Что такое robots.txt [Основы для новичков]

Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
« Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Как создать и правильно настроить Robots.txt
Robots.txt является стандартом исключений для роботов, принятым консорциумом W3C 30 января 1994 года. Его использует большая часть современных поисковиков, как рекомендацию к индексированию проекта.
Зачем Robots.txt нужен для SEO?
Robots играет одну из важнейших ролей для поисковой оптимизации.
В нем ненужные страницы, не содержащие полезной для пользователей информации, исключаются из поиска, указывается путь к Sitemap.
Если допустить ошибку в инструкциях и директивах, сайт может полностью пропасть из поискового индекса. Важно уметь корректно настраивать данный файл, так как от этого зависит видимость вашего сайта в поисковых системах и дальнейший рост объема трафика на проекте.
Поэтому SEO специалисты, изучая сайт, который им нужно будет продвигать, первым делом проверяют именно роботс.
Где находится и как создать?
Файл robots.txt располагается в корневой директории сайта. К примеру, на сайте https://webmasterie.ru путь к файлу robots будет таким: https://webmasterie.ru/robots.txt.
Ручное создание robots.txt
Для самостоятельного создания файла достаточно воспользоваться любым текстовым редактором:
Затем загружаете файл в корневой каталог сайта – папку с названием вашего ресурса, где также располагаются индексный файл index.html и файлы движка, на базе которого сделан сайт. Для загрузки robots.txt на » target=»_blank»>сервер используют:
Есть движки управления сайтами, у которых есть встроенная функция, позволяющая создать файл роботс в администраторской панели сайта. Если же ее нет, можно установить специальные модули или плагины.
Вообще нет разницы, каким из вышеперечисленных методов создавать данный текстовый файл.
Онлайн генераторы
Вариант для ленивых – онлайн сервисы, генерирующие роботс автоматически. В интернете можно найти множество подобных инструментов, к примеру, на сайте CY-PR.
Такой вариант хорошо подходит владельцам огромного количества сайтов, потому что для всех них будет сложно вручную прописать практически одни и те же инструкции.
Автоматически сгенерированные файлы robots.txt могут потребовать самостоятельной корректировки, поэтому иметь базовые знания синтаксиса и правил написания файла все равно нужно.
Готовые шаблоны
В Сети нет проблем отыскать шаблоны готового robots.txt для популярных движков по типу WordPress, Joomla, Drupal и так далее. В шаблон лишь избавляет от многократного написания стандартных директив и учитывает нюансы определенного движка сайта. Но и тут нужны знания, потому что сам по себе шаблон не предоставит корректно настроенный файл и каждый проект может быть индивидуален.
Как редактировать?
После создания файла Robots вы можете его редактировать в ходе оптимизации ресурса. Делается это непосредственно в текстовом файле robots.txt с соблюдением правил и синтаксиса файла. После редактирования robots.txt выгружайте на сайт обновленную версию файла. Так же для определенных CMS существуют плагины и дополнения, которые позволяют редактировать данный файл прям в админ панели.
Директивы Robots.txt
В Robots.txt прописываются директивы для роботов поисковых систем, тем самым помогая им понять, какие страницы/разделы индексировать, а какие – нет. Рассмотрим, какие директивы что означают:
1. User-Agent. Это обязательная директива, определяющая, к какому роботу будут применяться прописанные ниже правила. По сути, это обращение к конкретному роботу или всем поисковым ботам. Все файлы начинаются именно с этой строчки.
2. Disallow. Самая распространенная директива, запрещающая индексировать отдельные страницы или целые разделы веб-сайта. Здесь зачастую указывают:
3. Allow. Противоположная Disallow директива, разрешающая поисковому роботу обход конкретных страниц или разделов сайта. Здесь, как и в Disallow, допускается применение спецсимволов.
4. Sitemap. Данная директива сообщает ботам расположение XML карты сайта. Нужно указывать полный URL. Она важна для поисковых машин Google и Яндекс, так как при обходе сайта в первую очередь они обращаются именно к Sitemap, где показана структура ресурса со внутренними ссылками, приоритетами индексации страниц и датами их создания или изменения.
