Что такое фабрика данных Azure?
применимо к:  Azure синапсе Analytics фабрика данных Azure
Azure синапсе Analytics фабрика данных Azure 
В мире больших данных в реляционных, нереляционных и других системах хранения часто хранятся необработанные и неорганизованные данные. Но необработанные данные сами по себе не содержат нужного контекста или значения, чтобы быть полезными для аналитиков, специалистов по анализу данных и руководителей компаний.
Для работы с большими данными нужна служба, которая поддерживает процессы организации и подготовки к использованию, для анализа этих огромных объемов необработанных данных и преобразования их в полезные данные. Фабрика данных Azure — это управляемая облачная служба, созданная для сложных гибридных процессов извлечения, преобразования и загрузки (или извлечения, загрузки и преобразования) и интеграции данных.
В качестве примера рассмотрим компанию, которая создает облачные игры и собирает петабайты информации в виде журналов этих игр. Компания хочет проанализировать эти журналы, чтобы получить сведения о предпочтениях клиентов, демографических параметрах и особенностях использования. Эти сведения помогут понять, как можно увеличить дополнительные и перекрестные продажи, разработать новые интересные функции, стимулировать развитие компании и улучшить качество обслуживания клиентов.
Чтобы проанализировать эти журналы, компании необходимо использовать справочные сведения, например информацию о клиентах, игре и маркетинговых действиях, которые хранятся в локальном хранилище данных. Компании нужно объединить эти данные из локального хранилища данных с дополнительными данными журналов, собранными в облачном хранилище данных.
Чтобы получить аналитические данные, компания обработает объединенные данные с помощью кластера Spark в облаке (Azure HDInsight), а затем опубликует преобразованные данные в облачное хранилище данных, например Azure Synapse Analytics, из которого можно будет легко получать нужные отчеты. Этот рабочий процесс должен выполняться автоматически при помещении файлов в контейнер хранилища больших двоичных объектов и должен ежедневно отслеживаться. Кроме того, должно быть налажено ежедневное управление им.
Фабрика данных Azure является идеальной платформой для таких сценариев обработки данных. Это облачная служба извлечения, преобразования, загрузки и интеграции данных, которая позволяет создавать управляемые данными рабочие процессы для оркестрации и автоматизации масштабных операций перемещения и преобразования данных. С помощью фабрики данных Azure можно создавать и включать в расписание управляемые данными рабочие процессы (конвейеры), которые могут принимать данные из разнородных хранилищ данных, Вы можете создавать сложные процессы извлечения, преобразования и загрузки, которые преобразуют данные через визуальный интерфейс потоков данных или служб вычислений, таких как Azure HDInsight Hadoop, Azure Databricks и База данных SQL Azure.
Кроме того, вы можете публиковать преобразованные данные в хранилищах данных (например, Azure Synapse Analytics) для использования приложениями бизнес-аналитики. Необработанные данные с помощью фабрики данных Azure можно организовать в полезные хранилища данных и озера данных для принятия лучших деловых решений.

Как это работает?
Фабрика данных содержит серию взаимосвязанных систем, которые предоставляют комплексную платформу для специалистов по инжинирингу данных.
Данное наглядное руководство обеспечивает общий обзор архитектуры Фабрики данных:
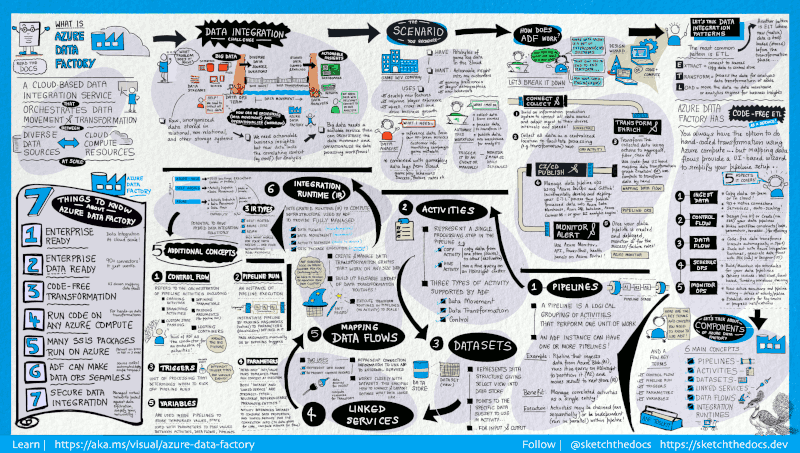
Чтобы увидеть более подробную информацию, щелкните предыдущее изображение, чтобы увеличить, или перейдите к изображению с высоким разрешением.
