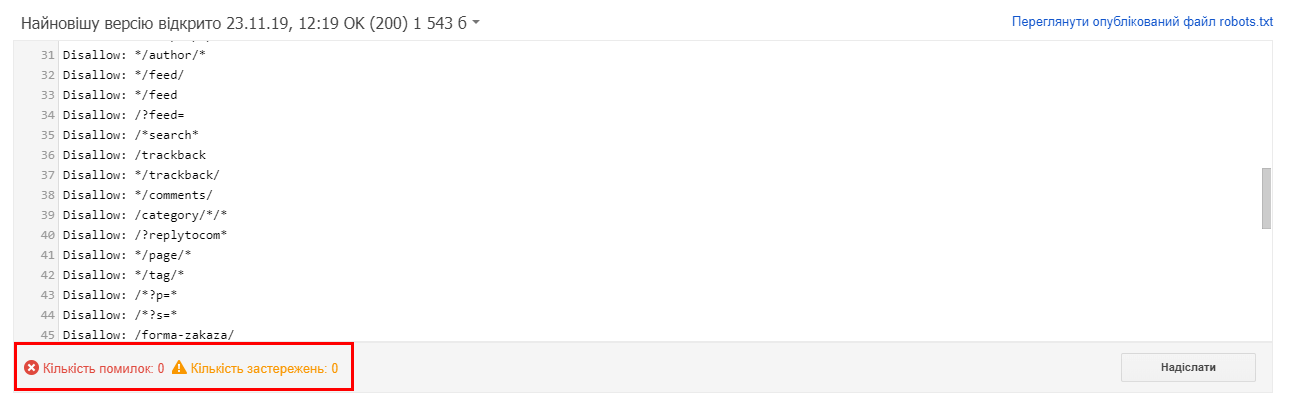
Наглядно посмотреть, как проверить корректность настройки файла robots.txt, вы можете в этом видео:
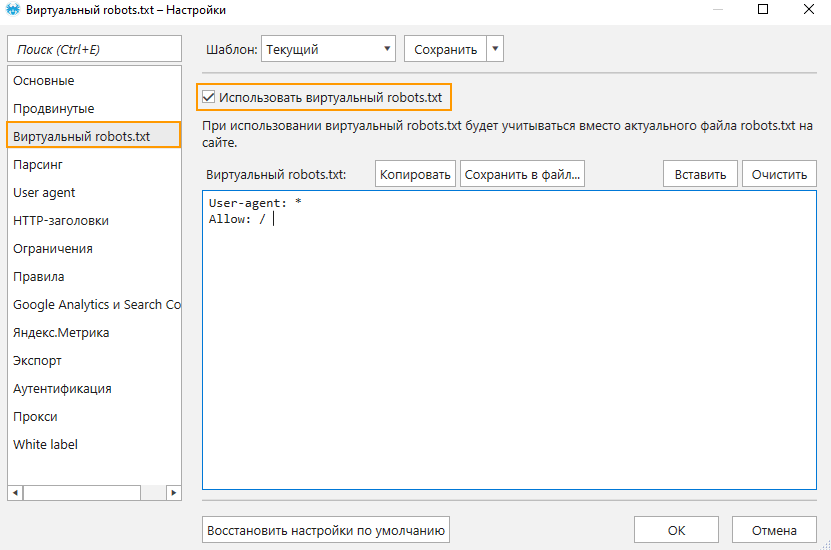
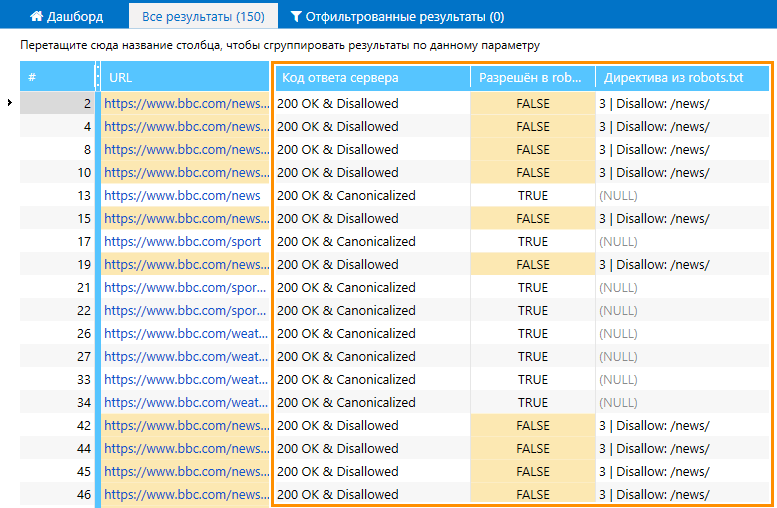
Тестировать различные конфигурации robots.txt вы можете даже в бесплатной версии Netpeak Spider без ограничений по времени. Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Подводим итоги
Файл robots.txt состоит из текстовых директив и хранится в корне сайта на » target=»_blank»>сервере. Он используется для разрешения и запрета индексации поисковиками страниц, разделов, каталогов и отдельных параметров.
Дополнительно в файле можно прописать главное зеркало и ссылку на карту сайта. Условия индексации могут касаться всех поисков либо каждого по отдельности. Через robots.txt можно задать уникальные условия для каждого поисковика.
При составлении файла важно соблюдать стандартные правила. Создать его можно вручную либо при помощи онлайн-генератора. Для проверки и тестирования готового файла используются онлайн-сервисы либо десктопные программы, например Netpeak Spider.