5. Clean-param. Запрещает ботам обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц. В основном проблема динамических параметров встречается на сайтах интернет-магазинов, а именно в URL-адресах для передачи данных по источникам сессий, персональных идентификаторов посетителей.
6. Crawl-delay (уже не поддерживается Яндекс и Google). Инструкция ограничивает частоту посещений одного бота в интервал времени. То есть, он задает в секундах минимальный промежуток времени между окончанием загрузки одного документа и началом загрузки следующего. Благодаря данной директиве снижается нагрузка на » target=»_blank»>сервер, чтобы роботы не посещали сайт слишком часто. Проблема актуальна на крупных сайтах с большим количеством страниц.
Важно! Яндекс отказался от Crawl-delay. Вот какой ответ я получил от поисковика:

7. Host (уже не поддерживается Яндекс). Раньше это была межсекционная инструкция чисто для Яндекса, никакие другие поисковики ее не понимали. Она служила для указания главному роботу Яндекса главного зеркала сайта, если есть доступ к сайту по нескольким доменам. Но с марта месяца 2018 года Яндекс больше не использует директиву Host. Ее функции взял на себя раздел “Переезд сайта в Вебмастере” и 301 редирект.
Что нужно исключать из индекса
1. В первую очередь роботам следует запретить включать в индекс любые дубли страниц. Доступ к странице должен осуществляться только по одному URL. Обращаясь к сайту, поисковый бот по каждому УРЛу должен получать в ответ страницу с уникальным содержанием. Дубли часто появляются у CMS в процессе создания страниц. Так, один и тот же документ можно найти по техническому УРЛ http://site.ru/?p=391&preview=true и ЧПУ http://site.ru/chto-takoe-seo. Нередко дубли появляются и из-за динамических ссылок. Нужно их всех скрывать от индекса с помощью масок:
2. Все страницы с неуникальным контентом. Такие документы рекомендуется скрыть от поисковых машин до того, как они попадут в индекс.
3. Все страницы, применяемые при работе сценариев. К таким страницам относят такие, где есть подобные сообщения: “Спасибо за ваш отзыв!”.
4. Страницы, включающие индикаторы сессий. Для подобных страниц тоже рекомендуется использовать директиву Disallow:
5. Все файлы движка управления сайтом. К ним относятся файлы шаблонов, администраторской панели, тем, баз и прочие:
6. Бесполезные для пользователей страницы и разделы. Без какого-либо содержания, с неуникальным контентом, результаты поиска, несуществующие и так далее.
Держите файл robots.txt в чистоте, и тогда ваш сайт будет индексироваться быстрее и лучше, а ранжироваться выше.
Структура Robots.txt
Так выглядит стандартный шаблон структуры файла robots обычного веб-сайта:
Как видно из инструкции выше, файл содержит блоки с инструкциями и начинается он, как я уже упоминал выше, с правила User-agent, указывающего, к какому роботу идет обращение и прописываются директивы ниже.
Вот несколько примеров директив User-agent для роботов разных поисковиков:
Оптимизаторы в robots.txt эти три директивы используют чаще всего. Это общие роботы поисковиков, но есть также и инструкции, описываемые для ботов, индексирующих, например, только новостные разделы:
В них тоже допускается прописывать определенные директории.
Таким образом мы разрешаем обходить сайт только роботам Яндекса и Google:
После каждого правила User-agent следуют инструкции для робота, указанного в данной строке. Чаще всего применяются команды Disallow. Allow прописываются редко, так как отсутствие противоположной директории равносильно разрешению на индексацию.
Кириллица в файле Robots
Писать кириллические символы в директориях robots.txt, а также HTTP-заголовках » target=»_blank»>сервера запрещено.
Чтобы указывать названия кириллических доменов, воспользуйтесь Punycode. URL-адреса указывайте в кодировке, которая соответствует структуре ресурса.
Основные правила, характеристики файла и синтаксис
При создании файла robots.txt необходимо соблюдать синтаксические правила и следовать характеристикам файла, от которых зависит корректность его работы. Рассмотрим их подробнее:
Как проверить Robots.txt?