Подключение и сбор данных
Предприятия собирают данные различных типов в разнородных локальных и облачных источниках данных. Структурированные, неструктурированные или частично структурированные данные поступают с разными интервалами и с разной скоростью.
Первым этапом в создании системы производства информации является подключение ко всем необходимым источникам данных и службам обработки, таким как службы SaaS (программное обеспечение как услуга), базы данных, файловые ресурсы с общим доступом, FTP и веб-службы, и перемещение данных, нуждающихся в последующей обработке, в централизованное расположение.
Не имея фабрики данных предприятия вынуждены создавать компоненты для перемещения пользовательских данных или писать пользовательские службы для интеграции этих источников данных и обработки. Такие системы дорого стоят, их сложно интегрировать и обслуживать. Кроме того, они часто не включают функции мониторинга и оповещений корпоративного уровня, а также элементы управления, которые может предложить полностью управляемая служба.
В фабрике данных вы можете использовать действие копирования в конвейере данных для перемещения данных из локальных и облачных исходных хранилищ данных в централизованное хранилище данных в облаке для последующего анализа. Например, вы можете собирать данные в Azure Data Lake Storage и затем преобразовывать эти данные с помощью службы вычислений Azure Data Lake Analytics. Или же вы можете собрать данные в хранилище BLOB-объектов Azure и позже преобразовать их с помощью кластера Hadoop под управлением службы Azure HDInsight.
Преобразование и дополнение данных
Обрабатывайте или преобразовывайте данные, собранные в централизованном облачном хранилище, с помощью потоков сопоставления данных ADF. Потоки данных позволяют специалистам по обработке данных создавать и обслуживать схемы преобразования данных, которые выполняются в Spark, даже без знаний о кластерах Spark и программировании Spark.
Если вы предпочитаете вручную писать код преобразований, воспользуйтесь поддерживаемыми в ADF внешними действиями для преобразований в таких службах вычислений, как HDInsight Hadoop, Spark, Data Lake Analytics и Машинное обучение.
CI/CD и публикация
Фабрика данных обеспечивает полную поддержку CI/CD для конвейеров данных при использовании Azure DevOps и GitHub. Это позволяет постепенно разрабатывать и предоставлять процессы извлечения, преобразования и загрузки перед публикацией готового продукта. Когда необработанные данные преобразованы в готовую к использованию форму, вы можете передать данные в хранилище данных Azure, Базу данных SQL Azure, Azure Cosmos DB или в любую аналитическую платформу, которую могут выбрать бизнес-пользователи для своих средств бизнес-аналитики.
Монитор
После создания и развертывания конвейера интеграции данных, который извлекает полезные данные из обработанных данных, вам понадобится отслеживать успешное выполнение и сбои запланированных операций и конвейеров. Фабрика данных Azure имеет встроенную поддержку мониторинга конвейеров с помощью Azure Monitor, API, PowerShell, журналов Azure Monitor и панелей работоспособности на портале Azure.
Основные понятия
В подписке Azure может быть один или несколько экземпляров фабрики данных Azure. Фабрика данных Azure состоит из следующих основных компонентов.
Они образуют платформу, на которой можно создавать управляемые данными рабочие процессы, предусматривающие перемещение и преобразование данных.