После загрузки файла на » target=»_blank»>сервер нужно обязательно проверить, доступен ли он, корректно ли написан и нет ли ошибок.
Проверка на сайте
Сделав все верно и загрузив файл в корневой каталог сайта, он станет доступным по ссылке типа site.ru/robots.txt (вместо site.ru указывается URL вашего ресурса).
Это общедоступный файл и его можно посмотреть и изучить у любого сайта.
Проверка на ошибки
Сделать это можно двумя способами:
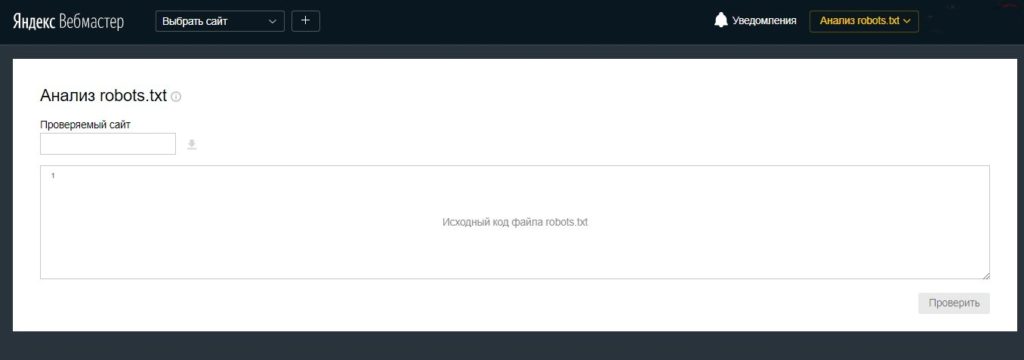
Здесь вы увидите все ошибки в файле, если они есть, и получите сообщения о серьезных ограничениях в директивах.
Robots.txt в Яндекс и Google
Многие оптимизаторы, делая первые шаги в работе с robots.txt, задаются логичным вопросом о том, почему нельзя указать общий User-agent: * и не указывать для робота каждой поисковой системы одни и те же инструкции. Дело в том, что поисковик Google более позитивно воспринимает директиву User-agent: Googlebot в файле robots, как и Яндекс отдельную директиву User-agent: Yandex.
Прописывая правила отдельно для Google и Яндекс, вы сможете управлять индексацией страниц и разделов веб-ресурса посредством Robots. Более того, применяя персональные User-agent можно запретить индексацию некоторых файлов Google, при этом оставить их доступными для роботов Яндекса, и наоборот.
Максимально допустимый размер текстового документа robots в 32 КБ предоставляет возможность почти любому сайту указать все важнейшие для индексирования инструкции в отдельных юзер-агентах для разных поисковиков. Поэтому не вижу смысла проводить рискованные эксперименты.
Заключение
Файл Robots – это один из ключевых инструментов для успешного SEO-продвижения сайта. С его помощью вы можете непосредственно влиять на включение в индекс различных страниц и разделов веб-ресурса.