Pipeline
В фабрике данных можно использовать один или несколько конвейеров. Конвейер — это логическая группа действий, которые выполняют определенный блок задач. Действия в конвейере совместно выполняют задачу. Например, конвейер может включать группу действий, которые принимают данные из большого двоичного объекта Azure и выполняют запрос Hive в кластере HDInsight для секционирования данных.
Преимущество конвейера в том, что он позволяет управлять группами действий, а не каждым отдельным действием. Действия в конвейере можно связывать друг с другом последовательно или выполнять параллельно и независимо друг от друга.
Сопоставление потоков данных
Создавайте и администрируйте графов логики преобразования данных, с помощью которых можно преобразовывать данные любого размера. Вы можете повторно создать используемую библиотеку подпрограмм преобразования данных и выполнять эти процессы из конвейеров ADF с поддержкой горизонтального масштабирования. Фабрика данных будет выполнять логику в кластере Spark, который увеличивается и уменьшается по мере необходимости. Вам не придется ни управлять кластерами, ни обслуживать их.
Действие
Действия представляют отдельные этапы обработки в конвейере. Например, действие копирования может использоваться для копирования данных из одного хранилища данных в другое. Точно так же можно использовать действие Hive, которое выполняет запрос Hive к кластеру Azure HDInsight, для преобразования или анализа данных. Фабрика данных поддерживает три типа действий: действия перемещения данных, действия преобразования данных и действия управления.
Наборы данных
Наборы данных представляют структуры данных в хранилищах. Эти структуры указывают данные, необходимые для использования в действиях, разделяя их на входные и выходные.
Связанные службы
Связанные службы напоминают строки подключения, определяющие сведения о подключении, необходимые для подключения фабрики данных к внешним ресурсам. Таким образом, набор данных представляет структуру данных, а связанная служба определяет подключение к источнику данных. Например, связанная служба хранилища Azure определяет строку подключения для подключения к учетной записи хранения Azure. Кроме того, набор данных больших двоичных объектов Azure определяет контейнер больших двоичных объектов и папку, которая содержит данные.
Связанные службы используются в фабрике данных для двух целей:
Для представления хранилища данных, включая, помимо прочего, базу данных SQL Server, базу данных Oracle, общую папку и учетную запись хранилища BLOB-объектов Azure. Список поддерживаемых хранилищ см. в статье о действии копирования.
Для представления вычислительного ресурса, в котором можно выполнить действие. Например, действие HDInsightHive выполняется в кластере Hadoop в HDInsight. Список поддерживаемых действий преобразования и вычислительных сред см. в статье о преобразовании данных.
Integration Runtime
В фабрике данных действия определяют выполняемые операции. Связанная служба обозначает целевое хранилище данных или службу вычислений. Среда выполнения интеграции соединяет между собой действия и связанные службы. На нее ссылаются связанные с ней службы или действия, а кроме того она предоставляет вычислительную среду, в которой действие выполняется или из которой оно диспетчеризируется. Такая схема позволяет выполнять действия в регионе, который максимально близко расположен к целевому хранилищу данных или службе вычислений, обеспечивает высокую производительность и соблюдение требований по безопасности и соответствию.
Триггеры
Триггеры обозначают единицу обработки, которая определяет время запуска для выполнения конвейера. Существует несколько типов триггеров для разных событий.
Запуски конвейера
Запуск конвейера — это экземпляр выполнения конвейера. Запуск конвейера обычно создается путем передачи аргументов для параметров, определенных в конвейерах. Аргументы можно передавать вручную или в определении триггера.
Параметры
Параметры представляют собой пары «ключ — значение» в конфигурации только для чтения. Параметры определяются в конвейере, а аргументы для них передаются во время выполнения из контекста запуска, созданного триггером, или из конвейера, который выполняется вручную. Действия в конвейере используют значения параметров.
Набор данных — это строго типизированный параметр и сущность, доступная для ссылок и повторного использования. Действие может ссылаться на наборы данных и может использовать параметры, определенные в определении набора данных.
Связанная служба также является строго типизированным параметром, который содержит сведения о подключении к хранилищу данных или среде вычислений. Служба также доступна для ссылок и (или) повторного использования.
Поток управления
Поток управления — это оркестрация действий в конвейере, которая включает цепочки действий в последовательности, ветвление, определение параметров на уровне конвейера и передачу аргументов во время вызова конвейера по запросу или из триггера. Кроме того, сюда входит передача пользовательского состояния и контейнеров зацикливания (то есть итераторы For-each).
Переменные
Переменные можно использовать внутри конвейеров для хранения временных значений, а также в сочетании с параметрами для передачи значений между конвейерами, потоками данных и другими действиями.
Дальнейшие действия
Вот несколько важных документов, которые следует изучить на следующем этапе:
Data Fabric (ткань данных)
Понятие Data Fabric и основные элементы этой концепции
Введение в понятие Data Fabric для TAdviser подготовила Светлана Вронская, автор телеграм-канала Analytics Now.
Data Fabric, которую почему-то часто неправильно переводят как «фабрику данных», никакого отношения к заводу не имеет. Data Fabric – это ткань данных, и представляет она собой цельную архитектуру управления информацией с полным и гибким доступом для работы с ней.
Это автономная экосистема, которая используется для максимально эффективного доступа к корпоративным данным. При помощи Data Fabric информацию легче искать, обрабатывать, структурировать и интегрировать с другими информационными системами.
Архитектура Data Fabric работает в концепции DataOps. Быстро организуется реагирование на любые изменения в данных, повышается уровень прогнозирования, оптимизируются процессы хранения, обработки и обслуживания ресурсов.
Отличительная характеристика Data Fabric – это активное применение технологий Больших данных и искусственного интеллекта, в частности, машинного обучения для построения и оптимизации алгоритмов управления и практического использования данных. Кроме того, концепция Data Fabric дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей.
Говоря просто, ткань данных – это система на уровне всей вашей организации, где всё подчиненно данным и выводам на их основе.
Data Fabric
Предоставление пользователям необходимых им данных ускоряет внедрение инноваций
Что такое Data Fabric?
Data Fabric — это архитектура управления данными, позволяющая оптимизировать доступ к разрозненным данным и интеллектуально организовать и согласовать их для доставки потребителям в режиме самообслуживания. Data Fabric помогает использовать корпоративные данные с большей эффективностью, по первому требованию предоставляя пользователям доступ к необходимой информации независимо от ее местонахождения. В Data Fabric изначально включены базовые средства управления данными; она не зависит от платформ развертывания, процессов обработки данных, способов использования данных, географических расположений и архитектурного подхода. Доставка данных, уже готовых к применению аналитики и ИИ обеспечивается как благодаря автоматизированному обнаружению, так и благодаря использованию данных и управлению ими.
Зачем нужна Data Fabric? Все преуспевающие предприятия управляют большими объемами данных. Многочисленные источники и множество типов данных. Сложности с интеграцией данных. Исследование показывает, что в большинстве организаций до 74% данных не анализируется, и до 82% предприятий страдают из-за разрозненности своих данных².
При наличии Data Fabric ваши пользователи и аналитики смогут быстрее получить доступ к достоверным данным для приложений, аналитических задач, ИИ, моделей машинного обучения и автоматизации бизнес-процессов. Это не только улучшит качество принимаемых ими решений, но и ускорит цифровую трансформацию. Техническим специалистам Data Fabric помогает не только существенно упростить управление данными и их регулирование в сложных гибридных и мультиоблачных средах, но и заметно сократить расходы и снизить риск.
Знакомство с Фабрикой данных Azure
В этой статье рассматривается служба «Фабрика данных Azure» версии 1. Если вы используете текущую версию службы «Фабрика данных», см. руководство по службе «Фабрика данных Azure» версии 2.
Что такое фабрика данных Azure?
Как имеющиеся большие данные используются в бизнес-среде? Возможно ли расширить облачные данные за счет ссылочных данных из локальных источников данных или других разрозненных источников данных?