Правильно настроенный файл поспособствует экономии краулингового бюджета, который очень ограничен, облегчит жизнь поисковым машинам, которым не придется обходить сотни служебных страниц, разгрузит ваш » target=»_blank»>сервер, уберет из выдачи спам. И самое главное – ваш сайт будет индексироваться быстро и корректно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на » target=»_blank»>сервер, » target=»_blank»>хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на » target=»_blank»>сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
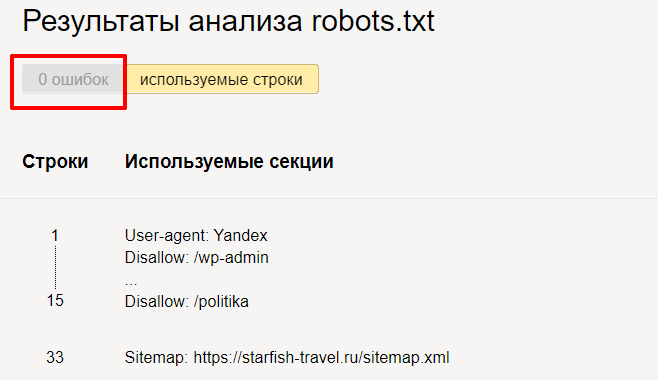
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
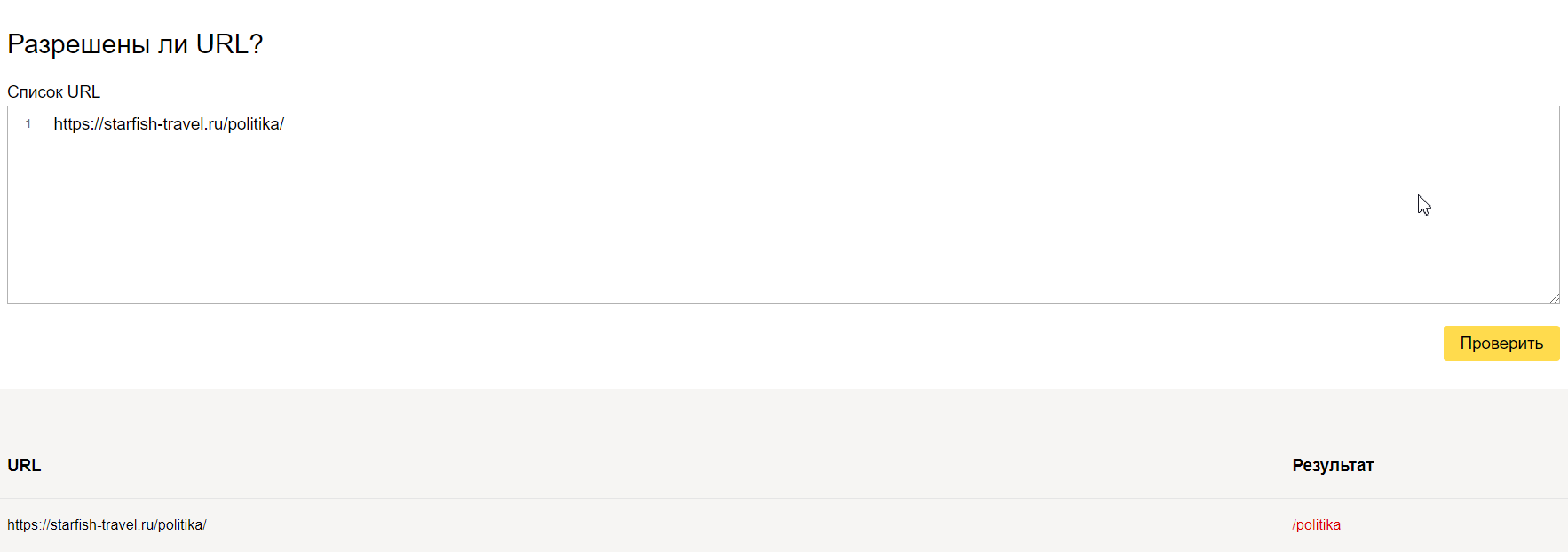
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Общие сведения о файлах robots.txt
В файле robots.txt содержатся инструкции, которые говорят поисковым роботам, какие URL на вашем сайте им разрешено обрабатывать. С его помощью можно ограничить количество запросов на сканирование и тем самым снизить нагрузку на сайт. Файл robots.txt не предназначен для того, чтобы запрещать показ ваших материалов в результатах поиска Google. Если вы не хотите, чтобы какие-либо страницы с вашего сайта были представлены в Google, добавьте на них директиву noindex или сделайте их доступными только по паролю.
Для чего служит файл robots.txt
Файл robots.txt используется прежде всего для управления трафиком поисковых роботов на вашем сайте. Как правило, с его помощью также можно исключить контент из результатов поиска Google (это зависит от типа контента).
| Как директивы из файла robots.txt обрабатываются при сканировании файлов разного типа | |
|---|---|
| Веб-страница | |