Например, компания-разработчик игр собирает журналы, создаваемые играми в облаке. Она хочет проанализировать эти журналы, чтобы получить сведения о предпочтениях клиентов, демографических параметрах, особенностях использования и т. д. Эти сведения помогут понять, как можно увеличить дополнительные и перекрестные продажи, разработать новые интересные функции, стимулировать развитие компании и улучшить качество обслуживания клиентов.
Чтобы проанализировать эти журналы, компании необходимо использовать справочные сведения, например информацию о клиентах, игре и маркетинговых действиях, которые хранятся в локальном хранилище данных. Таким образом компания хочет получить данные журнала из облачного хранилища данных, а справочные сведения — из локального хранилища данных.
Далее нужно обработать данные с помощью Hadoop в облаке (Azure HDInsight). Данные результатов нужно опубликовать в облачном хранилище данных, например Azure Synapse Analytics, или локальном хранилище данных, например SQL Server. И такой рабочий процесс должен выполняться еженедельно.
Для этого нужна платформа, которая позволит компании создать рабочий процесс для приема данных из локального и облачного хранилищ данных, преобразовать или обработать эти данные с помощью существующих служб вычислений (например, Hadoop) и опубликовать результаты в локальное или облачное хранилище данных для использования приложениями бизнес-аналитики.

Фабрика данных Azure — это платформа для таких сценариев. Это облачная служба интеграции данных, которая позволяет создавать управляемые данными рабочие процессы в облаке для оркестрации и автоматизации перемещения и преобразования данных. Используя фабрику данных Azure, можно выполнять следующие задачи:
создавать и включать в расписание управляемые данными рабочие процессы (конвейеры), которые могут принимать данные из разнородных хранилищ данных;
обрабатывать или преобразовывать эти данные с помощью служб вычислений (например, Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics и машинного обучения Azure);
публиковать выходные данные в хранилища данных (например, Azure Synapse Analytics) для использования приложениями бизнес-аналитики.
В отличие от традиционных платформ для последовательного извлечения, преобразования и загрузки данных эта платформа предусматривает два этапа обработки: извлечение и загрузка, за которыми следуют преобразование и загрузка. При преобразовании данные обрабатываются с помощью служб вычислений, а не путем добавления производных столбцов, подсчета количества строк, сортировки данных и так далее.
Сейчас в фабрике данных Azure данные, полученные и созданные рабочими процессами, представляют временные срезы, то есть они могут обрабатываться ежечасно, ежедневно, еженедельно и т. д. Например, конвейер может считывать входные данные, обрабатывать данные и генерировать выходные данные один раз в день. Рабочий процесс также можно запускать однократно.
Как это работает?
Конвейеры (управляемые данными рабочие процессы) в фабрике Azure данных обычно выполняют следующие действия.

Подключение и сбор данных
Предприятия работают с данными разных типов, хранимыми в разных источниках. Первым этапом в создании системы производства информации является подключение ко всем необходимым источникам данных и службам обработки, таким как службы SaaS, файловые ресурсы с общим доступом, FTP и веб-службы, и перемещение данных, необходимых для последующей обработки, в централизованное расположение.
Не имея фабрики данных предприятия вынуждены создавать компоненты для перемещения пользовательских данных или писать пользовательские службы для интеграции этих источников данных и обработки. Такие системы дорого стоят, их сложно интегрировать и обслуживать. Кроме того, они часто не включают функции мониторинга и оповещений корпоративного уровня, а также элементы управления, которые может предложить полностью управляемая служба.
С помощью фабрики данных вы можете использовать действие копирования в конвейере данных, чтобы переместить данные из локальных и облачных исходных хранилищ данных в централизованное хранилище данных в облаке для последующего анализа.
Например, вы можете собрать данные в Azure Data Lake Store и позже преобразовать эти данные с помощью службы вычислений Azure Data Lake Analytics. Или же вы можете собрать данные в хранилище BLOB-объектов Azure и позже преобразовать их с помощью кластера Hadoop под управлением службы Azure HDInsight.
Преобразование и дополнение данных
Обработайте или передайте данные, собранные в централизованном облачном хранилище данных, с помощью служб вычислений, например HDInsight Hadoop, Spark, Data Lake Analytics или машинного обучения. Также необходимо надежно преобразовывать данные по определенному расписанию (поддерживаемому и управляемому) для насыщения рабочих сред доверенными данными.
Публикация
Преобразованные данные можно передавать из облака в локальные источники (например, SQL Server) Кроме того, не заключайте его в облачные источники хранилища для использования средствами бизнес-аналитики и аналитиками и другими приложениями.
Ключевые компоненты
В подписке Azure может быть один или несколько экземпляров фабрики данных Azure. Фабрика данных Azure состоит из четырех основных компонентов. Они образуют платформу, на которой можно создавать управляемые данными рабочие процессы, предусматривающие перемещение и преобразование данных.
Pipeline
Фабрика данных может иметь один или несколько конвейеров. Конвейер представляет собой группу действий. Действия в конвейере совместно выполняют задачу.
Например, конвейер может включать группу действий, которые принимают данные из большого двоичного объекта Azure и выполняют запрос Hive в кластере HDInsight для секционирования данных. Преимуществом является то, что конвейер позволяет управлять группами действий, а не каждым отдельным действием. Например, вы можете развернуть конвейер и запланировать его работу, а не планировать действия отдельно.
Действие
Конвейер может содержать одно или несколько действий. Действия определяют то, что нужно выполнить с вашими данными. Например, действие копирования может использоваться для копирования данных из одного хранилища данных в другое. Точно так же можно использовать действие Hive, которое выполняет запрос Hive к кластеру Azure HDInsight для преобразования или анализа данных. Фабрика данных поддерживает два типа действий: действия перемещения данных и действия преобразования данных.
Действия перемещения данных
Действие копирования в фабрике данных копирует данные из хранилища-источника в хранилище-приемник. Данные из любого источника можно записывать в любой приемник. Выделите название хранилища, чтобы узнать, как скопировать данные из него или в него. Фабрика данных поддерживает приведенные ниже хранилища данных:
| Категория | Хранилище данных | Поддерживается в качестве источника | Поддерживается в качестве приемника |
|---|---|---|---|
| Azure | Хранилище BLOB-объектов Azure | ✓ | ✓ |
| Azure Cosmos DB (SQL API) | ✓ | ✓ | |
| Azure Data Lake Storage 1-го поколения | ✓ | ✓ | |
| База данных SQL Azure | ✓ | ✓ | |
| Azure Synapse Analytics | ✓ | ✓ | |
| Индекс Когнитивного поиска Azure | ✓ | ||
| Хранилище таблиц Azure | ✓ | ✓ | |
| Базы данных | Amazon Redshift | ✓ | |
| DB2 | ✓ | ||
| MySQL | ✓ | ||
| СУБД | ✓ | ✓ | |
| PostgreSQL | ✓ | ||
| SAP Business Warehouse | ✓ | ||
| SAP HANA | ✓ | ||
| SQL Server | ✓ | ✓ | |
| Sybase | ✓ | ||
| Teradata | ✓ | ||
| NoSQL | Cassandra | ✓ | |
| MongoDB | ✓ | ||
| Файл | Amazon S3 | ✓ | |
| Файловая система | ✓ | ✓ | |
| FTP | ✓ | ||
| HDFS | ✓ | ||
| SFTP | ✓ | ||
| Прочие | Базовый протокол HTTP | ✓ | |
| Базовый протокол OData | ✓ | ||
| Универсальный ODBC | ✓ | ||
| Salesforce | ✓ | ||
| Веб-таблица (таблица на основе HTML) | ✓ |
Действия преобразования данных
Фабрика данных Azure поддерживает указанные ниже действия преобразования, которые вы можете добавлять в конвейеры как по отдельности, так и в связи с другим действием.
| Действия по преобразованию данных | Вычислительная среда |
|---|---|
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Потоковая передача Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Действия Студии машинного обучения Azure (классическая версия): пакетное выполнение и обновление ресурса | Azure |
| Хранимая процедура | Azure SQL, Azure Synapse Analytics или SQL Server |
| Аналитика озера данных U-SQL | Аналитика озера данных Azure |
| DotNet | HDInsight [Hadoop] или пакетная служба Azure |
Действие MapReduce можно использовать для запуска программ Spark в кластере HDInsight Spark. Дополнительные сведения см. в разделе Вызов программ Spark из фабрики данных. Можно создать настраиваемое действие для выполнения сценариев R в кластере HDInsight, где установлена среда R. Ознакомьтесь с примером в репозитории GitHub Run R Script using Azure Data Factory (Запуск сценария R с помощью фабрики данных Azure).
Наборы данных
Каждое действие принимает некоторое число наборов данных на входе и создает один или несколько наборов данных на выходе. Наборы данных представляют структуры данных в хранилищах данных. Эти структуры указывают или ссылаются на данные, которые нужно использовать в действиях (например, входные и выходные данные).
Например, набор данных больших двоичных объектов Azure указывает контейнер больших двоичных объектов и папку в хранилище BLOB-объектов, из которой конвейер должен считывать данные. Или же набор таблиц SQL Azure указывает таблицу, в которую с помощью действия записываются выходные данные.
Связанные службы
Связанные службы напоминают строки подключения, определяющие сведения о подключении, необходимые для подключения фабрики данных к внешним ресурсам. Таким образом, набор данных представляет структуру данных, а связанная служба определяет подключение к источнику данных.
Например, связанная служба хранилища Azure определяет строку подключения для подключения к учетной записи хранения Azure. А набор данных больших двоичных объектов Azure определяет контейнер больших двоичных объектов и папку, которая содержит данные.
Связанные службы используются в фабрике данных для двух целей:
Для представления хранилища данных, включая, помимо прочего, базу данных SQL Server, базу данных Oracle, общую папку и учетную запись хранилища BLOB-объектов Azure. Список поддерживаемых хранилищ данных см. в статье Перемещение данных с помощью действия копирования.
Для представления вычислительного ресурса, в котором можно выполнить действие. Например, действие HDInsightHive выполняется в кластере Hadoop в HDInsight. Список поддерживаемых вычислительных сред см. в разделе Действия преобразования данных.
Связь между сущностями фабрики данных

Поддерживаемые регионы
Сейчас фабрики данных можно создавать в таких регионах: западная часть США, восточная часть США и Северная Европа. Однако для перемещения данных между хранилищами данных или для обработки данных с помощью служб вычислений фабрики данных могут обращаться к хранилищам данных и службам вычислений в других регионах Azure.
В самой фабрике данных Azure данные не хранятся. Она позволяет создавать рабочие процессы на основе данных в облаке, чтобы выполнять оркестрацию для перемещения данных между поддерживаемыми хранилищами данных, а также обрабатывать данные с помощью служб вычислений в других регионах или в локальной среде. Кроме того, с помощью фабрики данных можно отслеживать рабочие процессы и управлять ими, используя программные методы и пользовательский интерфейс.
Фабрика данных Azure доступна только в западной части США, восточной части США и Северной Европе. Служба фабрики данных для поддержки перемещения данных доступна глобально в нескольких регионах. Если хранилище данных находится за брандмауэром, данные перемещает шлюз управления данными, установленный в локальной среде.
Предположим, ваши вычислительные среды, например кластер Azure HDInsight и служба «Машинное обучение Azure», расположены в Западной Европе. Вы можете создать экземпляр фабрики данных Azure в Северной Европе и с его помощью планировать задания в вычислительных средах в Западной Европе. Фабрике данных требуется лишь несколько миллисекунд, чтобы запустить задание в вычислительной среде, но время выполнения задания в вашей вычислительной среде остается неизменным.
Начало работы — создание конвейера
Для создания конвейеров данных в фабрике данных Azure можно использовать API-интерфейсы или одно из следующих средств:
Чтобы научиться создавать фабрики данных с конвейерами данных, выполните пошаговые инструкции из следующих руководств:



